 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJU_KS@SAIL_CodeMixed-2017: Sentiment Analysis for Indian Code Mixed Social Media Texts
Feb 15, 2018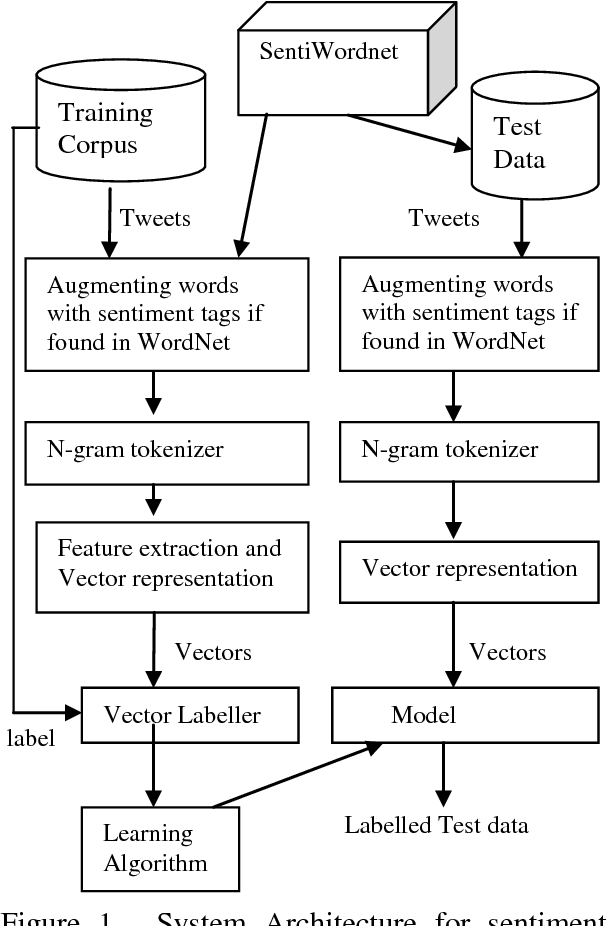
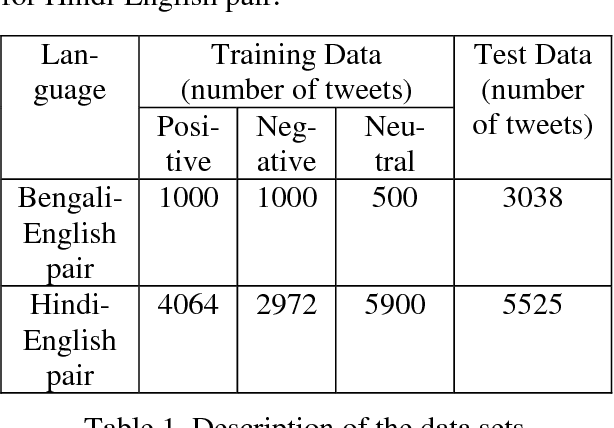
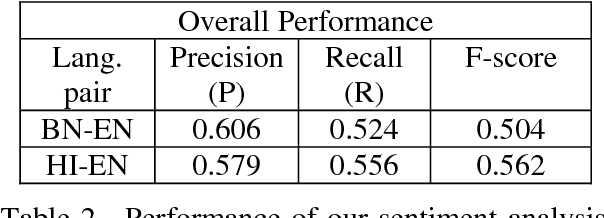
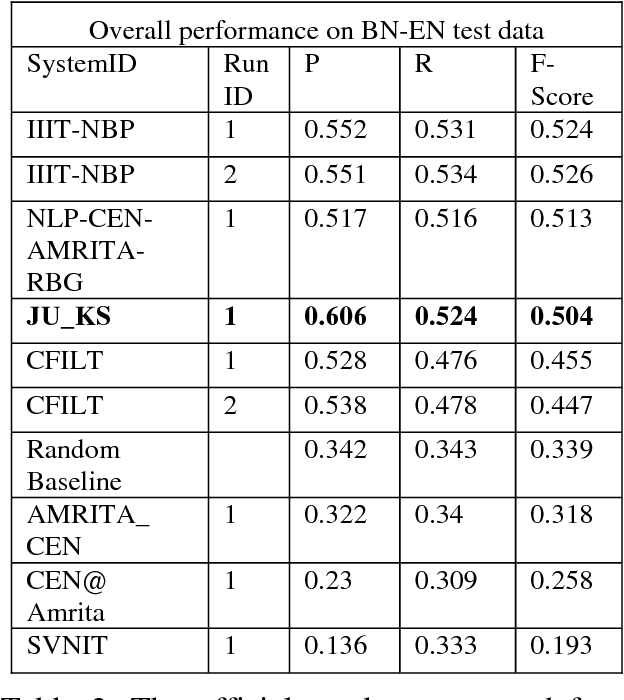
This paper reports about our work in the NLP Tool Contest @ICON-2017, shared task on Sentiment Analysis for Indian Languages (SAIL) (code mixed). To implement our system, we have used a machine learning algo-rithm called Multinomial Na\"ive Bayes trained using n-gram and SentiWordnet features. We have also used a small SentiWordnet for English and a small SentiWordnet for Bengali. But we have not used any SentiWordnet for Hindi language. We have tested our system on Hindi-English and Bengali-English code mixed social media data sets released for the contest. The performance of our system is very close to the best system participated in the contest. For both Bengali-English and Hindi-English runs, our system was ranked at the 3rd position out of all submitted runs and awarded the 3rd prize in the contest.
