 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Evaluation Protocols of Visual Representations Learned via Self-supervised Learning
Apr 07, 2023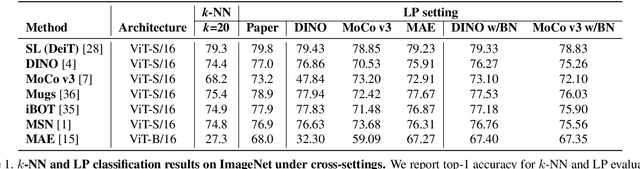
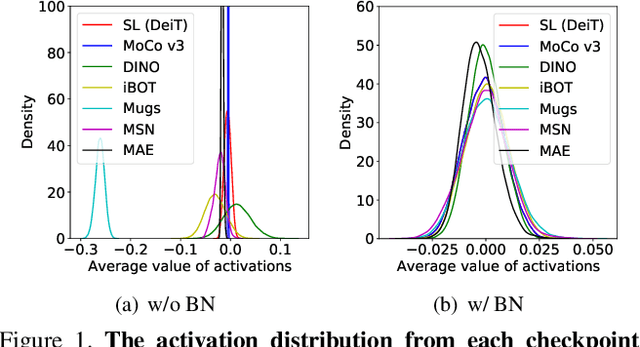
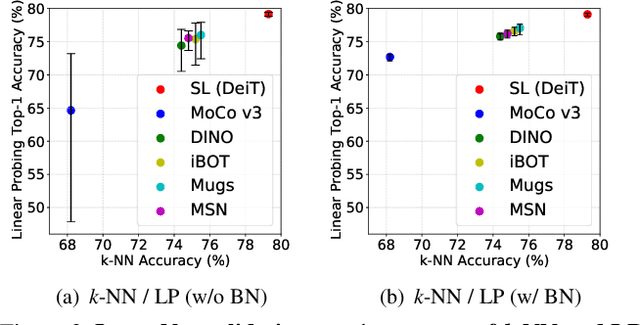

Linear probing (LP) (and $k$-NN) on the upstream dataset with labels (e.g., ImageNet) and transfer learning (TL) to various downstream datasets are commonly employed to evaluate the quality of visual representations learned via self-supervised learning (SSL). Although existing SSL methods have shown good performances under those evaluation protocols, we observe that the performances are very sensitive to the hyperparameters involved in LP and TL. We argue that this is an undesirable behavior since truly generic representations should be easily adapted to any other visual recognition task, i.e., the learned representations should be robust to the settings of LP and TL hyperparameters. In this work, we try to figure out the cause of performance sensitivity by conducting extensive experiments with state-of-the-art SSL methods. First, we find that input normalization for LP is crucial to eliminate performance variations according to the hyperparameters. Specifically, batch normalization before feeding inputs to a linear classifier considerably improves the stability of evaluation, and also resolves inconsistency of $k$-NN and LP metrics. Second, for TL, we demonstrate that a weight decay parameter in SSL significantly affects the transferability of learned representations, which cannot be identified by LP or $k$-NN evaluations on the upstream dataset. We believe that the findings of this study will be beneficial for the community by drawing attention to the shortcomings in the current SSL evaluation schemes and underscoring the need to reconsider them.
Self-Knowledge Distillation: A Simple Way for Better Generalization
Jun 22, 2020



The generalization capability of deep neural networks has been substantially improved by applying a wide spectrum of regularization methods, e.g., restricting function space, injecting randomness during training, augmenting data, etc. In this work, we propose a simple yet effective regularization method named self-knowledge distillation (Self-KD), which progressively distills a model's own knowledge to soften hard targets (i.e., one-hot vectors) during training. Hence, it can be interpreted within a framework of knowledge distillation as a student becomes a teacher itself. The proposed method is applicable to any supervised learning tasks with hard targets and can be easily combined with existing regularization methods to further enhance the generalization performance. Furthermore, we show that Self-KD achieves not only better accuracy, but also provides high quality of confidence estimates. Extensive experimental results on three different tasks, image classification, object detection, and machine translation, demonstrate that our method consistently improves the performance of the state-of-the-art baselines, and especially, it achieves state-of-the-art BLEU score of 30.0 and 36.2 on IWSLT15 English-to-German and German-to-English tasks, respectively.