 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaw Audio Classification with Cosine Convolutional Neural Network (CosCovNN)
Nov 30, 2024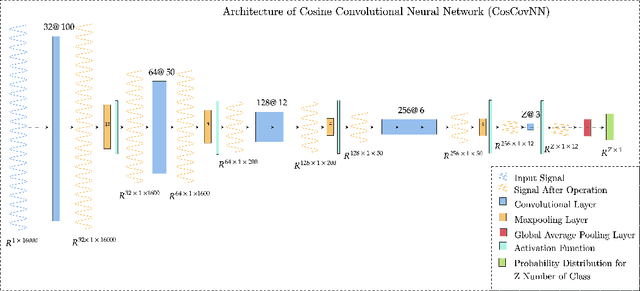
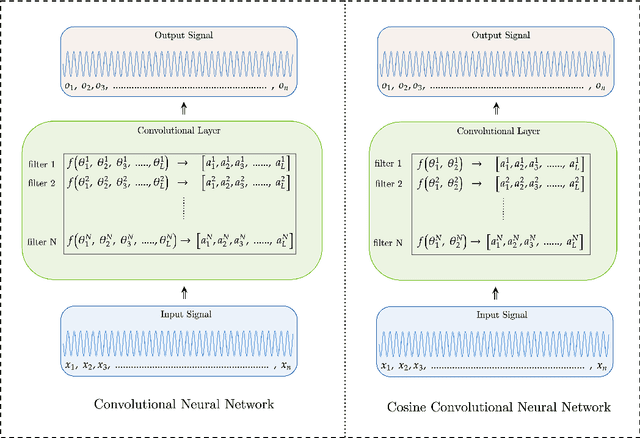
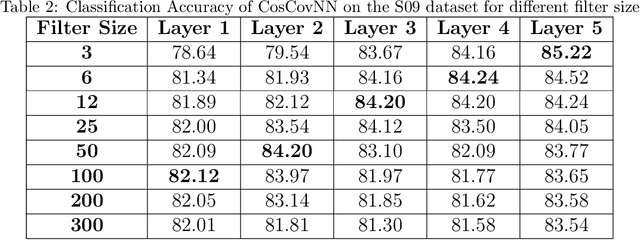
This study explores the field of audio classification from raw waveform using Convolutional Neural Networks (CNNs), a method that eliminates the need for extracting specialised features in the pre-processing step. Unlike recent trends in literature, which often focuses on designing frontends or filters for only the initial layers of CNNs, our research introduces the Cosine Convolutional Neural Network (CosCovNN) replacing the traditional CNN filters with Cosine filters. The CosCovNN surpasses the accuracy of the equivalent CNN architectures with approximately $77\%$ less parameters. Our research further progresses with the development of an augmented CosCovNN named Vector Quantised Cosine Convolutional Neural Network with Memory (VQCCM), incorporating a memory and vector quantisation layer VQCCM achieves state-of-the-art (SOTA) performance across five different datasets in comparison with existing literature. Our findings show that cosine filters can greatly improve the efficiency and accuracy of CNNs in raw audio classification.
Feasibility of Mental Health Triage Call Priority Prediction Using Machine Learning
Nov 25, 2024

