 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Generative Adversarial Neural Network for Representation Learning and High Fidelity Audio Generation using Fewer Labelled Audio Data
Paper and Code
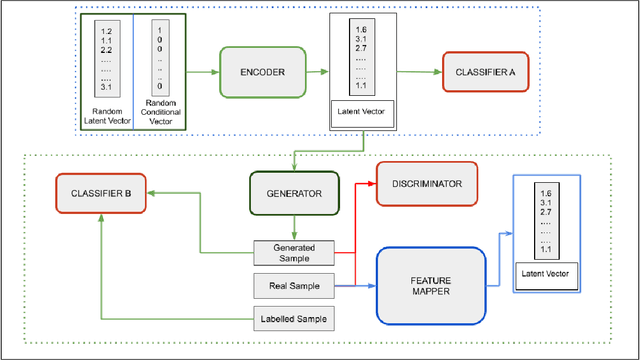
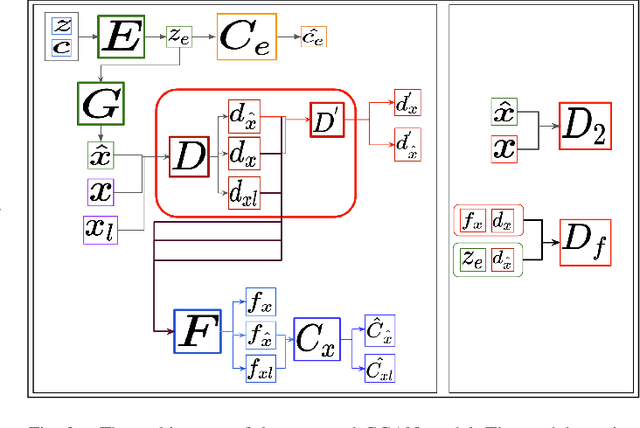

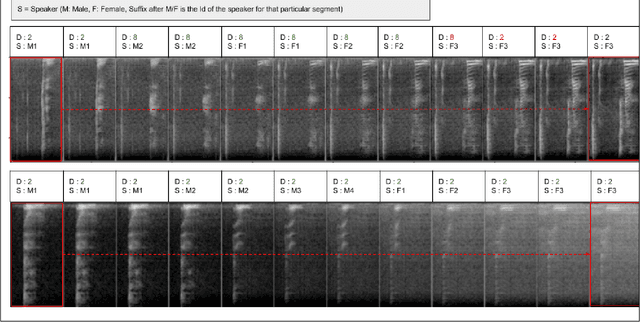
Recent improvements in Generative Adversarial Neural Networks (GANs) have shown their ability to generate higher quality samples as well as to learn good representations for transfer learning. Most of the representation learning methods based on GANs learn representations ignoring their post-use scenario, which can lead to increased generalisation ability. However, the model can become redundant if it is intended for a specific task. For example, assume we have a vast unlabelled audio dataset, and we want to learn a representation from this dataset so that it can be used to improve the emotion recognition performance of a small labelled audio dataset. During the representation learning training, if the model does not know the post emotion recognition task, it can completely ignore emotion-related characteristics in the learnt representation. This is a fundamental challenge for any unsupervised representation learning model. In this paper, we aim to address this challenge by proposing a novel GAN framework: Guided Generative Neural Network (GGAN), which guides a GAN to focus on learning desired representations and generating superior quality samples for audio data leveraging fewer labelled samples. Experimental results show that using a very small amount of labelled data as guidance, a GGAN learns significantly better representations.