 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Methods for Estimating Conditional Shapley Values and When to Use Them
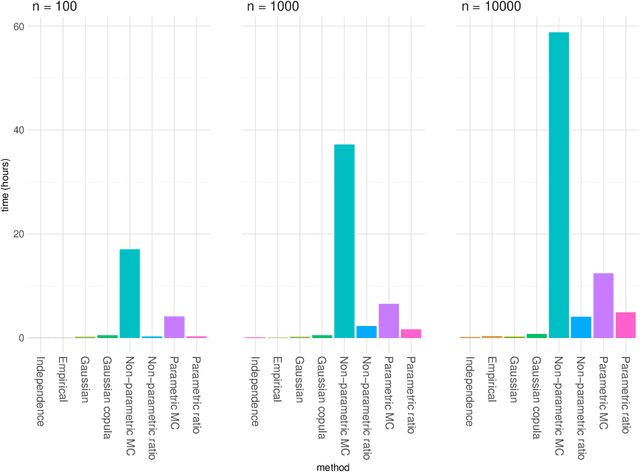
May 16, 2023Shapley values originated in cooperative game theory but are extensively used today as a model-agnostic explanation framework to explain predictions made by complex machine learning models in the industry and academia. There are several algorithmic approaches for computing different versions of Shapley value explanations. Here, we focus on conditional Shapley values for predictive models fitted to tabular data. Estimating precise conditional Shapley values is difficult as they require the estimation of non-trivial conditional expectations. In this article, we develop new methods, extend earlier proposed approaches, and systematize the new refined and existing methods into different method classes for comparison and evaluation. The method classes use either Monte Carlo integration or regression to model the conditional expectations. We conduct extensive simulation studies to evaluate how precisely the different method classes estimate the conditional expectations, and thereby the conditional Shapley values, for different setups. We also apply the methods to several real-world data experiments and provide recommendations for when to use the different method classes and approaches. Roughly speaking, we recommend using parametric methods when we can specify the data distribution almost correctly, as they generally produce the most accurate Shapley value explanations. When the distribution is unknown, both generative methods and regression models with a similar form as the underlying predictive model are good and stable options. Regression-based methods are often slow to train but produce the Shapley value explanations quickly once trained. The vice versa is true for Monte Carlo-based methods, making the different methods appropriate in different practical situations.
Using Shapley Values and Variational Autoencoders to Explain Predictive Models with Dependent Mixed Features
Nov 26, 2021
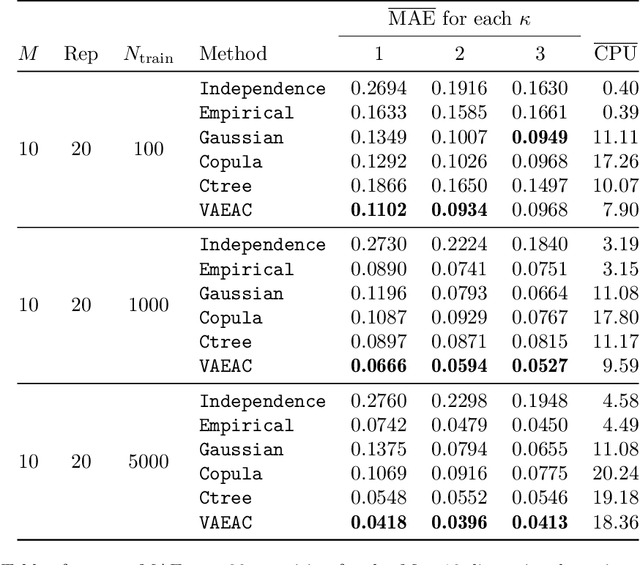

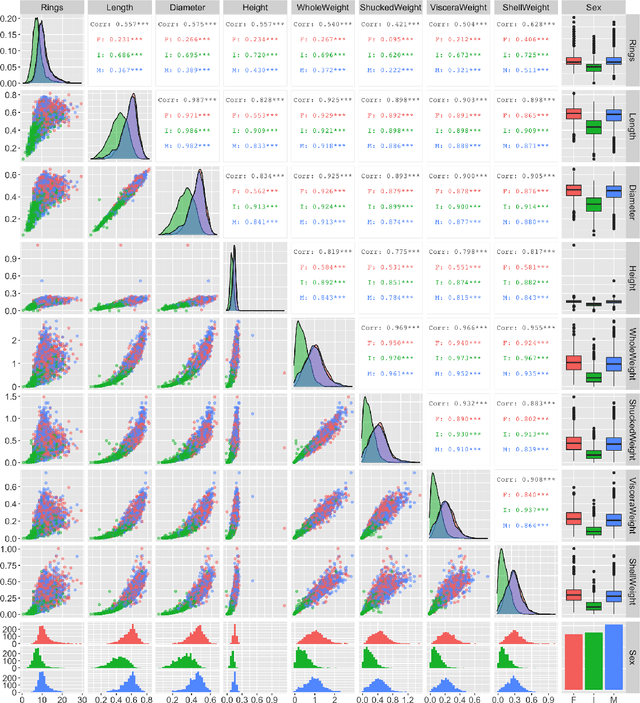