* NLP Tool Contest on Sentiment Analysis for Indian Languages (Code Mixed) held in conjunction with the 14th International Conference on Natural Language Processing, 2017
JU_KS_Group@FIRE 2016: Consumer Health Information Search
Dec 24, 2016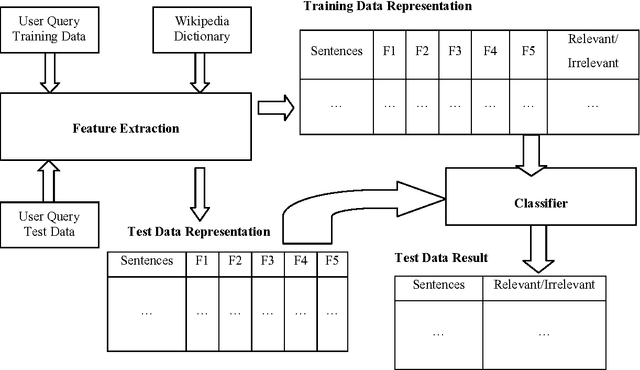
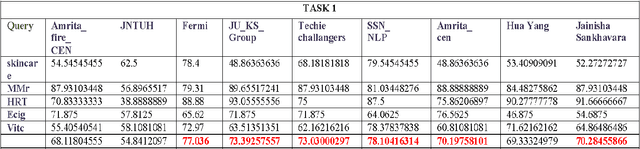
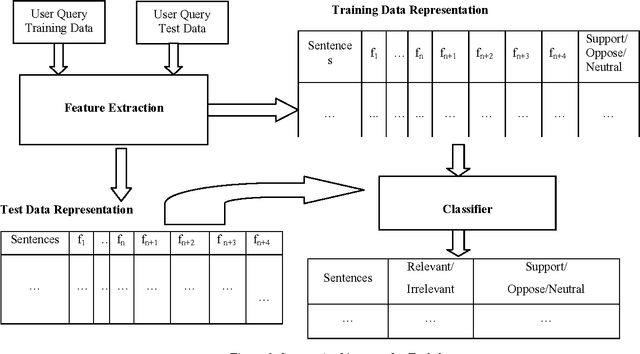
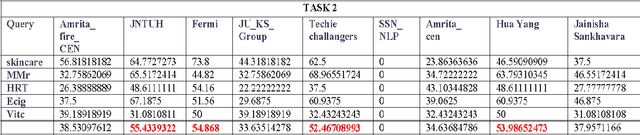
In this paper, we describe the methodology used and the results obtained by us for completing the tasks given under the shared task on Consumer Health Information Search (CHIS) collocated with the Forum for Information Retrieval Evaluation (FIRE) 2016, ISI Kolkata. The shared task consists of two sub-tasks - (1) task1: given a query and a document/set of documents associated with that query, the task is to classify the sentences in the document as relevant to the query or not and (2) task 2: the relevant sentences need to be further classified as supporting the claim made in the query, or opposing the claim made in the query. We have participated in both the sub-tasks. The percentage accuracy obtained by our developed system for task1 was 73.39 which is third highest among the 9 teams participated in the shared task.
