 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT and U(X): A Rapid Review on Measuring the User Experience
Mar 20, 2025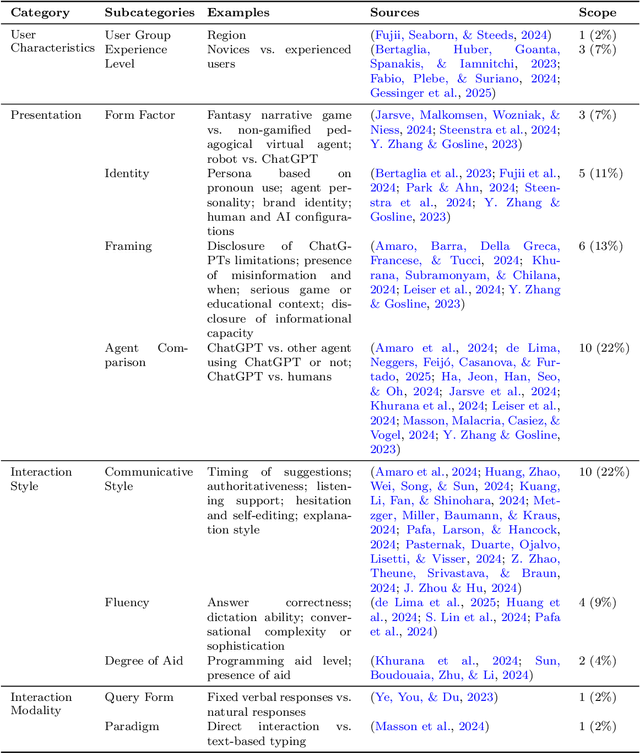
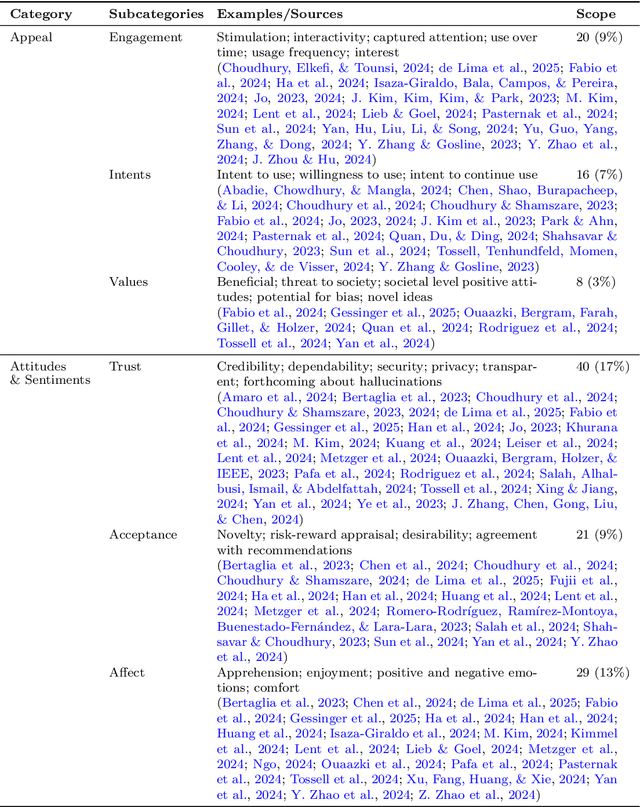
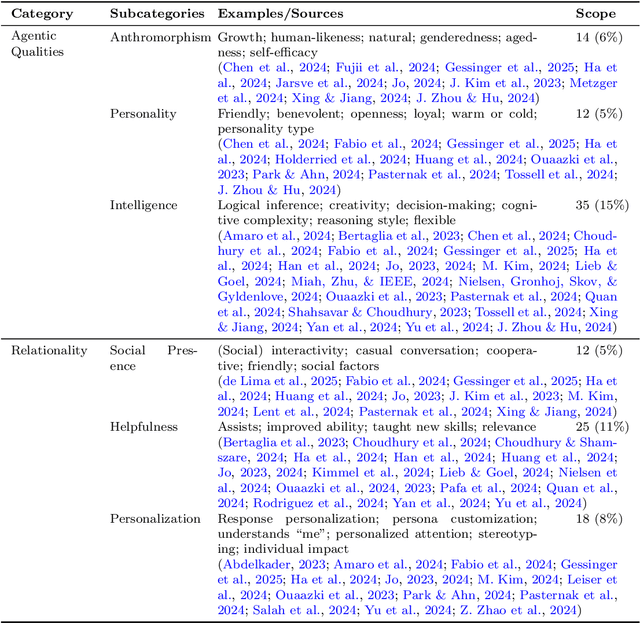

ChatGPT, powered by a large language model (LLM), has revolutionized everyday human-computer interaction (HCI) since its 2022 release. While now used by millions around the world, a coherent pathway for evaluating the user experience (UX) ChatGPT offers remains missing. In this rapid review (N = 58), I explored how ChatGPT UX has been approached quantitatively so far. I focused on the independent variables (IVs) manipulated, the dependent variables (DVs) measured, and the methods used for measurement. Findings reveal trends, gaps, and emerging consensus in UX assessments. This work offers a first step towards synthesizing existing approaches to measuring ChatGPT UX, urgent trajectories to advance standardization and breadth, and two preliminary frameworks aimed at guiding future research and tool development. I seek to elevate the field of ChatGPT UX by empowering researchers and practitioners in optimizing user interactions with ChatGPT and similar LLM-based systems.
