 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Pre-trained Transformer for Vietnamese Community-based COVID-19 Question Answering
Oct 31, 2023Recent studies have provided empirical evidence of the wide-ranging potential of Generative Pre-trained Transformer (GPT), a pretrained language model, in the field of natural language processing. GPT has been effectively employed as a decoder within state-of-the-art (SOTA) question answering systems, yielding exceptional performance across various tasks. However, the current research landscape concerning GPT's application in Vietnamese remains limited. This paper aims to address this gap by presenting an implementation of GPT-2 for community-based question answering specifically focused on COVID-19 related queries in Vietnamese. We introduce a novel approach by conducting a comparative analysis of different Transformers vs SOTA models in the community-based COVID-19 question answering dataset. The experimental findings demonstrate that the GPT-2 models exhibit highly promising outcomes, outperforming other SOTA models as well as previous community-based COVID-19 question answering models developed for Vietnamese.
ViCLEVR: A Visual Reasoning Dataset and Hybrid Multimodal Fusion Model for Visual Question Answering in Vietnamese
Oct 27, 2023In recent years, Visual Question Answering (VQA) has gained significant attention for its diverse applications, including intelligent car assistance, aiding visually impaired individuals, and document image information retrieval using natural language queries. VQA requires effective integration of information from questions and images to generate accurate answers. Neural models for VQA have made remarkable progress on large-scale datasets, with a primary focus on resource-rich languages like English. To address this, we introduce the ViCLEVR dataset, a pioneering collection for evaluating various visual reasoning capabilities in Vietnamese while mitigating biases. The dataset comprises over 26,000 images and 30,000 question-answer pairs (QAs), each question annotated to specify the type of reasoning involved. Leveraging this dataset, we conduct a comprehensive analysis of contemporary visual reasoning systems, offering valuable insights into their strengths and limitations. Furthermore, we present PhoVIT, a comprehensive multimodal fusion that identifies objects in images based on questions. The architecture effectively employs transformers to enable simultaneous reasoning over textual and visual data, merging both modalities at an early model stage. The experimental findings demonstrate that our proposed model achieves state-of-the-art performance across four evaluation metrics. The accompanying code and dataset have been made publicly accessible at \url{https://github.com/kvt0012/ViCLEVR}. This provision seeks to stimulate advancements within the research community, fostering the development of more multimodal fusion algorithms, specifically tailored to address the nuances of low-resource languages, exemplified by Vietnamese.
BARTPhoBEiT: Pre-trained Sequence-to-Sequence and Image Transformers Models for Vietnamese Visual Question Answering
Jul 28, 2023Visual Question Answering (VQA) is an intricate and demanding task that integrates natural language processing (NLP) and computer vision (CV), capturing the interest of researchers. The English language, renowned for its wealth of resources, has witnessed notable advancements in both datasets and models designed for VQA. However, there is a lack of models that target specific countries such as Vietnam. To address this limitation, we introduce a transformer-based Vietnamese model named BARTPhoBEiT. This model includes pre-trained Sequence-to-Sequence and bidirectional encoder representation from Image Transformers in Vietnamese and evaluates Vietnamese VQA datasets. Experimental results demonstrate that our proposed model outperforms the strong baseline and improves the state-of-the-art in six metrics: Accuracy, Precision, Recall, F1-score, WUPS 0.0, and WUPS 0.9.
A Comparative Study of Question Answering over Knowledge Bases
Nov 15, 2022



Question answering over knowledge bases (KBQA) has become a popular approach to help users extract information from knowledge bases. Although several systems exist, choosing one suitable for a particular application scenario is difficult. In this article, we provide a comparative study of six representative KBQA systems on eight benchmark datasets. In that, we study various question types, properties, languages, and domains to provide insights on where existing systems struggle. On top of that, we propose an advanced mapping algorithm to aid existing models in achieving superior results. Moreover, we also develop a multilingual corpus COVID-KGQA, which encourages COVID-19 research and multilingualism for the diversity of future AI. Finally, we discuss the key findings and their implications as well as performance guidelines and some future improvements. Our source code is available at \url{https://github.com/tamlhp/kbqa}.