KS_JU@DPIL-FIRE2016:Detecting Paraphrases in Indian Languages Using Multinomial Logistic Regression Model
Dec 24, 2016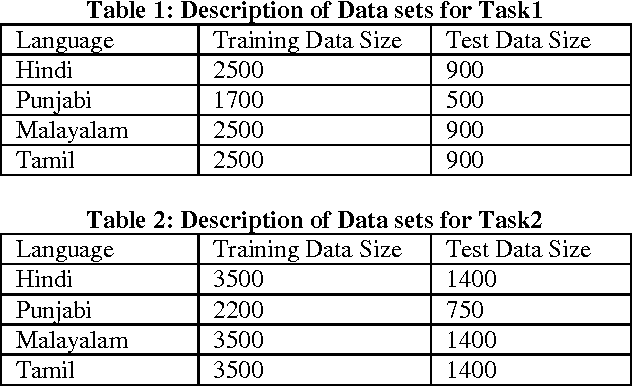
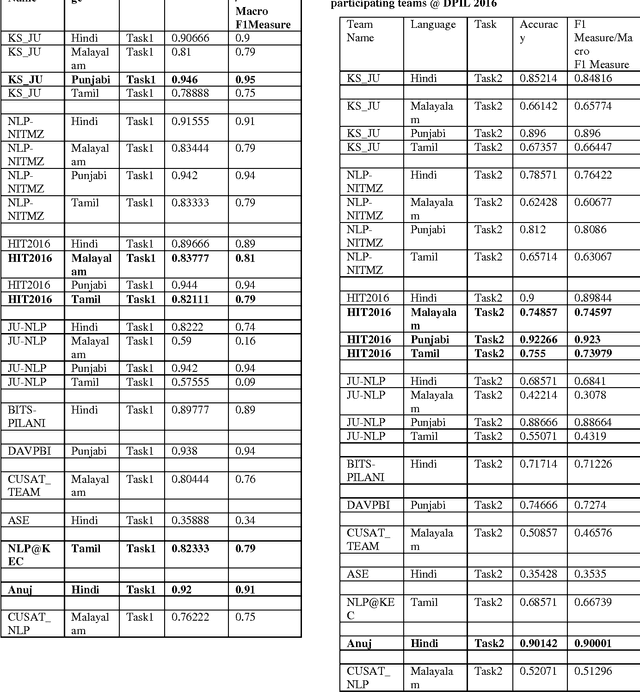
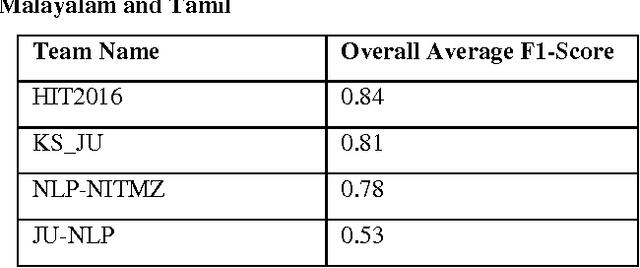
In this work, we describe a system that detects paraphrases in Indian Languages as part of our participation in the shared Task on detecting paraphrases in Indian Languages (DPIL) organized by Forum for Information Retrieval Evaluation (FIRE) in 2016. Our paraphrase detection method uses a multinomial logistic regression model trained with a variety of features which are basically lexical and semantic level similarities between two sentences in a pair. The performance of the system has been evaluated against the test set released for the FIRE 2016 shared task on DPIL. Our system achieves the highest f-measure of 0.95 on task1 in Punjabi language.The performance of our system on task1 in Hindi language is f-measure of 0.90. Out of 11 teams participated in the shared task, only four teams participated in all four languages, Hindi, Punjabi, Malayalam and Tamil, but the remaining 7 teams participated in one of the four languages. We also participated in task1 and task2 both for all four Indian Languages. The overall average performance of our system including task1 and task2 overall four languages is F1-score of 0.81 which is the second highest score among the four systems that participated in all four languages.