Shapley values are today extensively used as a model-agnostic explanation framework to explain complex predictive machine learning models. Shapley values have desirable theoretical properties and a sound mathematical foundation. Precise Shapley value estimates for dependent data rely on accurate modeling of the dependencies between all feature combinations. In this paper, we use a variational autoencoder with arbitrary conditioning (VAEAC) to model all feature dependencies simultaneously. We demonstrate through comprehensive simulation studies that VAEAC outperforms the state-of-the-art methods for a wide range of settings for both continuous and mixed dependent features. Finally, we apply VAEAC to the Abalone data set from the UCI Machine Learning Repository.
MCCE: Monte Carlo sampling of realistic counterfactual explanations
Nov 18, 2021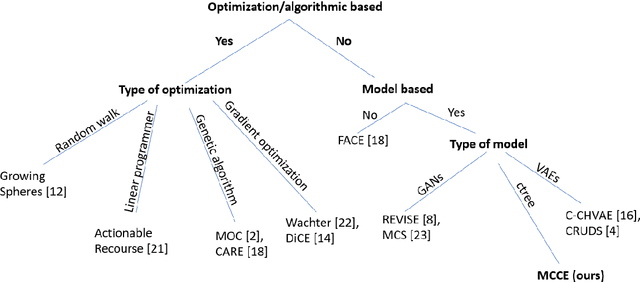


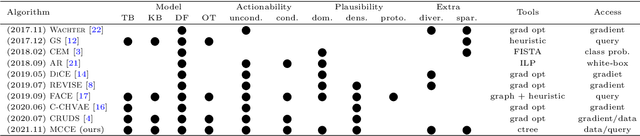
In this paper we introduce MCCE: Monte Carlo sampling of realistic Counterfactual Explanations, a model-based method that generates counterfactual explanations by producing a set of feasible examples using conditional inference trees. Unlike algorithmic-based counterfactual methods that have to solve complex optimization problems or other model based methods that model the data distribution using heavy machine learning models, MCCE is made up of only two light-weight steps (generation and post-processing). MCCE is also straightforward for the end user to understand and implement, handles any type of predictive model and type of feature, takes into account actionability constraints when generating the counterfactual explanations, and generates as many counterfactual explanations as needed. In this paper we introduce MCCE and give a comprehensive list of performance metrics that can be used to compare counterfactual explanations. We also compare MCCE with a range of state-of-the-art methods and a new baseline method on benchmark data sets. MCCE outperforms all model-based methods and most algorithmic-based methods when also taking into account validity (i.e., a correctly changed prediction) and actionability constraints. Finally, we show that MCCE has the strength of performing almost as well when given just a small subset of the training data.