Conversational Machine Reading Comprehension for Vietnamese Healthcare Texts
May 21, 2021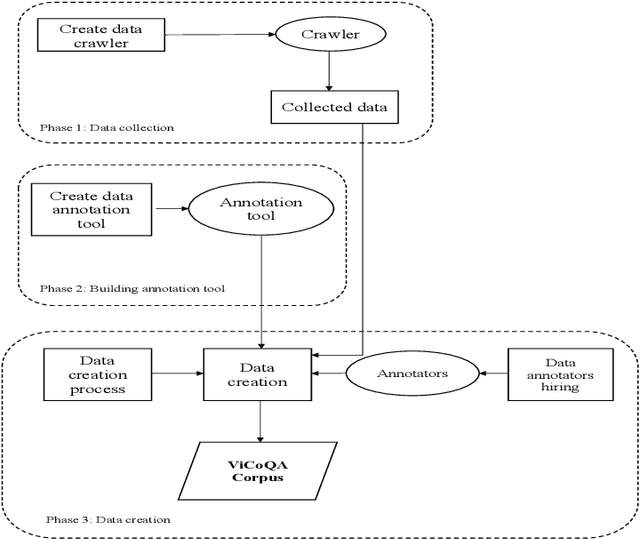
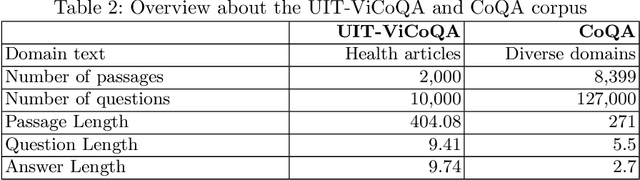
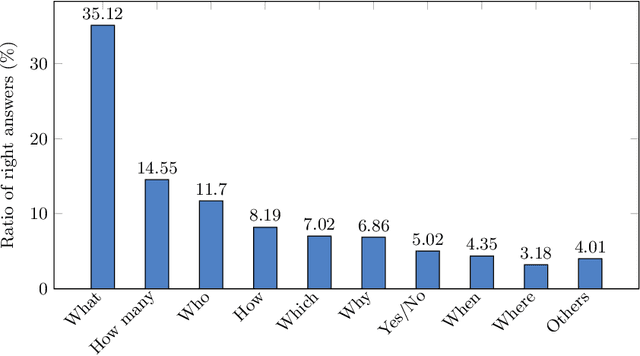

Machine reading comprehension (MRC) is a sub-field in natural language processing that aims to help computers understand unstructured texts and then answer questions related to them. In practice, conversation is an essential way to communicate and transfer information. To help machines understand conversation texts, we present UIT-ViCoQA - a new corpus for conversational machine reading comprehension in the Vietnamese language. This corpus consists of 10,000 questions with answers to over 2,000 conversations about health news articles. Then, we evaluate several baseline approaches for conversational machine comprehension on the UIT-ViCoQA corpus. The best model obtains an F1 score of 45.27%, which is 30.91 points behind human performance (76.18%), indicating that there is ample room for improvement.
UIT-HSE at WNUT-2020 Task 2: Exploiting CT-BERT for Identifying COVID-19 Information on the Twitter Social Network
Oct 09, 2020


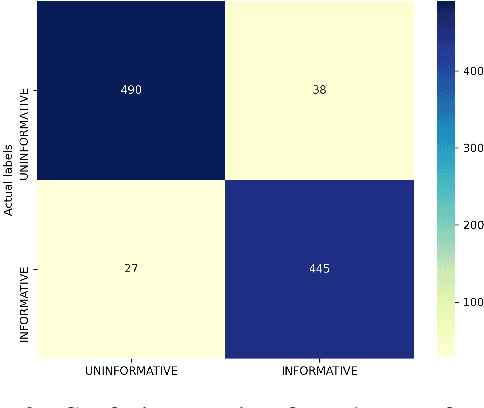
Recently, COVID-19 has affected a variety of real-life aspects of the world and led to dreadful consequences. More and more tweets about COVID-19 has been shared publicly on Twitter. However, the plurality of those Tweets are uninformative, which is challenging to build automatic systems to detect the informative ones for useful AI applications. In this paper, we present our results at the W-NUT 2020 Shared Task 2: Identification of Informative COVID-19 English Tweets. In particular, we propose our simple but effective approach using the transformer-based models based on COVID-Twitter-BERT (CT-BERT) with different fine-tuning techniques. As a result, we achieve the F1-Score of 90.94\% with the third place on the leaderboard of this task which attracted 56 submitted teams in total.
