 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Reliability of Watermarks for Large Language Models
Jun 30, 2023



As LLMs become commonplace, machine-generated text has the potential to flood the internet with spam, social media bots, and valueless content. Watermarking is a simple and effective strategy for mitigating such harms by enabling the detection and documentation of LLM-generated text. Yet a crucial question remains: How reliable is watermarking in realistic settings in the wild? There, watermarked text may be modified to suit a user's needs, or entirely rewritten to avoid detection. We study the robustness of watermarked text after it is re-written by humans, paraphrased by a non-watermarked LLM, or mixed into a longer hand-written document. We find that watermarks remain detectable even after human and machine paraphrasing. While these attacks dilute the strength of the watermark, paraphrases are statistically likely to leak n-grams or even longer fragments of the original text, resulting in high-confidence detections when enough tokens are observed. For example, after strong human paraphrasing the watermark is detectable after observing 800 tokens on average, when setting a 1e-5 false positive rate. We also consider a range of new detection schemes that are sensitive to short spans of watermarked text embedded inside a large document, and we compare the robustness of watermarking to other kinds of detectors.
Robust normalizing flows using Bernstein-type polynomials
Feb 06, 2021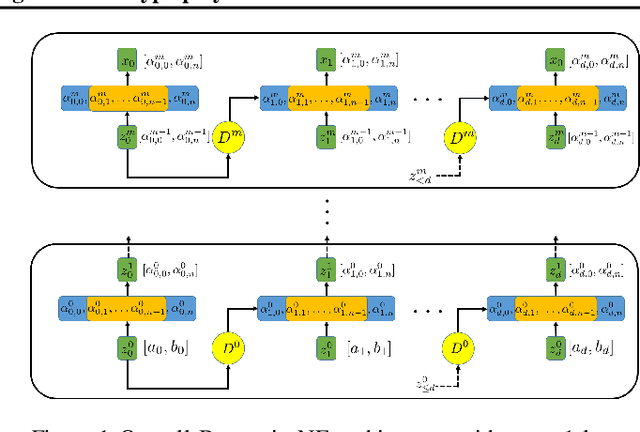
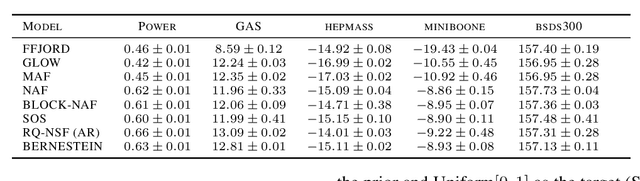
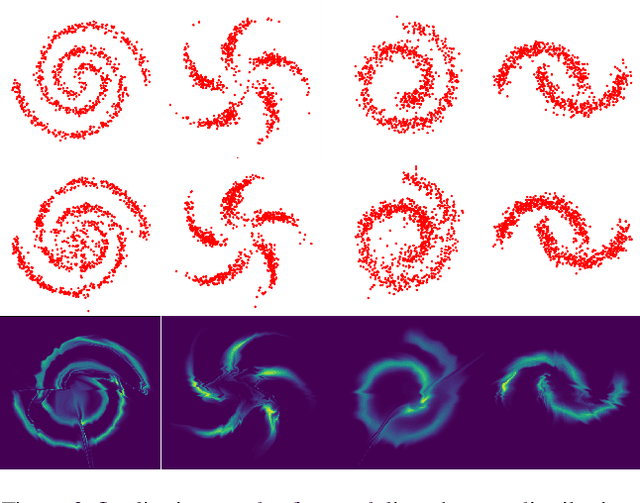
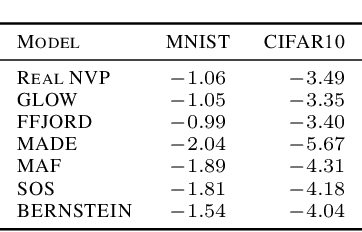
Normalizing flows (NFs) are a class of generative models that allows exact density evaluation and sampling. We propose a framework to construct NFs based on increasing triangular maps and Bernstein-type polynomials. Compared to the existing (universal) NF frameworks, our method provides compelling advantages like theoretical upper bounds for the approximation error, robustness, higher interpretability, suitability for compactly supported densities, and the ability to employ higher degree polynomials without training instability. Moreover, we provide a constructive universality proof, which gives analytic expressions of the approximations for known transformations. We conduct a thorough theoretical analysis and empirically demonstrate the efficacy of the proposed technique using experiments on both real-world and synthetic datasets.