Bots against Bias: Critical Next Steps for Human-Robot Interaction
Dec 17, 2024We humans are biased - and our robotic creations are biased, too. Bias is a natural phenomenon that drives our perceptions and behavior, including when it comes to socially expressive robots that have humanlike features. Recognizing that we embed bias, knowingly or not, within the design of such robots is crucial to studying its implications for people in modern societies. In this chapter, I consider the multifaceted question of bias in the context of humanoid, AI-enabled, and expressive social robots: Where does bias arise, what does it look like, and what can (or should) we do about it. I offer observations on human-robot interaction (HRI) along two parallel tracks: (1) robots designed in bias-conscious ways and (2) robots that may help us tackle bias in the human world. I outline a curated selection of cases for each track drawn from the latest HRI research and positioned against social, legal, and ethical factors. I also propose a set of critical next steps to tackle the challenges and opportunities on bias within HRI research and practice.
Robotic Backchanneling in Online Conversation Facilitation: A Cross-Generational Study
Sep 25, 2024



Japan faces many challenges related to its aging society, including increasing rates of cognitive decline in the population and a shortage of caregivers. Efforts have begun to explore solutions using artificial intelligence (AI), especially socially embodied intelligent agents and robots that can communicate with people. Yet, there has been little research on the compatibility of these agents with older adults in various everyday situations. To this end, we conducted a user study to evaluate a robot that functions as a facilitator for a group conversation protocol designed to prevent cognitive decline. We modified the robot to use backchannelling, a natural human way of speaking, to increase receptiveness of the robot and enjoyment of the group conversation experience. We conducted a cross-generational study with young adults and older adults. Qualitative analyses indicated that younger adults perceived the backchannelling version of the robot as kinder, more trustworthy, and more acceptable than the non-backchannelling robot. Finally, we found that the robot's backchannelling elicited nonverbal backchanneling in older participants.
From "Made In" to Mukokuseki: Exploring the Visual Perception of National Identity in Robots
Aug 30, 2024People read human characteristics into the design of social robots, a visual process with socio-cultural implications. One factor may be nationality, a complex social characteristic that is linked to ethnicity, culture, and other factors of identity that can be embedded in the visual design of robots. Guided by social identity theory (SIT), we explored the notion of "mukokuseki," a visual design characteristic defined by the absence of visual cues to national and ethnic identity in Japanese cultural exports. In a two-phase categorization study (n=212), American (n=110) and Japanese (n=92) participants rated a random selection of nine robot stimuli from America and Japan, plus multinational Pepper. We found evidence of made-in and two kinds of mukokuseki effects. We offer suggestions for the visual design of mukokuseki robots that may interact with people from diverse backgrounds. Our findings have implications for robots and social identity, the viability of robotic exports, and the use of robots internationally.
