 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA variational Bayes approach to debiased inference for low-dimensional parameters in high-dimensional linear regression
Jun 18, 2024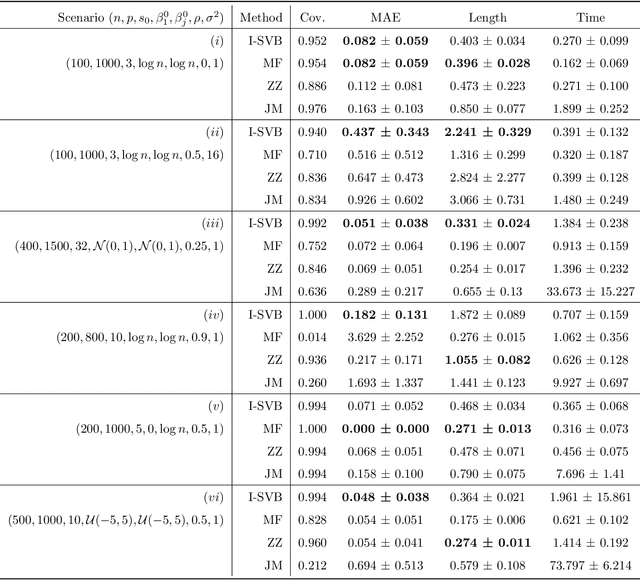
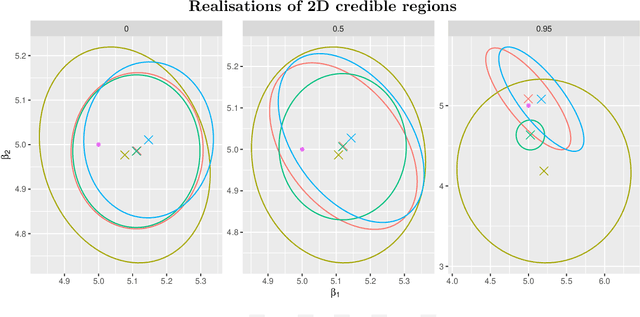
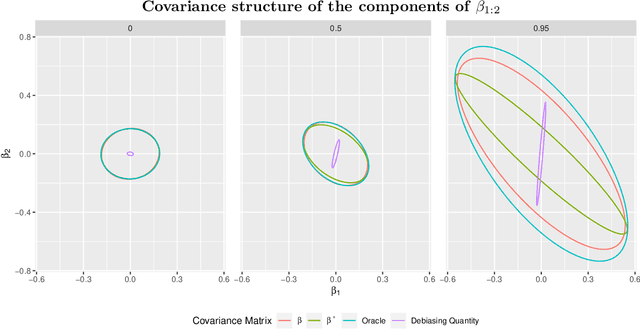
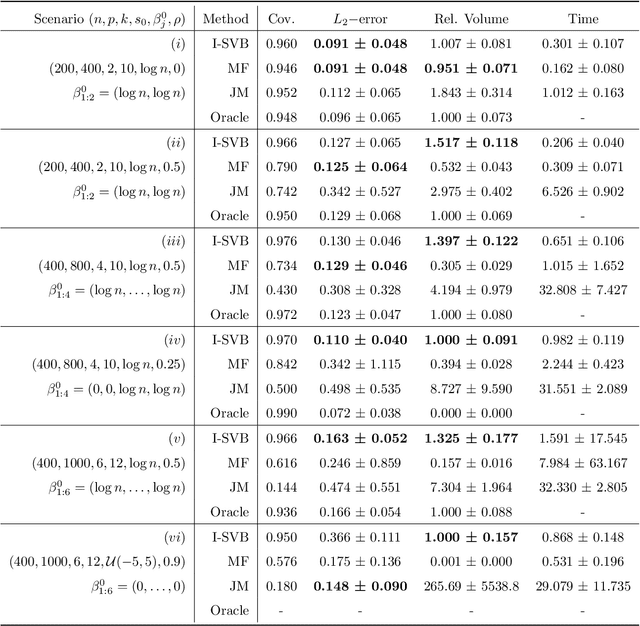
We propose a scalable variational Bayes method for statistical inference for a single or low-dimensional subset of the coordinates of a high-dimensional parameter in sparse linear regression. Our approach relies on assigning a mean-field approximation to the nuisance coordinates and carefully modelling the conditional distribution of the target given the nuisance. This requires only a preprocessing step and preserves the computational advantages of mean-field variational Bayes, while ensuring accurate and reliable inference for the target parameter, including for uncertainty quantification. We investigate the numerical performance of our algorithm, showing that it performs competitively with existing methods. We further establish accompanying theoretical guarantees for estimation and uncertainty quantification in the form of a Bernstein--von Mises theorem.
