 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of Tokenization and Downstream Model
May 26, 2021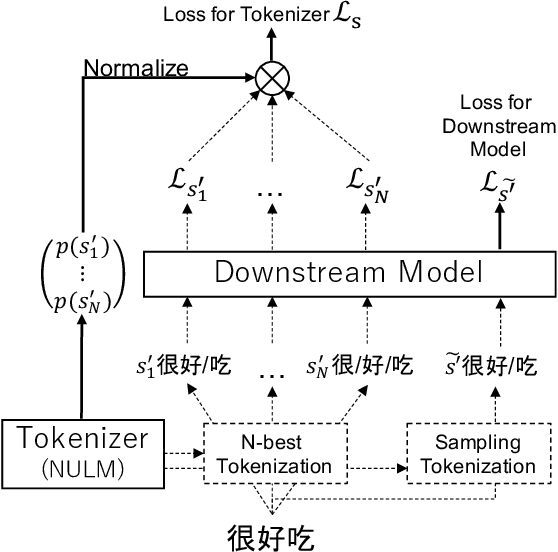
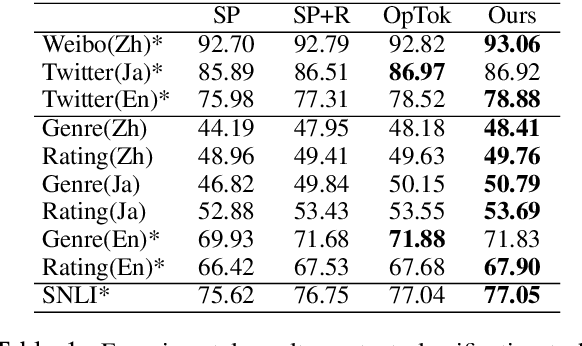
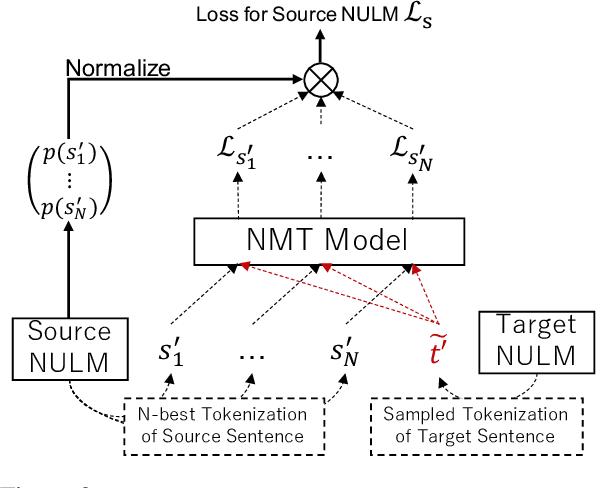

Since traditional tokenizers are isolated from a downstream task and model, they cannot output an appropriate tokenization depending on the task and model, although recent studies imply that the appropriate tokenization improves the performance. In this paper, we propose a novel method to find an appropriate tokenization to a given downstream model by jointly optimizing a tokenizer and the model. The proposed method has no restriction except for using loss values computed by the downstream model to train the tokenizer, and thus, we can apply the proposed method to any NLP task. Moreover, the proposed method can be used to explore the appropriate tokenization for an already trained model as post-processing. Therefore, the proposed method is applicable to various situations. We evaluated whether our method contributes to improving performance on text classification in three languages and machine translation in eight language pairs. Experimental results show that our proposed method improves the performance by determining appropriate tokenizations.
How LSTM Encodes Syntax: Exploring Context Vectors and Semi-Quantization on Natural Text
Oct 01, 2020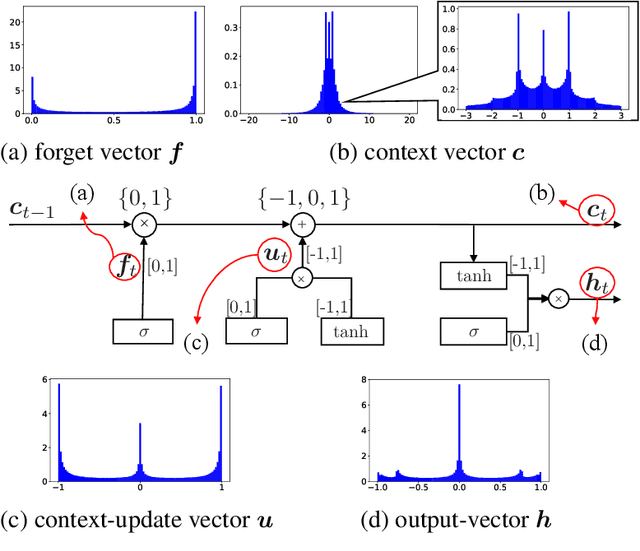
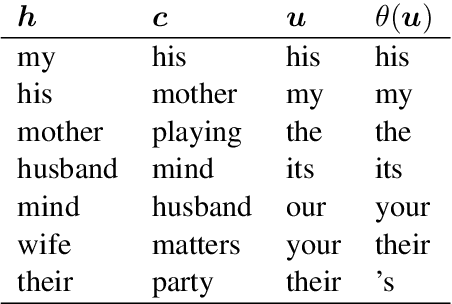
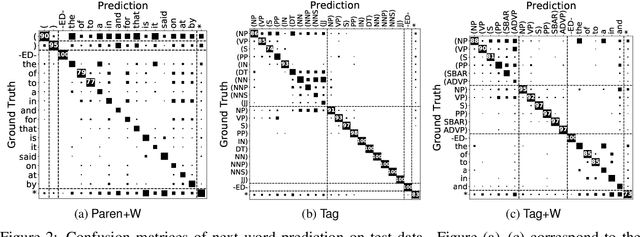
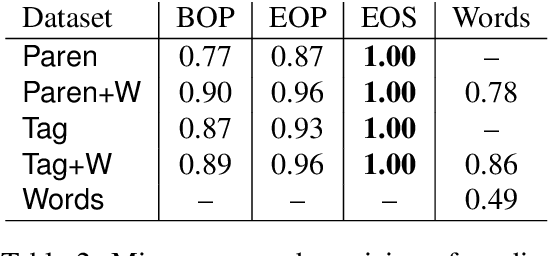
Long Short-Term Memory recurrent neural network (LSTM) is widely used and known to capture informative long-term syntactic dependencies. However, how such information are reflected in its internal vectors for natural text has not yet been sufficiently investigated. We analyze them by learning a language model where syntactic structures are implicitly given. We empirically show that the context update vectors, i.e. outputs of internal gates, are approximately quantized to binary or ternary values to help the language model to count the depth of nesting accurately, as Suzgun et al. (2019) recently show for synthetic Dyck languages. For some dimensions in the context vector, we show that their activations are highly correlated with the depth of phrase structures, such as VP and NP. Moreover, with an $L_1$ regularization, we also found that it can accurately predict whether a word is inside a phrase structure or not from a small number of components of the context vector. Even for the case of learning from raw text, context vectors are shown to still correlate well with the phrase structures. Finally, we show that natural clusters of the functional words and the part of speeches that trigger phrases are represented in a small but principal subspace of the context-update vector of LSTM.