 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Audio Generation and Representation Learning with Guided Adversarial Autoencoder
Paper and Code
Jun 01, 2020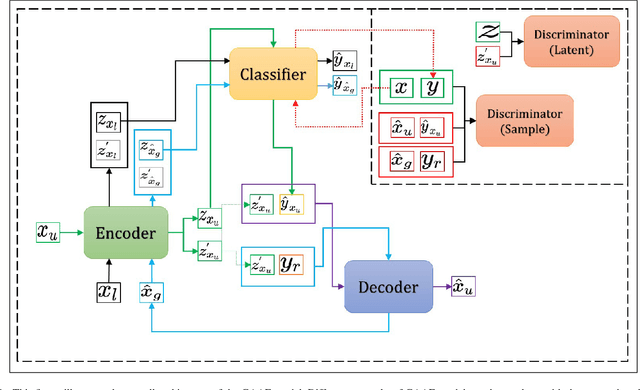



Unsupervised disentangled representation learning from the unlabelled audio data, and high fidelity audio generation have become two linchpins in the machine learning research fields. However, the representation learned from an unsupervised setting does not guarantee its' usability for any downstream task at hand, which can be a wastage of the resources, if the training was conducted for that particular posterior job. Also, during the representation learning, if the model is highly biased towards the downstream task, it losses its generalisation capability which directly benefits the downstream job but the ability to scale it to other related task is lost. Therefore, to fill this gap, we propose a new autoencoder based model named "Guided Adversarial Autoencoder (GAAE)", which can learn both post-task-specific representations and the general representation capturing the factors of variation in the training data leveraging a small percentage of labelled samples; thus, makes it suitable for future related tasks. Furthermore, our proposed model can generate audio with superior quality, which is indistinguishable from the real audio samples. Hence, with the extensive experimental results, we have demonstrated that by harnessing the power of the high-fidelity audio generation, the proposed GAAE model can learn powerful representation from unlabelled dataset leveraging a fewer percentage of labelled data as supervision/guidance.