Pointwise uncertainty quantification for sparse variational Gaussian process regression with a Brownian motion prior
Oct 09, 2023We study pointwise estimation and uncertainty quantification for a sparse variational Gaussian process method with eigenvector inducing variables. For a rescaled Brownian motion prior, we derive theoretical guarantees and limitations for the frequentist size and coverage of pointwise credible sets. For sufficiently many inducing variables, we precisely characterize the asymptotic frequentist coverage, deducing when credible sets from this variational method are conservative and when overconfident/misleading. We numerically illustrate the applicability of our results and discuss connections with other common Gaussian process priors.
Semiparametric inference using fractional posteriors
Jan 19, 2023


We establish a general Bernstein--von Mises theorem for approximately linear semiparametric functionals of fractional posterior distributions based on nonparametric priors. This is illustrated in a number of nonparametric settings and for different classes of prior distributions, including Gaussian process priors. We show that fractional posterior credible sets can provide reliable semiparametric uncertainty quantification, but have inflated size. To remedy this, we further propose a \textit{shifted-and-rescaled} fractional posterior set that is an efficient confidence set having optimal size under regularity conditions. As part of our proofs, we also refine existing contraction rate results for fractional posteriors by sharpening the dependence of the rate on the fractional exponent.
On the inability of Gaussian process regression to optimally learn compositional functions
May 16, 2022We rigorously prove that deep Gaussian process priors can outperform Gaussian process priors if the target function has a compositional structure. To this end, we study information-theoretic lower bounds for posterior contraction rates for Gaussian process regression in a continuous regression model. We show that if the true function is a generalized additive function, then the posterior based on any mean-zero Gaussian process can only recover the truth at a rate that is strictly slower than the minimax rate by a factor that is polynomially suboptimal in the sample size $n$.