Discriminative Multimodal Learning via Conditional Priors in Generative Models
Oct 09, 2021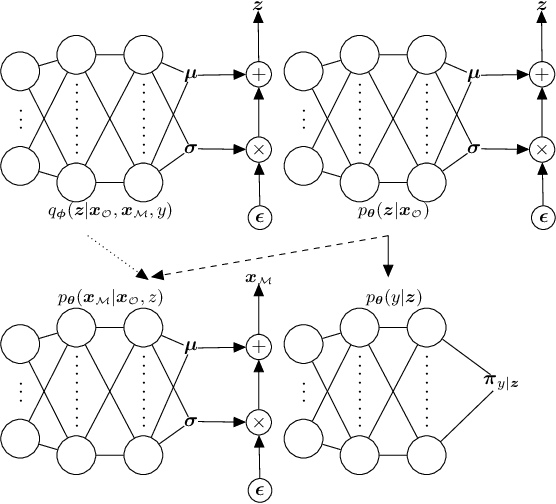
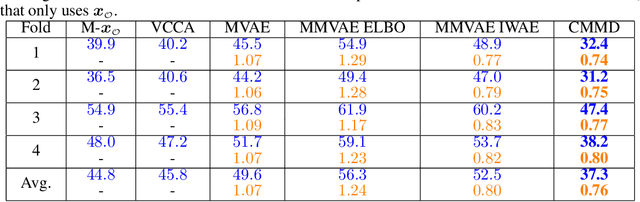
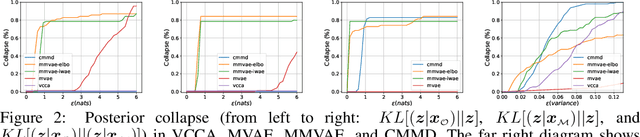
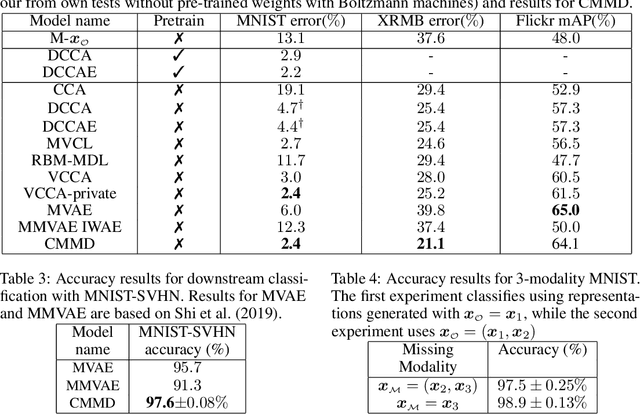
Deep generative models with latent variables have been used lately to learn joint representations and generative processes from multi-modal data. These two learning mechanisms can, however, conflict with each other and representations can fail to embed information on the data modalities. This research studies the realistic scenario in which all modalities and class labels are available for model training, but where some modalities and labels required for downstream tasks are missing. We show, in this scenario, that the variational lower bound limits mutual information between joint representations and missing modalities. We, to counteract these problems, introduce a novel conditional multi-modal discriminative model that uses an informative prior distribution and optimizes a likelihood-free objective function that maximizes mutual information between joint representations and missing modalities. Extensive experimentation shows the benefits of the model we propose, the empirical results showing that our model achieves state-of-the-art results in representative problems such as downstream classification, acoustic inversion and annotation generation.
