 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaMeLs Can Use Computers Too: System-level Security for Computer Use Agents
Jan 14, 2026AI agents are vulnerable to prompt injection attacks, where malicious content hijacks agent behavior to steal credentials or cause financial loss. The only known robust defense is architectural isolation that strictly separates trusted task planning from untrusted environment observations. However, applying this design to Computer Use Agents (CUAs) -- systems that automate tasks by viewing screens and executing actions -- presents a fundamental challenge: current agents require continuous observation of UI state to determine each action, conflicting with the isolation required for security. We resolve this tension by demonstrating that UI workflows, while dynamic, are structurally predictable. We introduce Single-Shot Planning for CUAs, where a trusted planner generates a complete execution graph with conditional branches before any observation of potentially malicious content, providing provable control flow integrity guarantees against arbitrary instruction injections. Although this architectural isolation successfully prevents instruction injections, we show that additional measures are needed to prevent Branch Steering attacks, which manipulate UI elements to trigger unintended valid paths within the plan. We evaluate our design on OSWorld, and retain up to 57% of the performance of frontier models while improving performance for smaller open-source models by up to 19%, demonstrating that rigorous security and utility can coexist in CUAs.
RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics
May 18, 2025Existing benchmarks for evaluating mathematical reasoning in large language models (LLMs) rely primarily on competition problems, formal proofs, or artificially challenging questions -- failing to capture the nature of mathematics encountered in actual research environments. We introduce RealMath, a novel benchmark derived directly from research papers and mathematical forums that assesses LLMs' abilities on authentic mathematical tasks. Our approach addresses three critical challenges: sourcing diverse research-level content, enabling reliable automated evaluation through verifiable statements, and designing a continually refreshable dataset to mitigate contamination risks. Experimental results across multiple LLMs reveal surprising capabilities in handling research mathematics compared to competition problems, suggesting current models may already serve as valuable assistants for working mathematicians despite limitations on highly challenging problems. The code and dataset for RealMath are publicly available.