A CRF Based POS Tagger for Code-mixed Indian Social Media Text
Dec 23, 2016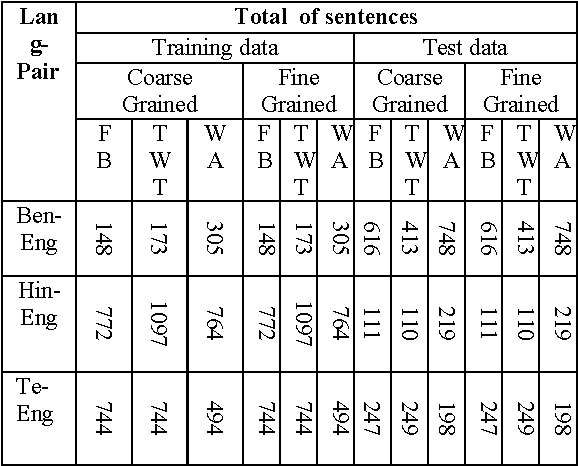
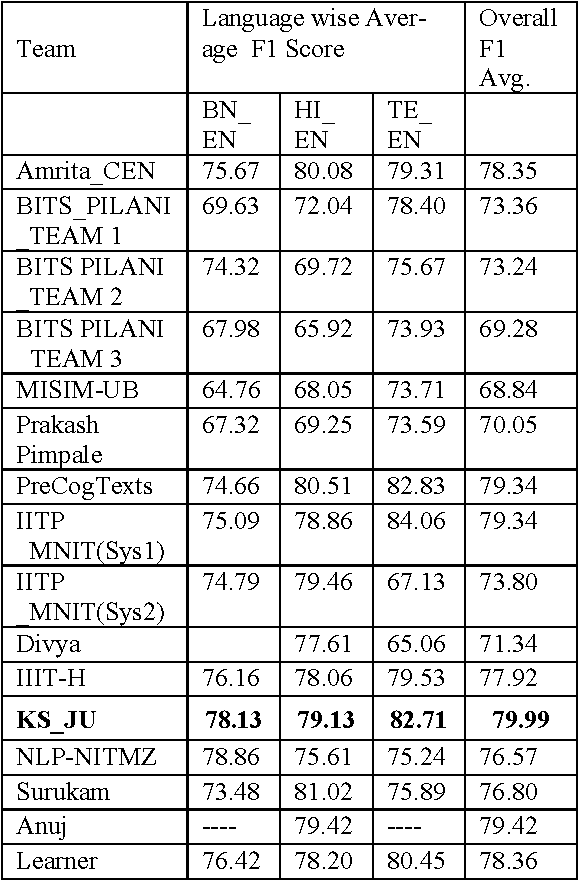
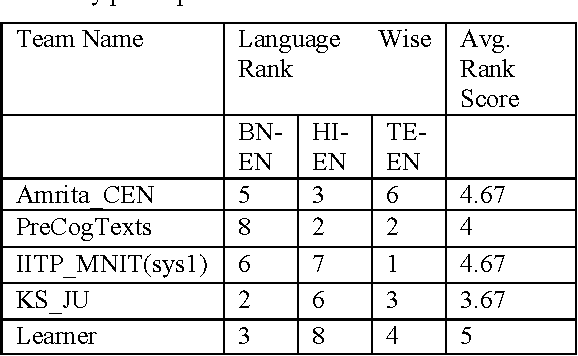
In this work, we describe a conditional random fields (CRF) based system for Part-Of- Speech (POS) tagging of code-mixed Indian social media text as part of our participation in the tool contest on POS tagging for codemixed Indian social media text, held in conjunction with the 2016 International Conference on Natural Language Processing, IIT(BHU), India. We participated only in constrained mode contest for all three language pairs, Bengali-English, Hindi-English and Telegu-English. Our system achieves the overall average F1 score of 79.99, which is the highest overall average F1 score among all 16 systems participated in constrained mode contest.