groupShapley: Efficient prediction explanation with Shapley values for feature groups
Jun 23, 2021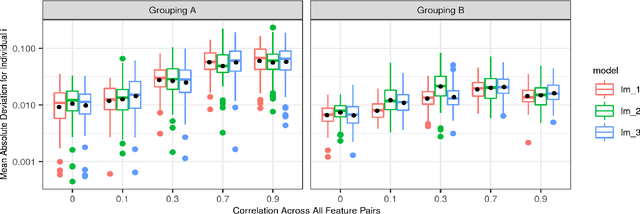


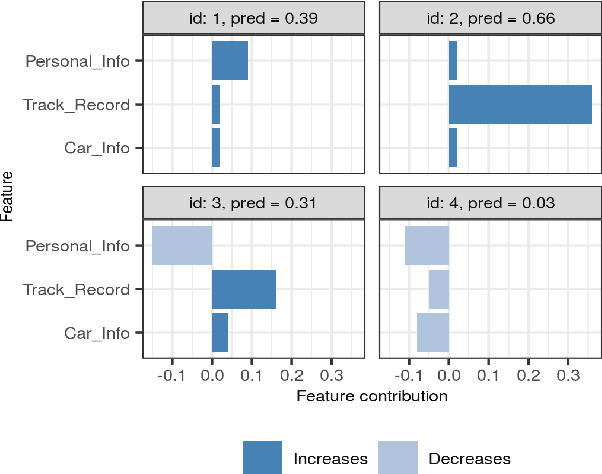
Shapley values has established itself as one of the most appropriate and theoretically sound frameworks for explaining predictions from complex machine learning models. The popularity of Shapley values in the explanation setting is probably due to its unique theoretical properties. The main drawback with Shapley values, however, is that its computational complexity grows exponentially in the number of input features, making it unfeasible in many real world situations where there could be hundreds or thousands of features. Furthermore, with many (dependent) features, presenting/visualizing and interpreting the computed Shapley values also becomes challenging. The present paper introduces groupShapley: a conceptually simple approach for dealing with the aforementioned bottlenecks. The idea is to group the features, for example by type or dependence, and then compute and present Shapley values for these groups instead of for all individual features. Reducing hundreds or thousands of features to half a dozen or so, makes precise computations practically feasible and the presentation and knowledge extraction greatly simplified. We prove that under certain conditions, groupShapley is equivalent to summing the feature-wise Shapley values within each feature group. Moreover, we provide a simulation study exemplifying the differences when these conditions are not met. We illustrate the usability of the approach in a real world car insurance example, where groupShapley is used to provide simple and intuitive explanations.
Explaining predictive models using Shapley values and non-parametric vine copulas
Feb 12, 2021


The original development of Shapley values for prediction explanation relied on the assumption that the features being described were independent. If the features in reality are dependent this may lead to incorrect explanations. Hence, there have recently been attempts of appropriately modelling/estimating the dependence between the features. Although the proposed methods clearly outperform the traditional approach assuming independence, they have their weaknesses. In this paper we propose two new approaches for modelling the dependence between the features. Both approaches are based on vine copulas, which are flexible tools for modelling multivariate non-Gaussian distributions able to characterise a wide range of complex dependencies. The performance of the proposed methods is evaluated on simulated data sets and a real data set. The experiments demonstrate that the vine copula approaches give more accurate approximations to the true Shapley values than its competitors.