Variational Bayes for high-dimensional proportional hazards models with applications to gene expression variable selection
Dec 19, 2021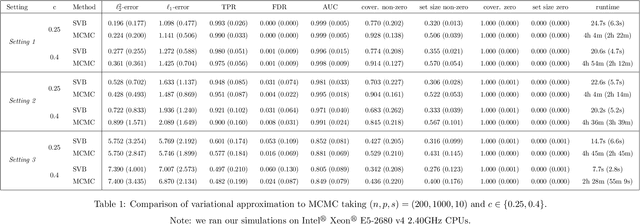
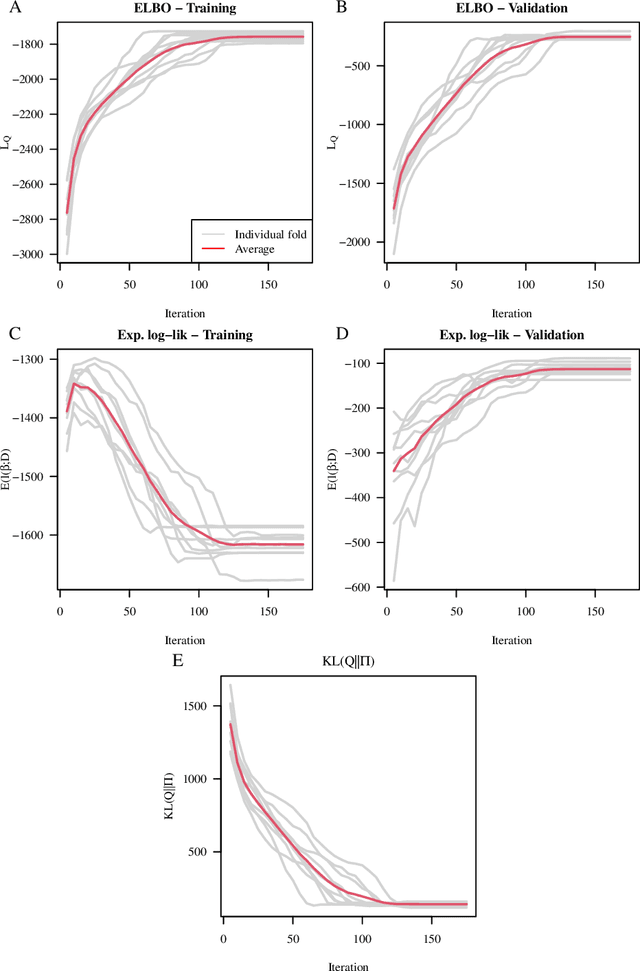
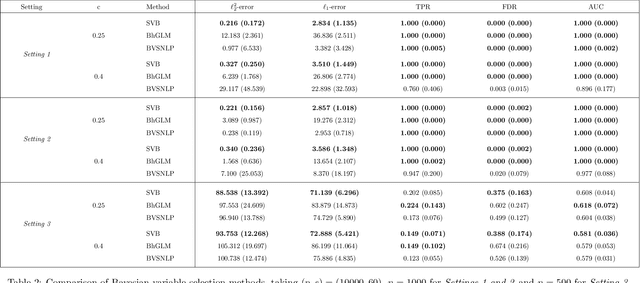
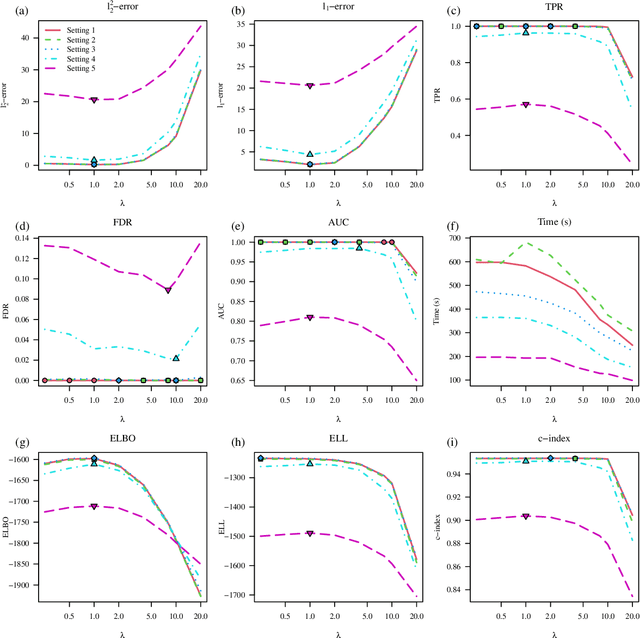
We propose a variational Bayesian proportional hazards model for prediction and variable selection regarding high-dimensional survival data. Our method, based on a mean-field variational approximation, overcomes the high computational cost of MCMC whilst retaining the useful features, providing excellent point estimates and offering a natural mechanism for variable selection via posterior inclusion probabilities. The performance of our proposed method is assessed via extensive simulations and compared against other state-of-the-art Bayesian variable selection methods, demonstrating comparable or better performance. Finally, we demonstrate how the proposed method can be used for variable selection on two transcriptomic datasets with censored survival outcomes, where we identify genes with pre-existing biological interpretations.
Spike and slab variational Bayes for high dimensional logistic regression
Oct 22, 2020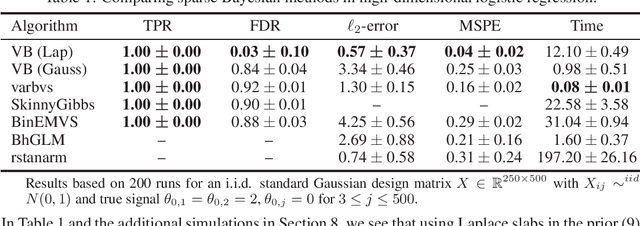

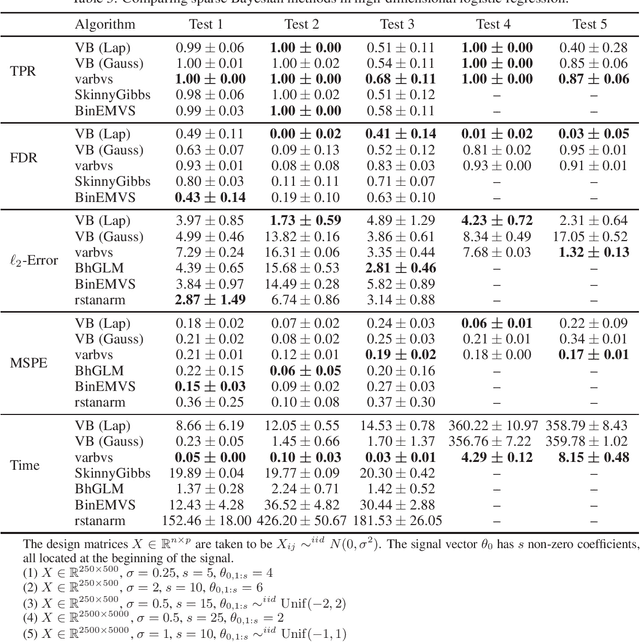

Variational Bayes (VB) is a popular scalable alternative to Markov chain Monte Carlo for Bayesian inference. We study a mean-field spike and slab VB approximation of widely used Bayesian model selection priors in sparse high-dimensional logistic regression. We provide non-asymptotic theoretical guarantees for the VB posterior in both $\ell_2$ and prediction loss for a sparse truth, giving optimal (minimax) convergence rates. Since the VB algorithm does not depend on the unknown truth to achieve optimality, our results shed light on effective prior choices. We confirm the improved performance of our VB algorithm over common sparse VB approaches in a numerical study.