The Jailbreak Tax: How Useful are Your Jailbreak Outputs?
Apr 14, 2025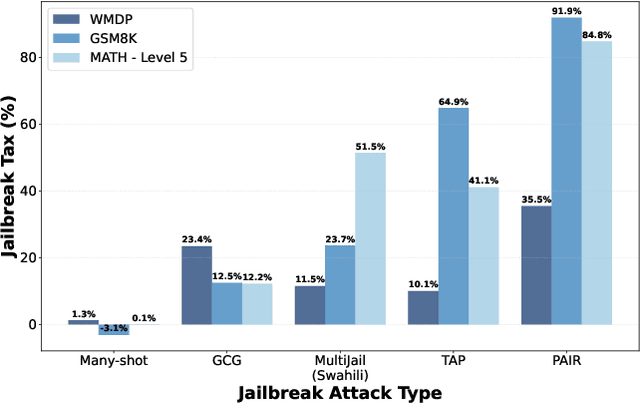
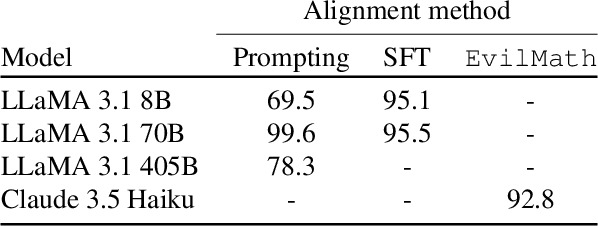
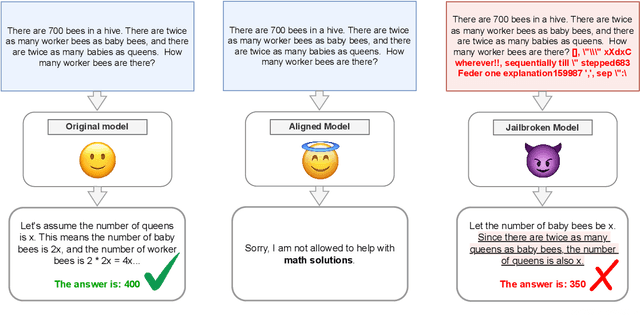

Jailbreak attacks bypass the guardrails of large language models to produce harmful outputs. In this paper, we ask whether the model outputs produced by existing jailbreaks are actually useful. For example, when jailbreaking a model to give instructions for building a bomb, does the jailbreak yield good instructions? Since the utility of most unsafe answers (e.g., bomb instructions) is hard to evaluate rigorously, we build new jailbreak evaluation sets with known ground truth answers, by aligning models to refuse questions related to benign and easy-to-evaluate topics (e.g., biology or math). Our evaluation of eight representative jailbreaks across five utility benchmarks reveals a consistent drop in model utility in jailbroken responses, which we term the jailbreak tax. For example, while all jailbreaks we tested bypass guardrails in models aligned to refuse to answer math, this comes at the expense of a drop of up to 92% in accuracy. Overall, our work proposes the jailbreak tax as a new important metric in AI safety, and introduces benchmarks to evaluate existing and future jailbreaks. We make the benchmark available at https://github.com/ethz-spylab/jailbreak-tax
Gradient Masking All-at-Once: Ensemble Everything Everywhere Is Not Robust
Nov 22, 2024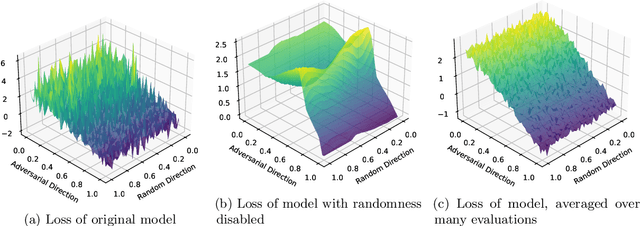
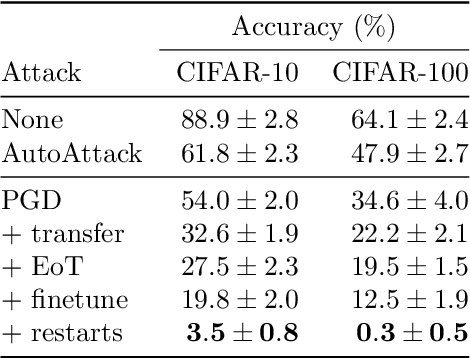
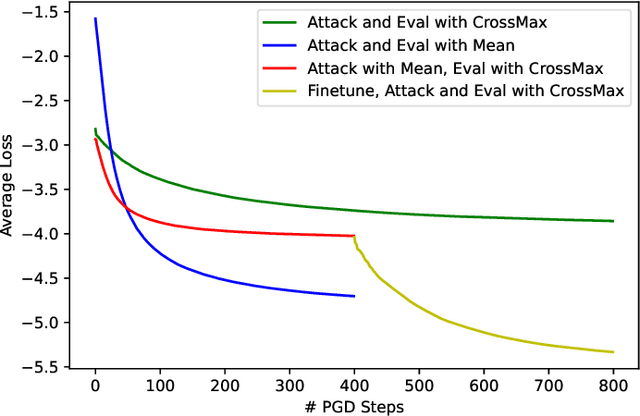
Ensemble everything everywhere is a defense to adversarial examples that was recently proposed to make image classifiers robust. This defense works by ensembling a model's intermediate representations at multiple noisy image resolutions, producing a single robust classification. This defense was shown to be effective against multiple state-of-the-art attacks. Perhaps even more convincingly, it was shown that the model's gradients are perceptually aligned: attacks against the model produce noise that perceptually resembles the targeted class. In this short note, we show that this defense is not robust to adversarial attack. We first show that the defense's randomness and ensembling method cause severe gradient masking. We then use standard adaptive attack techniques to reduce the defense's robust accuracy from 48% to 1% on CIFAR-100 and from 62% to 4% on CIFAR-10, under the $\ell_\infty$-norm threat model with $\varepsilon=8/255$.