* 35 pages
Silver-Tongued and Sundry: Exploring Intersectional Pronouns with ChatGPT
May 13, 2024ChatGPT is a conversational agent built on a large language model. Trained on a significant portion of human output, ChatGPT can mimic people to a degree. As such, we need to consider what social identities ChatGPT simulates (or can be designed to simulate). In this study, we explored the case of identity simulation through Japanese first-person pronouns, which are tightly connected to social identities in intersectional ways, i.e., intersectional pronouns. We conducted a controlled online experiment where people from two regions in Japan (Kanto and Kinki) witnessed interactions with ChatGPT using ten sets of first-person pronouns. We discovered that pronouns alone can evoke perceptions of social identities in ChatGPT at the intersections of gender, age, region, and formality, with caveats. This work highlights the importance of pronoun use for social identity simulation, provides a language-based methodology for culturally-sensitive persona development, and advances the potential of intersectional identities in intelligent agents.
* Honorable Mention award (top 5%) at CHI '24
Qualitative Approaches to Voice UX
Apr 23, 2024Voice is a natural mode of expression offered by modern computer-based systems. Qualitative perspectives on voice-based user experiences (voice UX) offer rich descriptions of complex interactions that numbers alone cannot fully represent. We conducted a systematic review of the literature on qualitative approaches to voice UX, capturing the nature of this body of work in a systematic map and offering a qualitative synthesis of findings. We highlight the benefits of qualitative methods for voice UX research, identify opportunities for increasing rigour in methods and outcomes, and distill patterns of experience across a diversity of devices and modes of qualitative praxis.
Coimagining the Future of Voice Assistants with Cultural Sensitivity
Mar 26, 2024Voice assistants (VAs) are becoming a feature of our everyday life. Yet, the user experience (UX) is often limited, leading to underuse, disengagement, and abandonment. Co-designing interactions for VAs with potential end-users can be useful. Crowdsourcing this process online and anonymously may add value. However, most work has been done in the English-speaking West on dialogue data sets. We must be sensitive to cultural differences in language, social interactions, and attitudes towards technology. Our aims were to explore the value of co-designing VAs in the non-Western context of Japan and demonstrate the necessity of cultural sensitivity. We conducted an online elicitation study (N = 135) where Americans (n = 64) and Japanese people (n = 71) imagined dialogues (N = 282) and activities (N = 73) with future VAs. We discuss the implications for coimagining interactions with future VAs, offer design guidelines for the Japanese and English-speaking US contexts, and suggest opportunities for cultural plurality in VA design and scholarship.
* 21 pages
Can Voice Assistants Sound Cute? Towards a Model of Kawaii Vocalics
Apr 22, 2023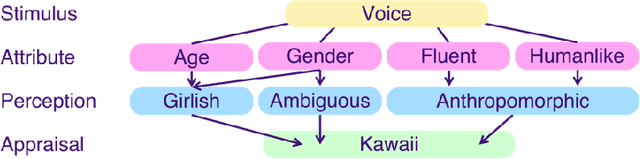
The Japanese notion of "kawaii" or expressions of cuteness, vulnerability, and/or charm is a global cultural export. Work has explored kawaii-ness as a design feature and factor of user experience in the visual appearance, nonverbal behaviour, and sound of robots and virtual characters. In this initial work, we consider whether voices can be kawaii by exploring the vocal qualities of voice assistant speech, i.e., kawaii vocalics. Drawing from an age-inclusive model of kawaii, we ran a user perceptions study on the kawaii-ness of younger- and older-sounding Japanese computer voices. We found that kawaii-ness intersected with perceptions of gender and age, i.e., gender ambiguous and girlish, as well as VA features, i.e., fluency and artificiality. We propose an initial model of kawaii vocalics to be validated through the identification and study of vocal qualities, cognitive appraisals, behavioural responses, and affective reports.