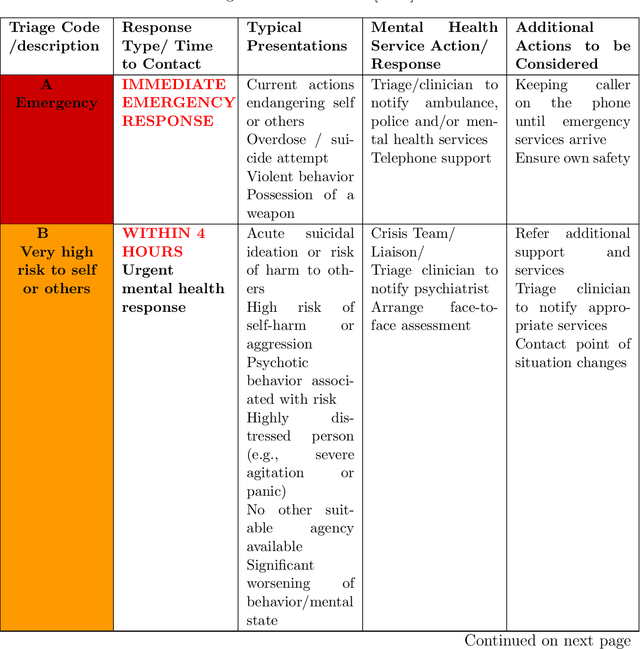

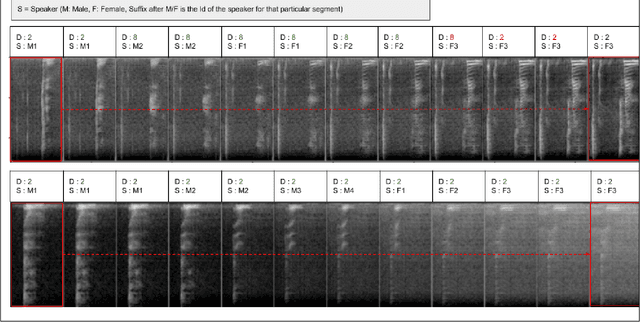
Ensuring accurate call prioritisation is essential for optimising the efficiency and responsiveness of mental health helplines. Currently, call operators rely entirely on the caller's statements to determine the priority of the calls. It has been shown that entirely subjective assessment can lead to errors. Furthermore, it is a missed opportunity not to utilise the voice properties readily available during the call to aid in the evaluation. Incorrect prioritisation can result in delayed assistance for high-risk individuals, resource misallocation, increased mental health deterioration, loss of trust, and potential legal consequences. It is vital to address these risks to guarantee the reliability and effectiveness of mental health services. This study delves into the potential of using machine learning, a branch of Artificial Intelligence, to estimate call priority from the callers' voices for users of mental health phone helplines. After analysing 459 call records from a mental health helpline, we achieved a balanced accuracy of 92\%, showing promise in aiding the call operators' efficiency in call handling processes and improving customer satisfaction.
High-Fidelity Audio Generation and Representation Learning with Guided Adversarial Autoencoder
Jun 01, 2020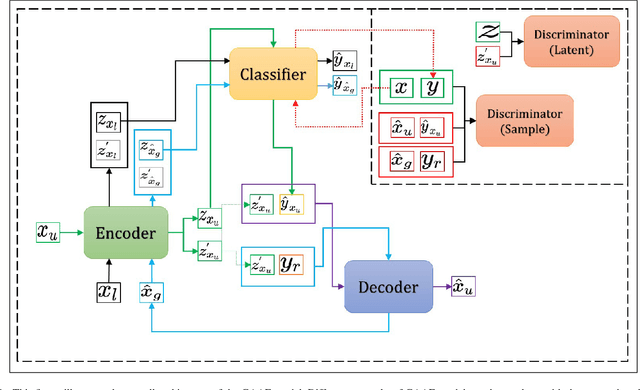



Unsupervised disentangled representation learning from the unlabelled audio data, and high fidelity audio generation have become two linchpins in the machine learning research fields. However, the representation learned from an unsupervised setting does not guarantee its' usability for any downstream task at hand, which can be a wastage of the resources, if the training was conducted for that particular posterior job. Also, during the representation learning, if the model is highly biased towards the downstream task, it losses its generalisation capability which directly benefits the downstream job but the ability to scale it to other related task is lost. Therefore, to fill this gap, we propose a new autoencoder based model named "Guided Adversarial Autoencoder (GAAE)", which can learn both post-task-specific representations and the general representation capturing the factors of variation in the training data leveraging a small percentage of labelled samples; thus, makes it suitable for future related tasks. Furthermore, our proposed model can generate audio with superior quality, which is indistinguishable from the real audio samples. Hence, with the extensive experimental results, we have demonstrated that by harnessing the power of the high-fidelity audio generation, the proposed GAAE model can learn powerful representation from unlabelled dataset leveraging a fewer percentage of labelled data as supervision/guidance.
Guided Generative Adversarial Neural Network for Representation Learning and High Fidelity Audio Generation using Fewer Labelled Audio Data
Mar 05, 2020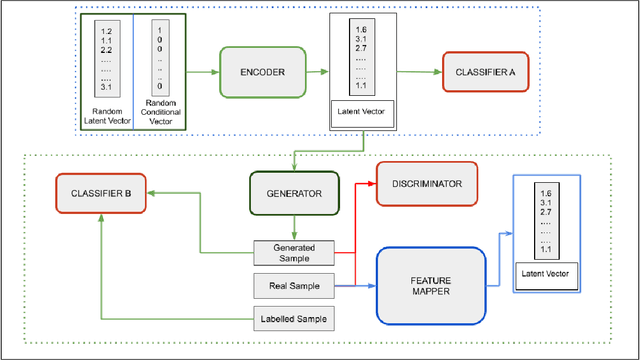

