 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-Information Harvesting from Social Media Data
Nov 01, 2022As unconventional sources of geo-information, massive imagery and text messages from open platforms and social media form a temporally quasi-seamless, spatially multi-perspective stream, but with unknown and diverse quality. Due to its complementarity to remote sensing data, geo-information from these sources offers promising perspectives, but harvesting is not trivial due to its data characteristics. In this article, we address key aspects in the field, including data availability, analysis-ready data preparation and data management, geo-information extraction from social media text messages and images, and the fusion of social media and remote sensing data. We then showcase some exemplary geographic applications. In addition, we present the first extensive discussion of ethical considerations of social media data in the context of geo-information harvesting and geographic applications. With this effort, we wish to stimulate curiosity and lay the groundwork for researchers who intend to explore social media data for geo-applications. We encourage the community to join forces by sharing their code and data.
Using Social Media Images for Building Function Classification
Feb 15, 2022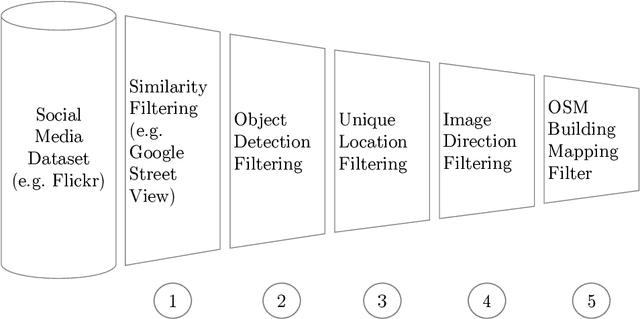
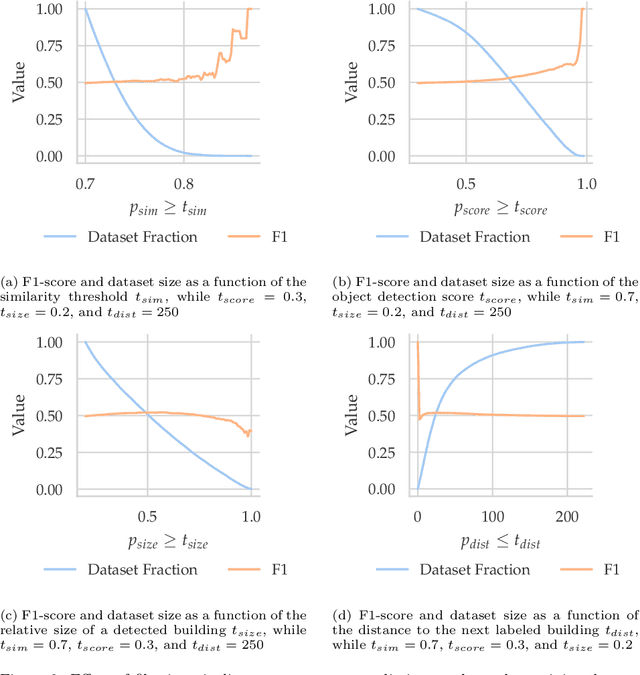
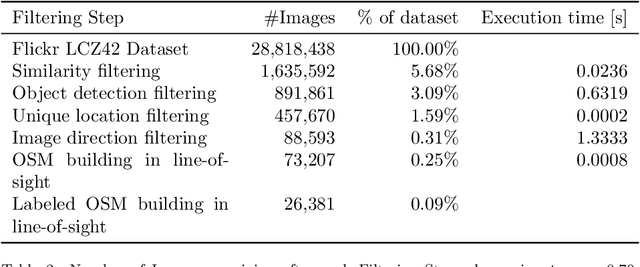
Urban land use on a building instance level is crucial geo-information for many applications, yet difficult to obtain. An intuitive approach to close this gap is predicting building functions from ground level imagery. Social media image platforms contain billions of images, with a large variety of motifs including but not limited to street perspectives. To cope with this issue this study proposes a filtering pipeline to yield high quality, ground level imagery from large social media image datasets. The pipeline ensures that all resulting images have full and valid geotags with a compass direction to relate image content and spatial objects from maps. We analyze our method on a culturally diverse social media dataset from Flickr with more than 28 million images from 42 cities around the world. The obtained dataset is then evaluated in a context of 3-classes building function classification task. The three building classes that are considered in this study are: commercial, residential, and other. Fine-tuned state-of-the-art architectures yield F1-scores of up to 0.51 on the filtered images. Our analysis shows that the performance is highly limited by the quality of the labels obtained from OpenStreetMap, as the metrics increase by 0.2 if only human validated labels are considered. Therefore, we consider these labels to be weak and publish the resulting images from our pipeline together with the buildings they are showing as a weakly labeled dataset.
Concept Embedding for Information Retrieval
Feb 01, 2020
Concepts are used to solve the term-mismatch problem. However, we need an effective similarity measure between concepts. Word embedding presents a promising solution. We present in this study three approaches to build concepts vectors based on words vectors. We use a vector-based measure to estimate inter-concepts similarity. Our experiments show promising results. Furthermore, words and concepts become comparable. This could be used to improve conceptual indexing process.