* 7 pages
Dis/Immersion in Mindfulness Meditation with a Wandering Voice Assistant
Apr 22, 2023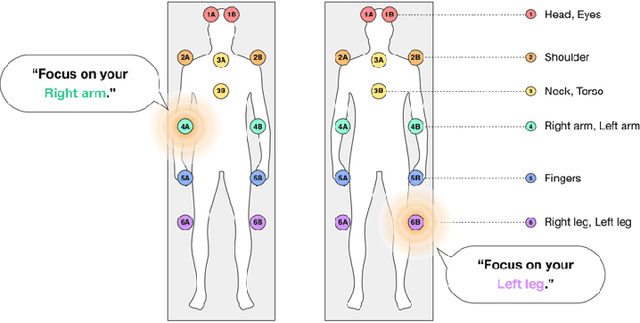
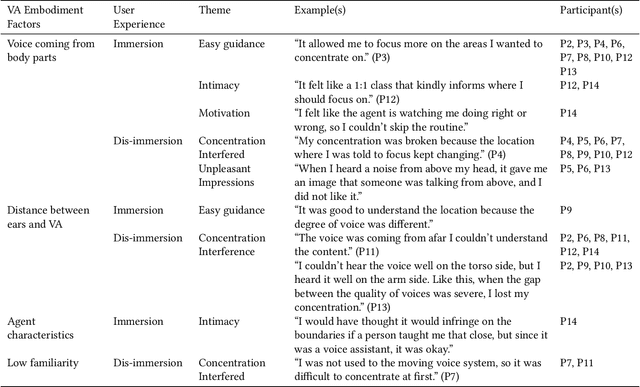

Mindfulness meditation is a validated means of helping people manage stress. Voice-based virtual assistants (VAs) in smart speakers, smartphones, and smart environments can assist people in carrying out mindfulness meditation through guided experiences. However, the common fixed location embodiment of VAs makes it difficult to provide intuitive support. In this work, we explored the novel embodiment of a "wandering voice" that is co-located with the user and "moves" with the task. We developed a multi-speaker VA embedded in a yoga mat that changes location along the body according to the meditation experience. We conducted a qualitative user study in two sessions, comparing a typical fixed smart speaker to the wandering VA embodiment. Thick descriptions from interviews with twelve people revealed sometimes simultaneous experiences of immersion and dis-immersion. We offer design implications for "wandering voices" and a new paradigm for VA embodiment that may extend to guidance tasks in other contexts.
* 6 pages
Transcending the "Male Code": Implicit Masculine Biases in NLP Contexts
Apr 22, 2023
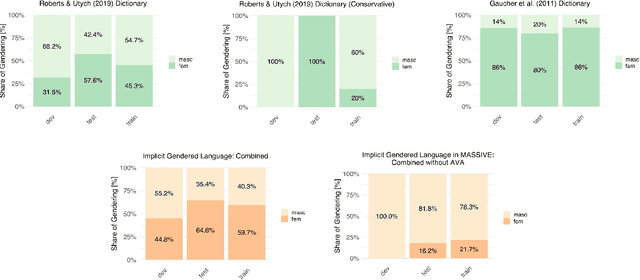
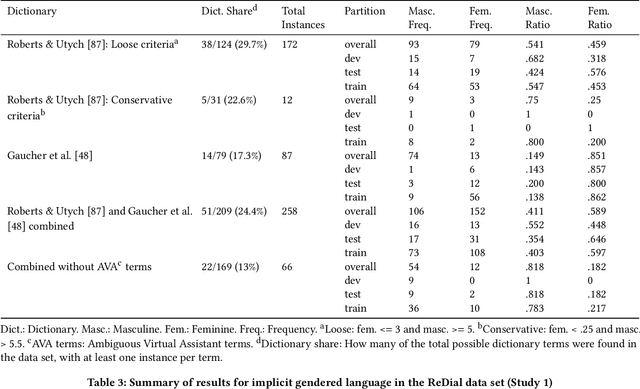
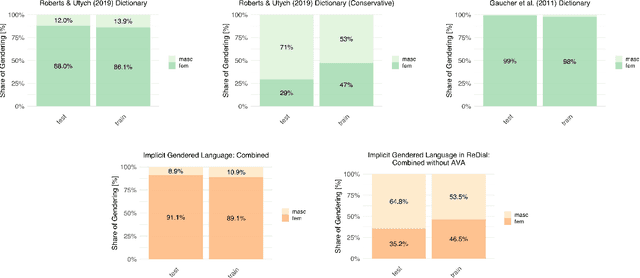
Critical scholarship has elevated the problem of gender bias in data sets used to train virtual assistants (VAs). Most work has focused on explicit biases in language, especially against women, girls, femme-identifying people, and genderqueer folk; implicit associations through word embeddings; and limited models of gender and masculinities, especially toxic masculinities, conflation of sex and gender, and a sex/gender binary framing of the masculine as diametric to the feminine. Yet, we must also interrogate how masculinities are "coded" into language and the assumption of "male" as the linguistic default: implicit masculine biases. To this end, we examined two natural language processing (NLP) data sets. We found that when gendered language was present, so were gender biases and especially masculine biases. Moreover, these biases related in nuanced ways to the NLP context. We offer a new dictionary called AVA that covers ambiguous associations between gendered language and the language of VAs.
* 19 pages