Debiased Bayesian inference for average treatment effects
Sep 26, 2019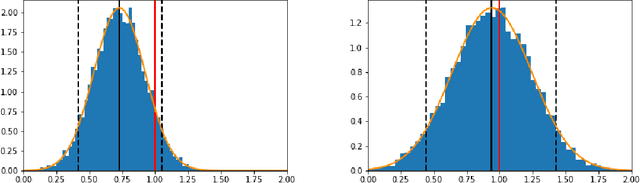
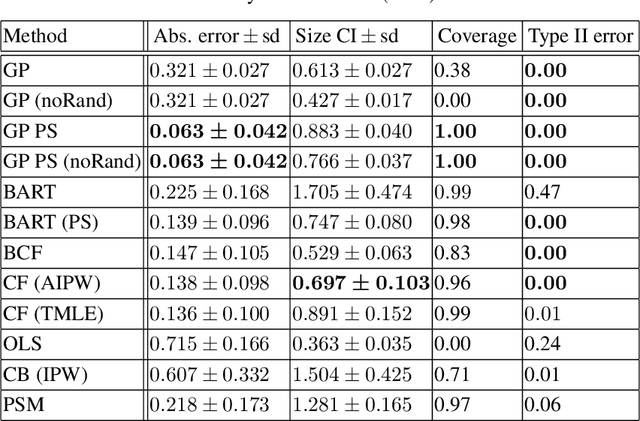
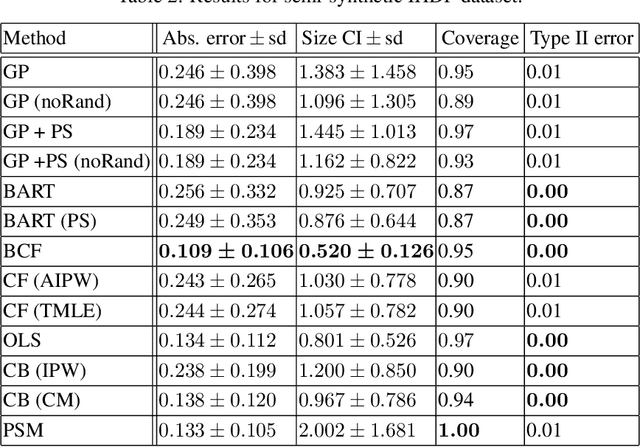
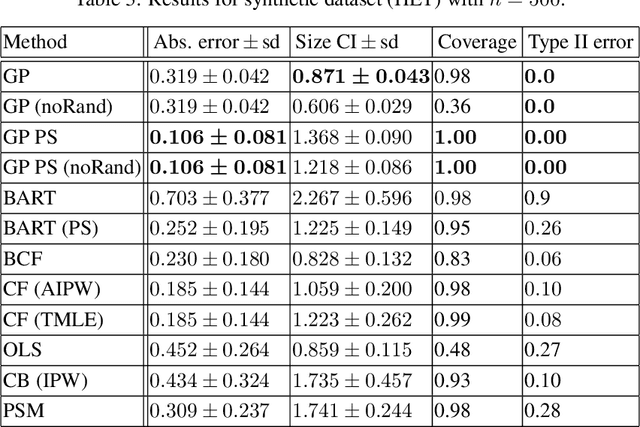
Bayesian approaches have become increasingly popular in causal inference problems due to their conceptual simplicity, excellent performance and in-built uncertainty quantification ('posterior credible sets'). We investigate Bayesian inference for average treatment effects from observational data, which is a challenging problem due to the missing counterfactuals and selection bias. Working in the standard potential outcomes framework, we propose a data-driven modification to an arbitrary (nonparametric) prior based on the propensity score that corrects for the first-order posterior bias, thereby improving performance. We illustrate our method for Gaussian process (GP) priors using (semi-)synthetic data. Our experiments demonstrate significant improvement in both estimation accuracy and uncertainty quantification compared to the unmodified GP, rendering our approach highly competitive with the state-of-the-art.