 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of Tokenization and Downstream Model
Paper and Code
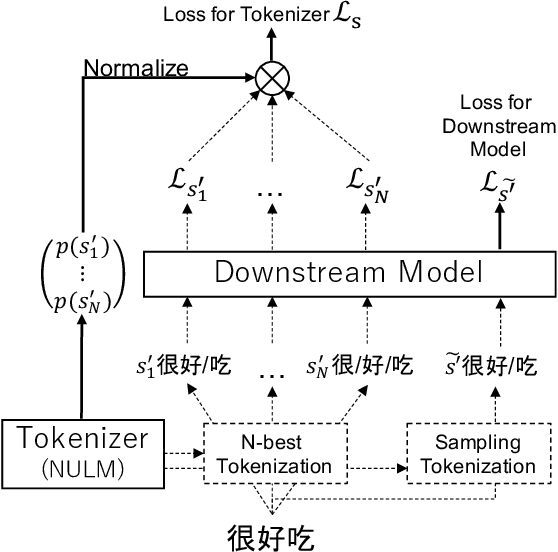
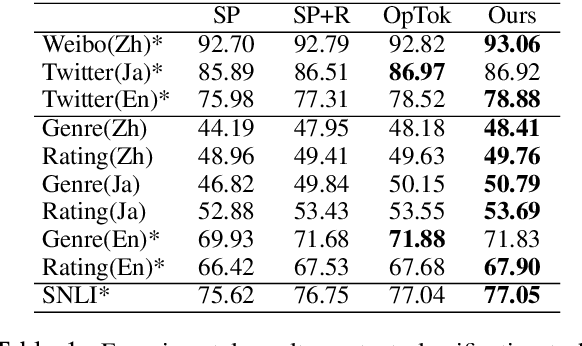
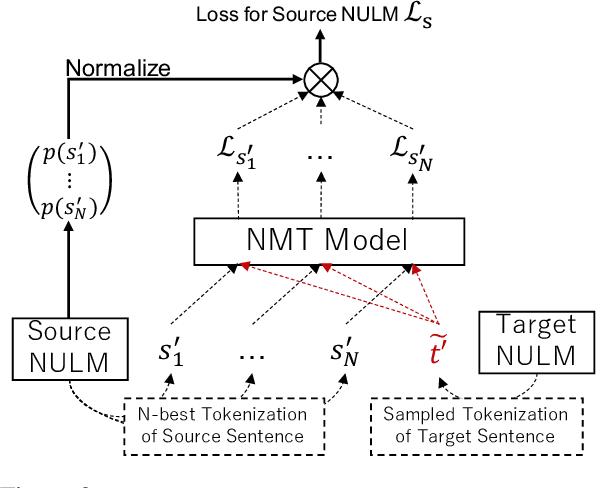

Since traditional tokenizers are isolated from a downstream task and model, they cannot output an appropriate tokenization depending on the task and model, although recent studies imply that the appropriate tokenization improves the performance. In this paper, we propose a novel method to find an appropriate tokenization to a given downstream model by jointly optimizing a tokenizer and the model. The proposed method has no restriction except for using loss values computed by the downstream model to train the tokenizer, and thus, we can apply the proposed method to any NLP task. Moreover, the proposed method can be used to explore the appropriate tokenization for an already trained model as post-processing. Therefore, the proposed method is applicable to various situations. We evaluated whether our method contributes to improving performance on text classification in three languages and machine translation in eight language pairs. Experimental results show that our proposed method improves the performance by determining appropriate tokenizations.