 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Galaxy Images
Apr 03, 2024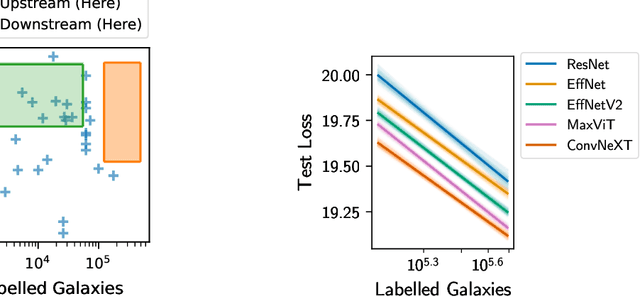
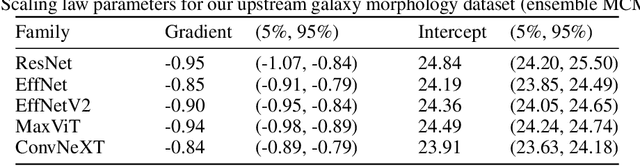
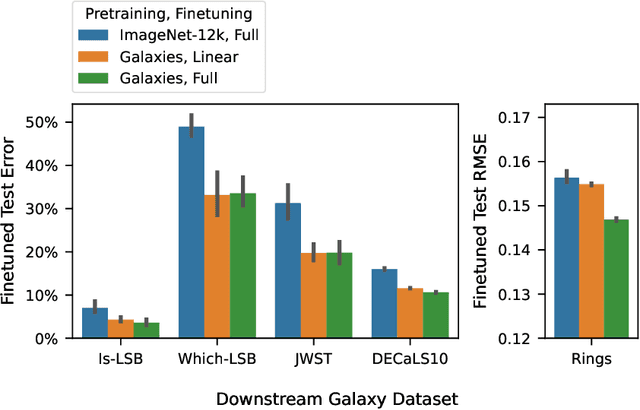
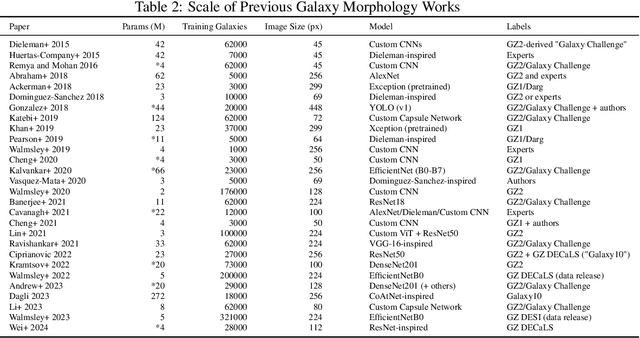
We present the first systematic investigation of supervised scaling laws outside of an ImageNet-like context - on images of galaxies. We use 840k galaxy images and over 100M annotations by Galaxy Zoo volunteers, comparable in scale to Imagenet-1K. We find that adding annotated galaxy images provides a power law improvement in performance across all architectures and all tasks, while adding trainable parameters is effective only for some (typically more subjectively challenging) tasks. We then compare the downstream performance of finetuned models pretrained on either ImageNet-12k alone vs. additionally pretrained on our galaxy images. We achieve an average relative error rate reduction of 31% across 5 downstream tasks of scientific interest. Our finetuned models are more label-efficient and, unlike their ImageNet-12k-pretrained equivalents, often achieve linear transfer performance equal to that of end-to-end finetuning. We find relatively modest additional downstream benefits from scaling model size, implying that scaling alone is not sufficient to address our domain gap, and suggest that practitioners with qualitatively different images might benefit more from in-domain adaption followed by targeted downstream labelling.
TCuPGAN: A novel framework developed for optimizing human-machine interactions in citizen science
Nov 23, 2023In the era of big data in scientific research, there is a necessity to leverage techniques which reduce human effort in labeling and categorizing large datasets by involving sophisticated machine tools. To combat this problem, we present a novel, general purpose model for 3D segmentation that leverages patch-wise adversariality and Long Short-Term Memory to encode sequential information. Using this model alongside citizen science projects which use 3D datasets (image cubes) on the Zooniverse platforms, we propose an iterative human-machine optimization framework where only a fraction of the 2D slices from these cubes are seen by the volunteers. We leverage the patch-wise discriminator in our model to provide an estimate of which slices within these image cubes have poorly generalized feature representations, and correspondingly poor machine performance. These images with corresponding machine proposals would be presented to volunteers on Zooniverse for correction, leading to a drastic reduction in the volunteer effort on citizen science projects. We trained our model on ~2300 liver tissue 3D electron micrographs. Lipid droplets were segmented within these images through human annotation via the `Etch A Cell - Fat Checker' citizen science project, hosted on the Zooniverse platform. In this work, we demonstrate this framework and the selection methodology which resulted in a measured reduction in volunteer effort by more than 60%. We envision this type of joint human-machine partnership will be of great use on future Zooniverse projects.