A Pilot Study on Multiple Choice Machine Reading Comprehension for Vietnamese Texts
Jan 16, 2020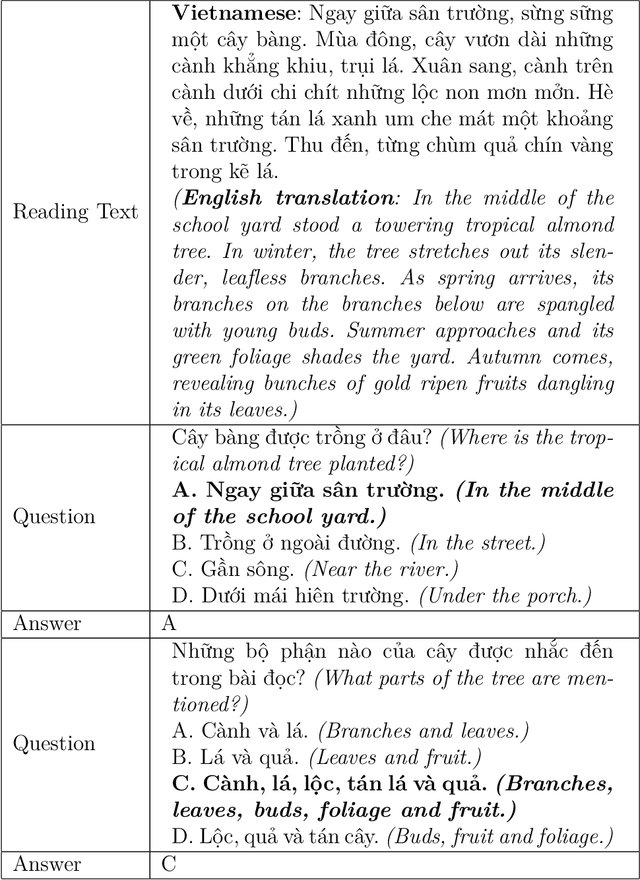
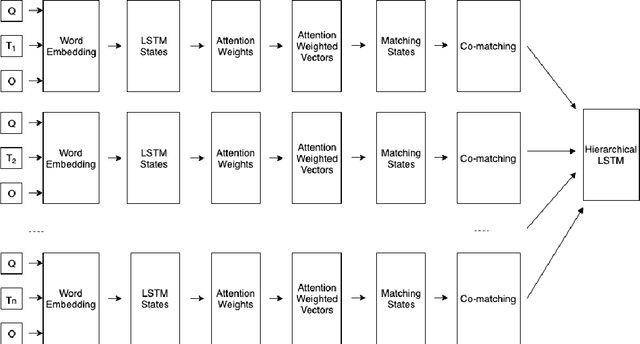
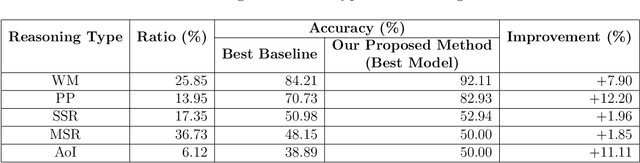

Machine Reading Comprehension (MRC) is the task of natural language processing which studies the ability to read and understand unstructured texts and then find the correct answers for questions. Until now, we have not yet had any MRC dataset for such a low-resource language as Vietnamese. In this paper, we introduce ViMMRC, a challenging machine comprehension corpus with multiple-choice questions, intended for research on the machine comprehension of Vietnamese text. This corpus includes 2,783 multiple-choice questions and answers based on a set of 417 Vietnamese texts used for teaching reading comprehension for 1st to 5th graders. Answers may be extracted from the contents of single or multiple sentences in the corresponding reading text. A thorough analysis of the corpus and experimental results in this paper illustrate that our corpus ViMMRC demands reasoning abilities beyond simple word matching. We proposed the method of Boosted Sliding Window (BSW) that improves 5.51% in accuracy over the best baseline method. We also measured human performance on the corpus and compared it to our MRC models. The performance gap between humans and our best experimental model indicates that significant progress can be made on Vietnamese machine reading comprehension in further research. The corpus is freely available at our website for research purposes.