Part-of-Speech Tagging for Code-mixed Indian Social Media Text at ICON 2015
Jan 06, 2016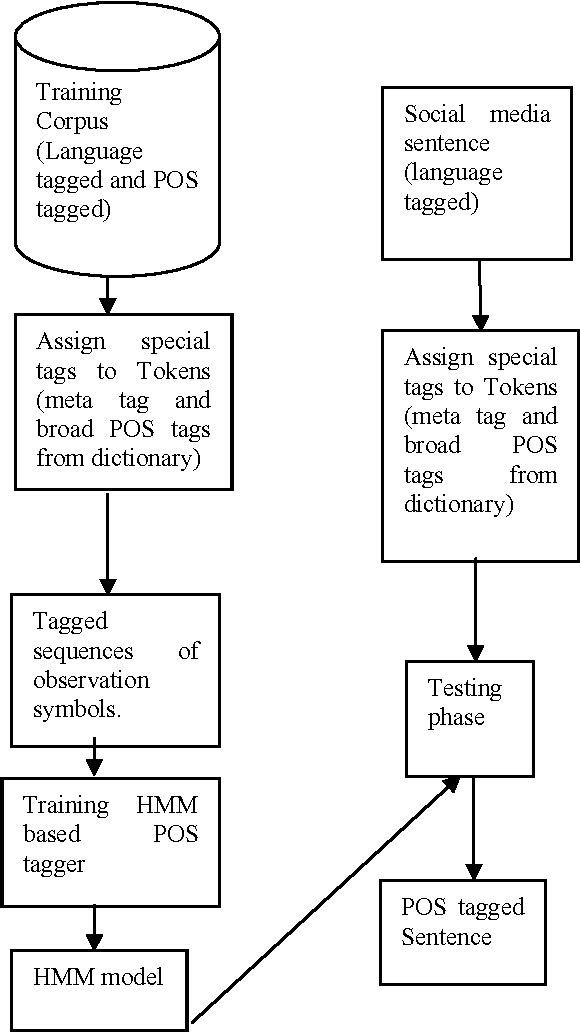
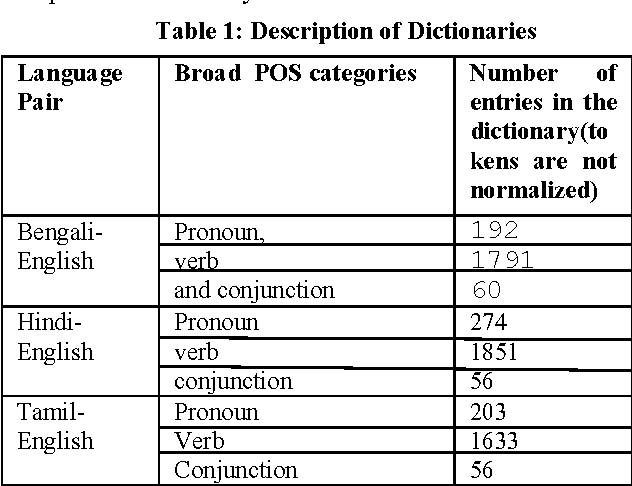
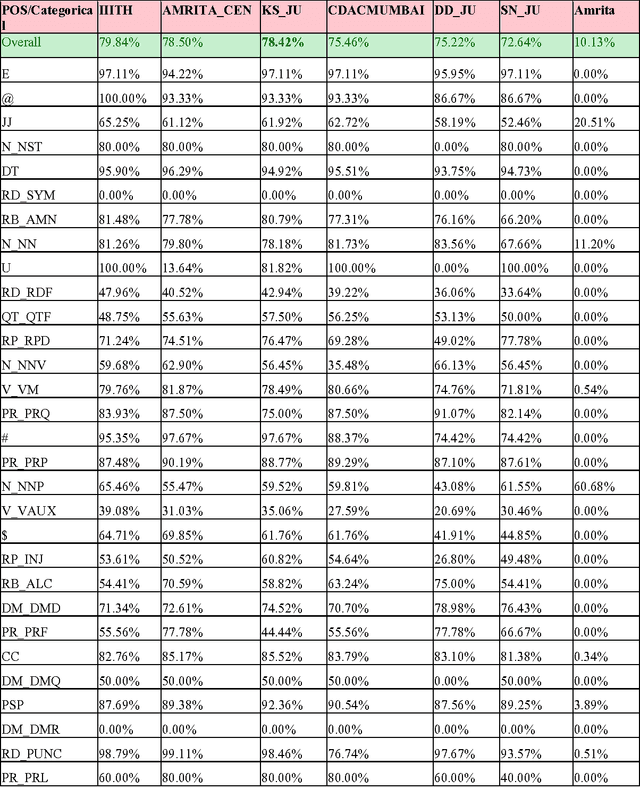
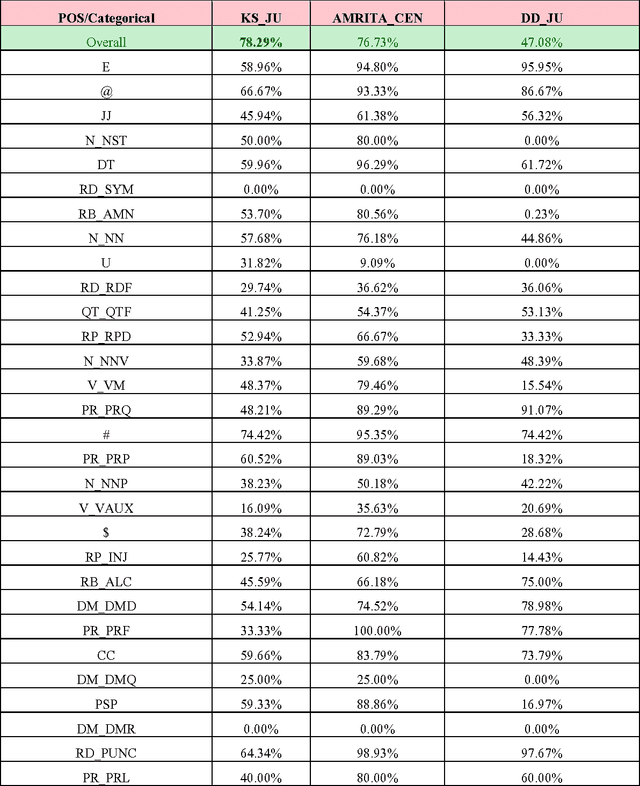
This paper discusses the experiments carried out by us at Jadavpur University as part of the participation in ICON 2015 task: POS Tagging for Code-mixed Indian Social Media Text. The tool that we have developed for the task is based on Trigram Hidden Markov Model that utilizes information from dictionary