 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscending the "Male Code": Implicit Masculine Biases in NLP Contexts
Apr 22, 2023
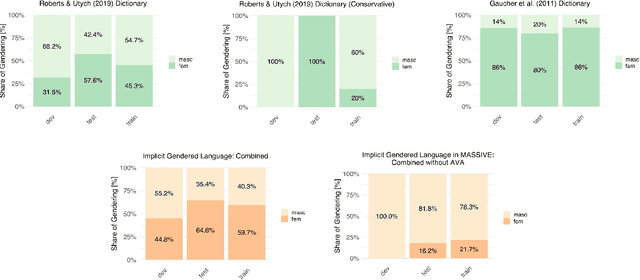
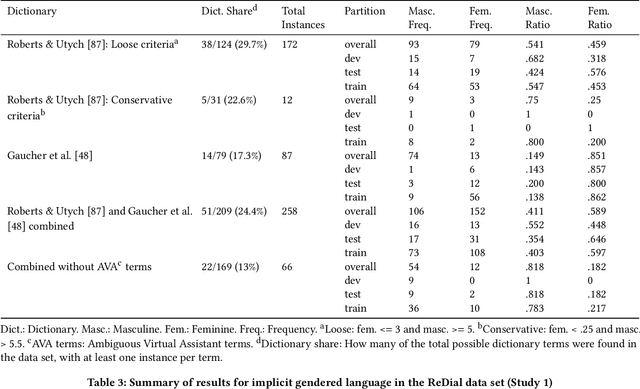
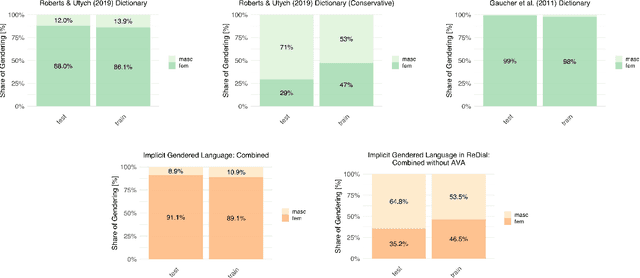
Critical scholarship has elevated the problem of gender bias in data sets used to train virtual assistants (VAs). Most work has focused on explicit biases in language, especially against women, girls, femme-identifying people, and genderqueer folk; implicit associations through word embeddings; and limited models of gender and masculinities, especially toxic masculinities, conflation of sex and gender, and a sex/gender binary framing of the masculine as diametric to the feminine. Yet, we must also interrogate how masculinities are "coded" into language and the assumption of "male" as the linguistic default: implicit masculine biases. To this end, we examined two natural language processing (NLP) data sets. We found that when gendered language was present, so were gender biases and especially masculine biases. Moreover, these biases related in nuanced ways to the NLP context. We offer a new dictionary called AVA that covers ambiguous associations between gendered language and the language of VAs.
* 19 pages