 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing multimodal learning and deep generative models for corporate bankruptcy prediction
Nov 21, 2022

This research introduces for the first time, to the best of our knowledge, the concept of multimodal learning in bankruptcy prediction models. We use the Conditional Multimodal Discriminative (CMMD) model to learn multimodal representations that embed information from accounting, market, and textual modalities. The CMMD model needs a sample with all data modalities for model training. At test time, the CMMD model only needs access to accounting and market modalities to generate multimodal representations, which are further used to make bankruptcy predictions. This fact makes the use of bankruptcy prediction models using textual data realistic and possible, since accounting and market data are available for all companies unlike textual data. The empirical results in this research show that the classification performance of our proposed methodology is superior compared to that of a large number of traditional classifier models. We also show that our proposed methodology solves the limitation of previous bankruptcy models using textual data, as they can only make predictions for a small proportion of companies. Finally, based on multimodal representations, we introduce an index that is able to capture the uncertainty of the financial situation of companies during periods of financial distress.
Discriminative Multimodal Learning via Conditional Priors in Generative Models
Oct 09, 2021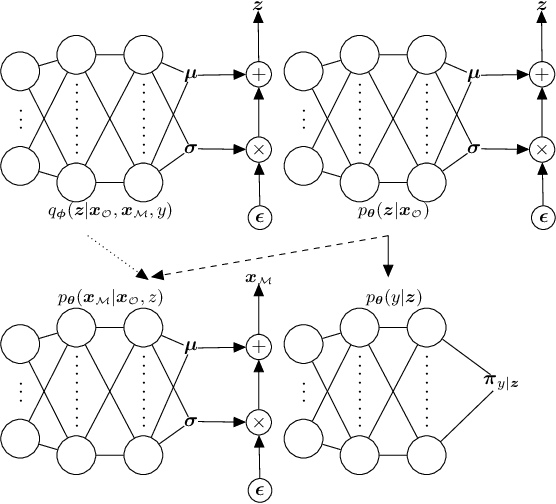
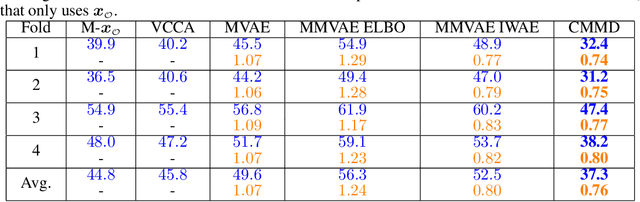
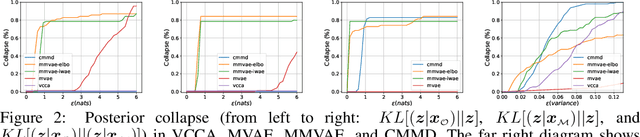
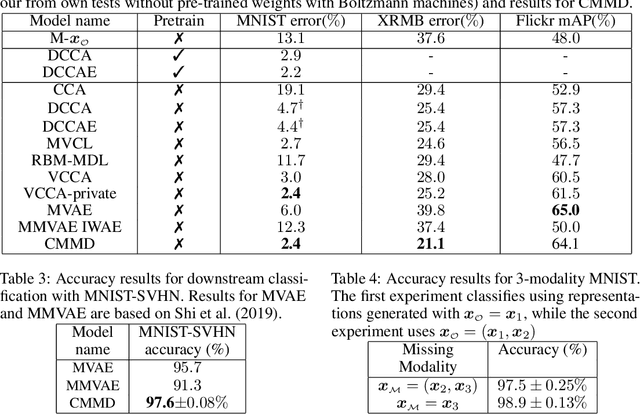
Deep generative models with latent variables have been used lately to learn joint representations and generative processes from multi-modal data. These two learning mechanisms can, however, conflict with each other and representations can fail to embed information on the data modalities. This research studies the realistic scenario in which all modalities and class labels are available for model training, but where some modalities and labels required for downstream tasks are missing. We show, in this scenario, that the variational lower bound limits mutual information between joint representations and missing modalities. We, to counteract these problems, introduce a novel conditional multi-modal discriminative model that uses an informative prior distribution and optimizes a likelihood-free objective function that maximizes mutual information between joint representations and missing modalities. Extensive experimentation shows the benefits of the model we propose, the empirical results showing that our model achieves state-of-the-art results in representative problems such as downstream classification, acoustic inversion and annotation generation.
Deep Generative Models for Reject Inference in Credit Scoring
Apr 12, 2019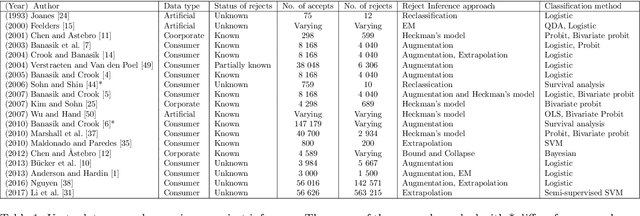

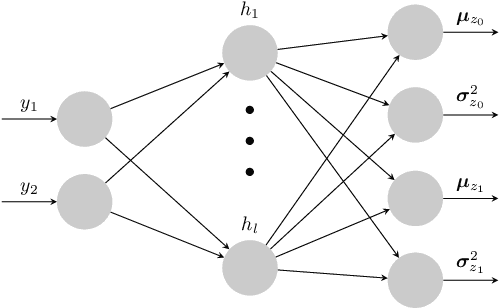
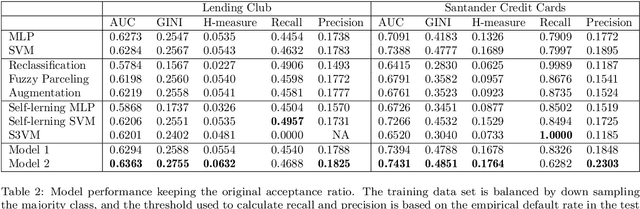
Credit scoring models based on accepted applications may be biased and their consequences can have a statistical and economic impact. Reject inference is the process of attempting to infer the creditworthiness status of the rejected applications. In this research, we use deep generative models to develop two new semi-supervised Bayesian models for reject inference in credit scoring, in which we model the data generating process to be dependent on a Gaussian mixture. The goal is to improve the classification accuracy in credit scoring models by adding reject applications. Our proposed models infer the unknown creditworthiness of the rejected applications by exact enumeration of the two possible outcomes of the loan (default or non-default). The efficient stochastic gradient optimization technique used in deep generative models makes our models suitable for large data sets. Finally, the experiments in this research show that our proposed models perform better than classical and alternative machine learning models for reject inference in credit scoring.