 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pilot Study on Multiple Choice Machine Reading Comprehension for Vietnamese Texts
Paper and Code
Jan 16, 2020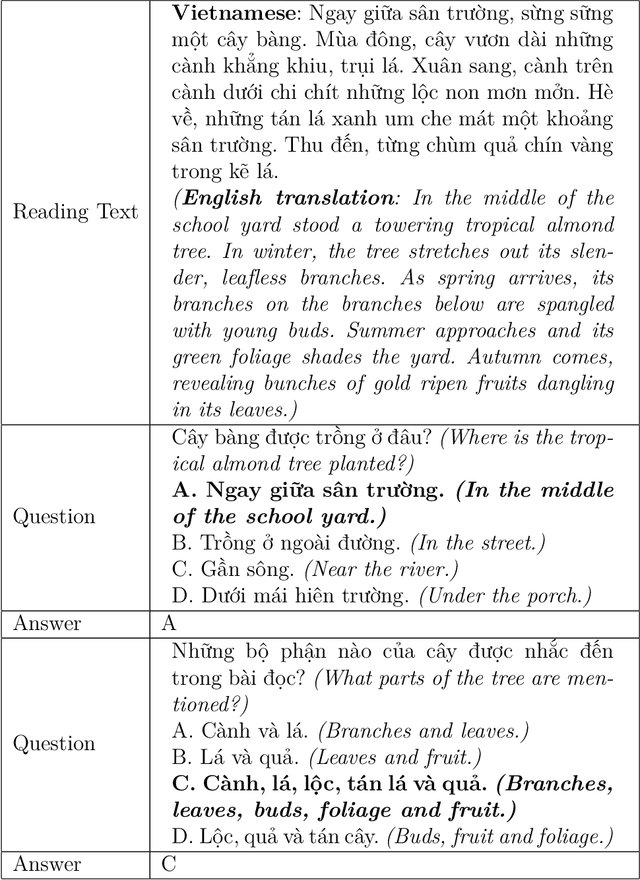
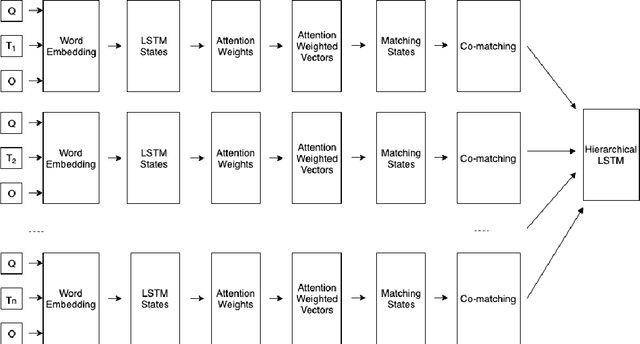
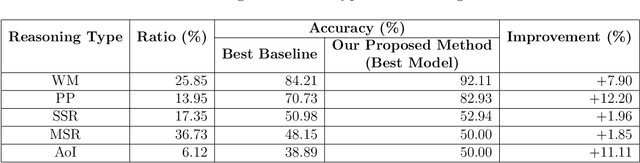

Machine Reading Comprehension (MRC) is the task of natural language processing which studies the ability to read and understand unstructured texts and then find the correct answers for questions. Until now, we have not yet had any MRC dataset for such a low-resource language as Vietnamese. In this paper, we introduce ViMMRC, a challenging machine comprehension corpus with multiple-choice questions, intended for research on the machine comprehension of Vietnamese text. This corpus includes 2,783 multiple-choice questions and answers based on a set of 417 Vietnamese texts used for teaching reading comprehension for 1st to 5th graders. Answers may be extracted from the contents of single or multiple sentences in the corresponding reading text. A thorough analysis of the corpus and experimental results in this paper illustrate that our corpus ViMMRC demands reasoning abilities beyond simple word matching. We proposed the method of Boosted Sliding Window (BSW) that improves 5.51% in accuracy over the best baseline method. We also measured human performance on the corpus and compared it to our MRC models. The performance gap between humans and our best experimental model indicates that significant progress can be made on Vietnamese machine reading comprehension in further research. The corpus is freely available at our website for research purposes.