Recent improvements in Generative Adversarial Neural Networks (GANs) have shown their ability to generate higher quality samples as well as to learn good representations for transfer learning. Most of the representation learning methods based on GANs learn representations ignoring their post-use scenario, which can lead to increased generalisation ability. However, the model can become redundant if it is intended for a specific task. For example, assume we have a vast unlabelled audio dataset, and we want to learn a representation from this dataset so that it can be used to improve the emotion recognition performance of a small labelled audio dataset. During the representation learning training, if the model does not know the post emotion recognition task, it can completely ignore emotion-related characteristics in the learnt representation. This is a fundamental challenge for any unsupervised representation learning model. In this paper, we aim to address this challenge by proposing a novel GAN framework: Guided Generative Neural Network (GGAN), which guides a GAN to focus on learning desired representations and generating superior quality samples for audio data leveraging fewer labelled samples. Experimental results show that using a very small amount of labelled data as guidance, a GGAN learns significantly better representations.
Disentangled Representation Learning with Information Maximizing Autoencoder
Apr 18, 2019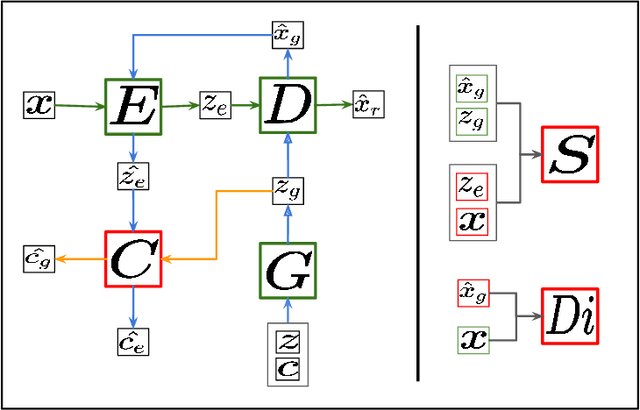


Learning disentangled representation from any unlabelled data is a non-trivial problem. In this paper we propose Information Maximising Autoencoder (InfoAE) where the encoder learns powerful disentangled representation through maximizing the mutual information between the representation and given information in an unsupervised fashion. We have evaluated our model on MNIST dataset and achieved 98.9 ($\pm .1$) $\%$ test accuracy while using complete unsupervised training.
Image denoising and restoration with CNN-LSTM Encoder Decoder with Direct Attention
Jan 16, 2018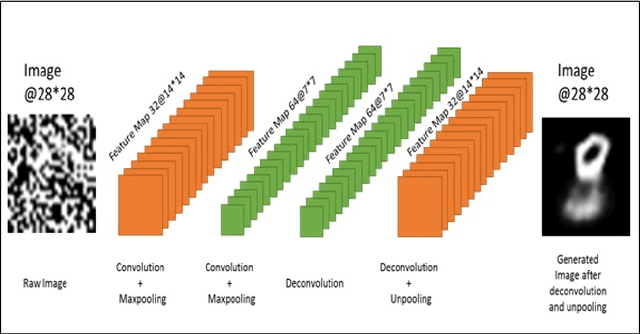
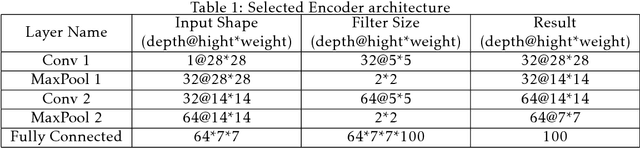
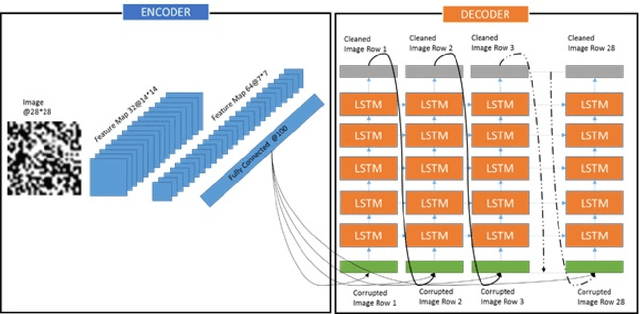
Image denoising is always a challenging task in the field of computer vision and image processing. In this paper, we have proposed an encoder-decoder model with direct attention, which is capable of denoising and reconstruct highly corrupted images. Our model consists of an encoder and a decoder, where the encoder is a convolutional neural network and decoder is a multilayer Long Short-Term memory network. In the proposed model, the encoder reads an image and catches the abstraction of that image in a vector, where decoder takes that vector as well as the corrupted image to reconstruct a clean image. We have trained our model on MNIST handwritten digit database after making lower half of every image as black as well as adding noise top of that. After a massive destruction of the images where it is hard for a human to understand the content of those images, our model can retrieve that image with minimal error. Our proposed model has been compared with convolutional encoder-decoder, where our model has performed better at generating missing part of the images than convolutional autoencoder.