Explaining predictive models with mixed features using Shapley values and conditional inference trees
Jul 02, 2020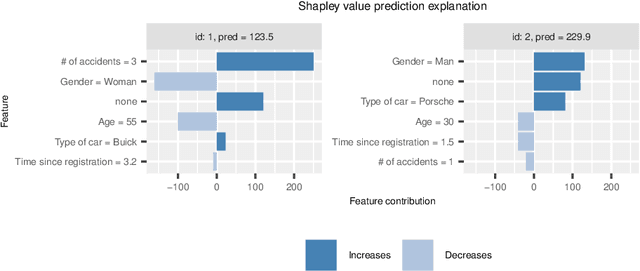


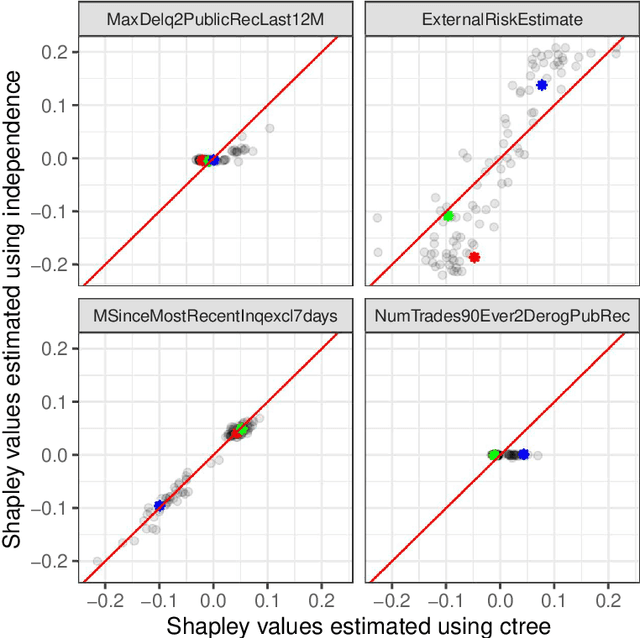
It is becoming increasingly important to explain complex, black-box machine learning models. Although there is an expanding literature on this topic, Shapley values stand out as a sound method to explain predictions from any type of machine learning model. The original development of Shapley values for prediction explanation relied on the assumption that the features being described were independent. This methodology was then extended to explain dependent features with an underlying continuous distribution. In this paper, we propose a method to explain mixed (i.e. continuous, discrete, ordinal, and categorical) dependent features by modeling the dependence structure of the features using conditional inference trees. We demonstrate our proposed method against the current industry standards in various simulation studies and find that our method often outperforms the other approaches. Finally, we apply our method to a real financial data set used in the 2018 FICO Explainable Machine Learning Challenge and show how our explanations compare to the FICO challenge Recognition Award winning team.
Deep Generative Models for Reject Inference in Credit Scoring
Apr 12, 2019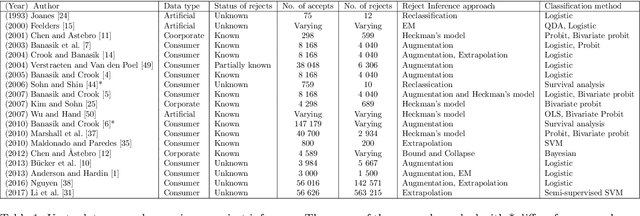

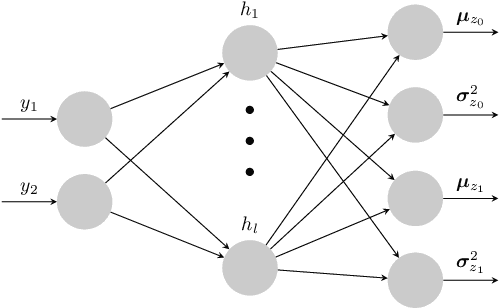
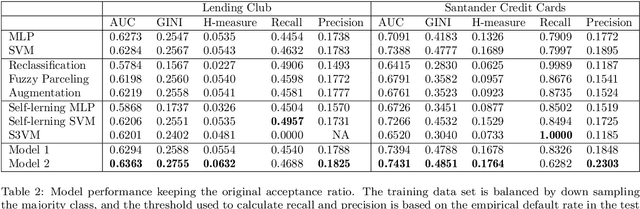
Credit scoring models based on accepted applications may be biased and their consequences can have a statistical and economic impact. Reject inference is the process of attempting to infer the creditworthiness status of the rejected applications. In this research, we use deep generative models to develop two new semi-supervised Bayesian models for reject inference in credit scoring, in which we model the data generating process to be dependent on a Gaussian mixture. The goal is to improve the classification accuracy in credit scoring models by adding reject applications. Our proposed models infer the unknown creditworthiness of the rejected applications by exact enumeration of the two possible outcomes of the loan (default or non-default). The efficient stochastic gradient optimization technique used in deep generative models makes our models suitable for large data sets. Finally, the experiments in this research show that our proposed models perform better than classical and alternative machine learning models for reject inference in credit scoring.
