 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGAN-CRCM: A Novel Multiple Generative Adversarial Network and Coarse-Refinement Based Cognizant Method for Image Inpainting
Dec 25, 2024Image inpainting is a widely used technique in computer vision for reconstructing missing or damaged pixels in images. Recent advancements with Generative Adversarial Networks (GANs) have demonstrated superior performance over traditional methods due to their deep learning capabilities and adaptability across diverse image domains. Residual Networks (ResNet) have also gained prominence for their ability to enhance feature representation and compatibility with other architectures. This paper introduces a novel architecture combining GAN and ResNet models to improve image inpainting outcomes. Our framework integrates three components: Transpose Convolution-based GAN for guided and blind inpainting, Fast ResNet-Convolutional Neural Network (FR-CNN) for object removal, and Co-Modulation GAN (Co-Mod GAN) for refinement. The model's performance was evaluated on benchmark datasets, achieving accuracies of 96.59% on Image-Net, 96.70% on Places2, and 96.16% on CelebA. Comparative analyses demonstrate that the proposed architecture outperforms existing methods, highlighting its effectiveness in both qualitative and quantitative evaluations.
Image denoising and restoration with CNN-LSTM Encoder Decoder with Direct Attention
Jan 16, 2018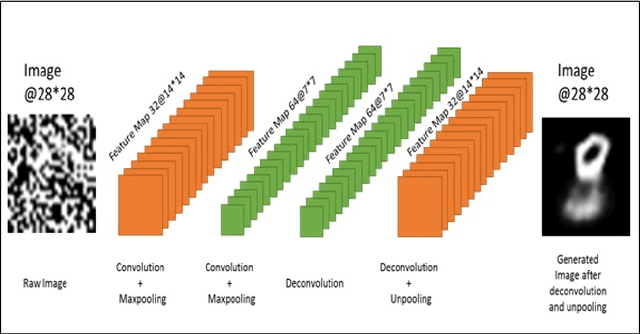
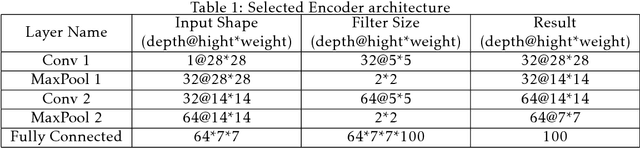
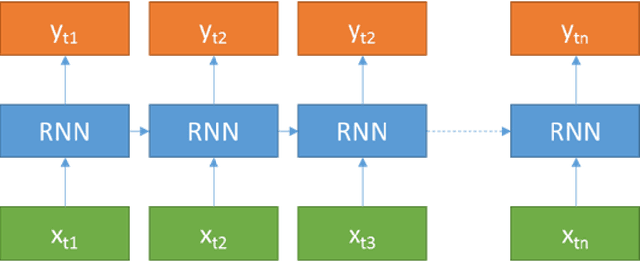
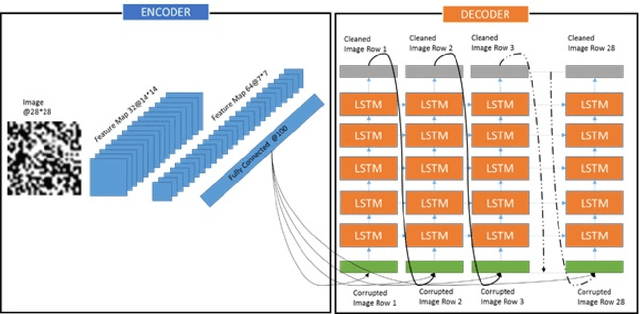
Image denoising is always a challenging task in the field of computer vision and image processing. In this paper, we have proposed an encoder-decoder model with direct attention, which is capable of denoising and reconstruct highly corrupted images. Our model consists of an encoder and a decoder, where the encoder is a convolutional neural network and decoder is a multilayer Long Short-Term memory network. In the proposed model, the encoder reads an image and catches the abstraction of that image in a vector, where decoder takes that vector as well as the corrupted image to reconstruct a clean image. We have trained our model on MNIST handwritten digit database after making lower half of every image as black as well as adding noise top of that. After a massive destruction of the images where it is hard for a human to understand the content of those images, our model can retrieve that image with minimal error. Our proposed model has been compared with convolutional encoder-decoder, where our model has performed better at generating missing part of the images than convolutional autoencoder.