Explaining individual predictions when features are dependent: More accurate approximations to Shapley values
Mar 25, 2019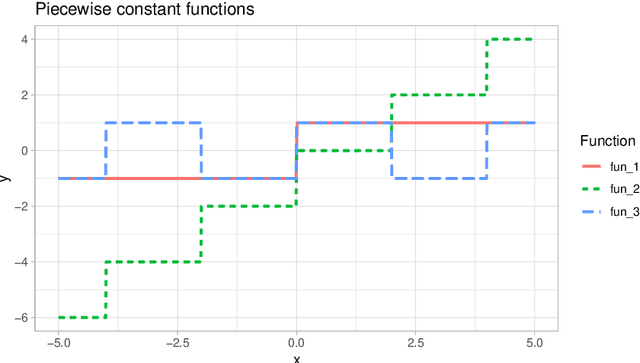
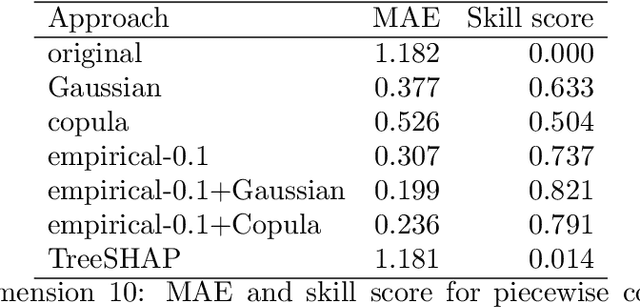


Explaining complex or seemingly simple machine learning models is a practical and ethical question, as well as a legal issue. Can I trust the model? Is it biased? Can I explain it to others? We want to explain individual predictions from a complex machine learning model by learning simple, interpretable explanations. Of existing work on interpreting complex models, Shapley values is the only method with a solid theoretical foundation. Kernel SHAP is a computationally efficient approximation to Shapley values in higher dimensions. Like most other existing methods, this approach assumes independent features, which may give very wrong explanations. This is the case even if a simple linear model is used for predictions. We extend the Kernel SHAP method to handle dependent features. We provide several examples of linear and non-linear models with linear and non-linear feature dependence, where our method gives more accurate approximations to the true Shapley values. We also propose a method for aggregating individual Shapley values, such that the prediction can be explained by groups of dependent variables.
Learning Latent Representations of Bank Customers With The Variational Autoencoder
Mar 14, 2019
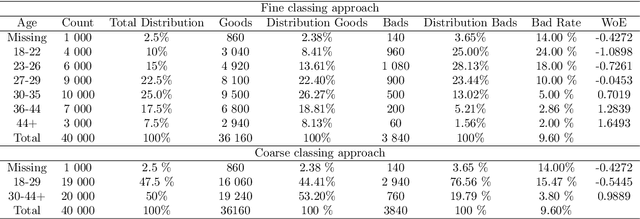
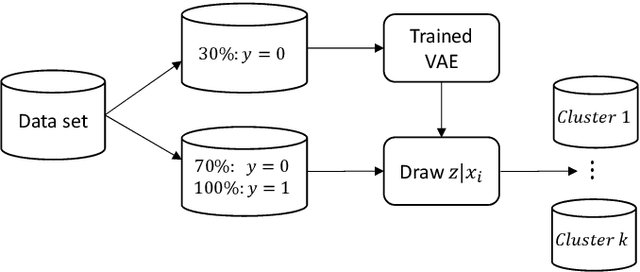

Learning data representations that reflect the customers' creditworthiness can improve marketing campaigns, customer relationship management, data and process management or the credit risk assessment in retail banks. In this research, we adopt the Variational Autoencoder (VAE), which has the ability to learn latent representations that contain useful information. We show that it is possible to steer the latent representations in the latent space of the VAE using the Weight of Evidence and forming a specific grouping of the data that reflects the customers' creditworthiness. Our proposed method learns a latent representation of the data, which shows a well-defied clustering structure capturing the customers' creditworthiness. These clusters are well suited for the aforementioned banks' activities. Further, our methodology generalizes to new customers, captures high-dimensional and complex financial data, and scales to large data sets.