as well as some other word level features to enhance the observation probabilities of the known tokens as well as unknown tokens. We submitted runs for Bengali-English, Hindi-English and Tamil-English Language pairs. Our system has been trained and tested on the datasets released for ICON 2015 shared task: POS Tagging For Code-mixed Indian Social Media Text. In constrained mode, our system obtains average overall accuracy (averaged over all three language pairs) of 75.60% which is very close to other participating two systems (76.79% for IIITH and 75.79% for AMRITA_CEN) ranked higher than our system. In unconstrained mode, our system obtains average overall accuracy of 70.65% which is also close to the system (72.85% for AMRITA_CEN) which obtains the highest average overall accuracy.
A Hidden Markov Model Based System for Entity Extraction from Social Media English Text at FIRE 2015
Dec 12, 2015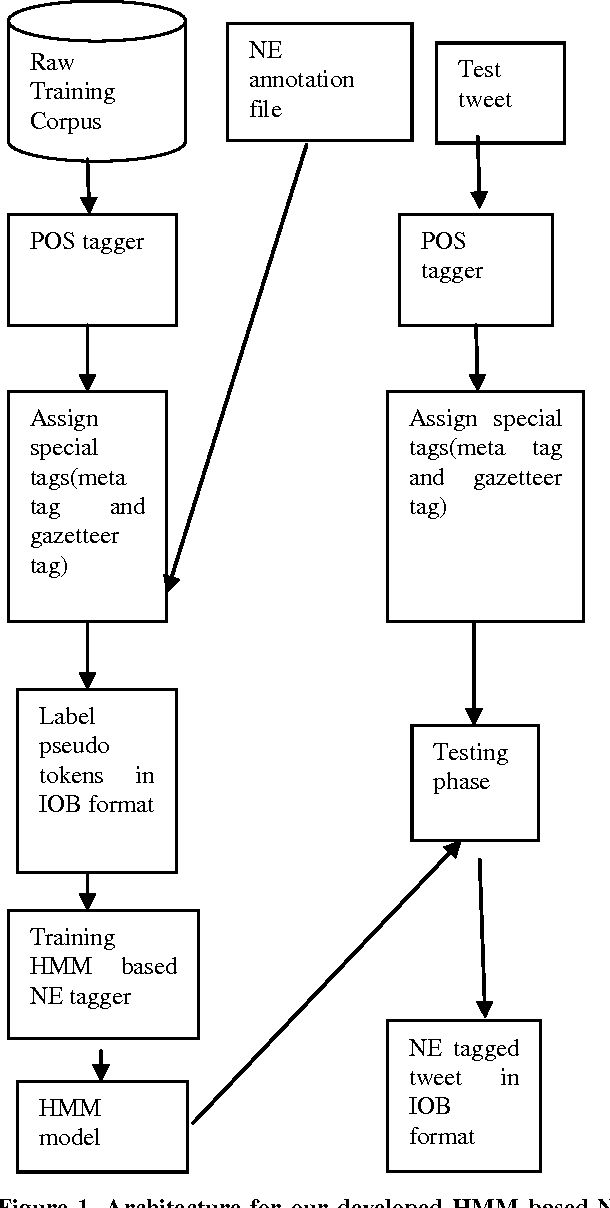
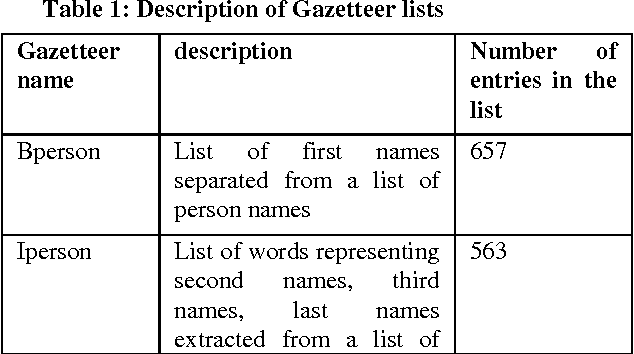
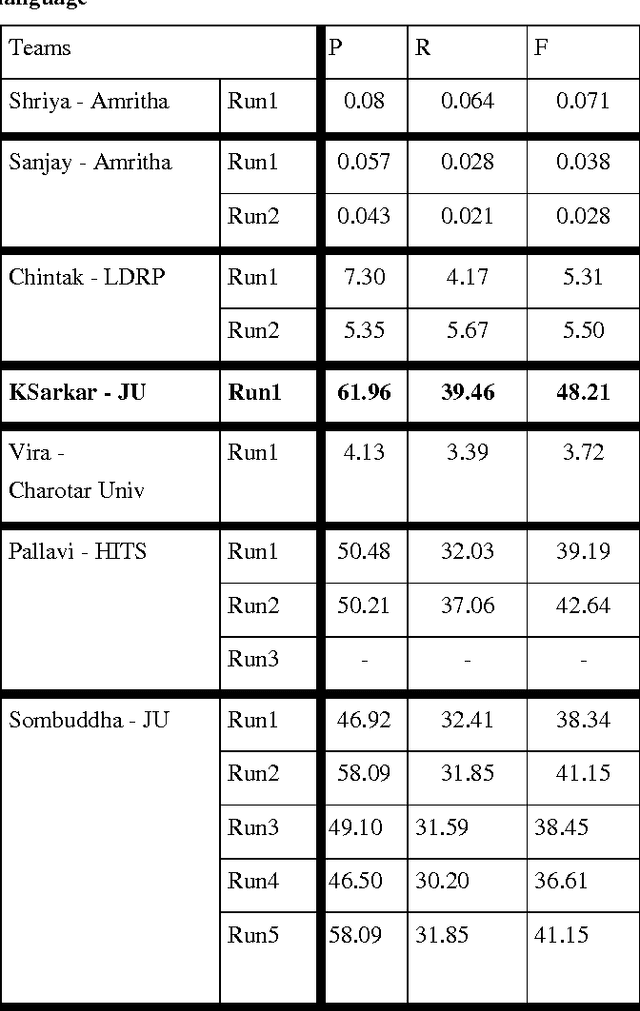
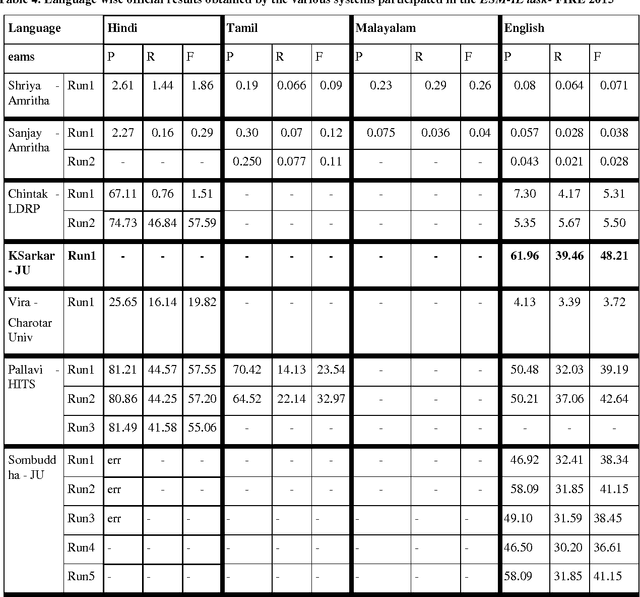
This paper presents the experiments carried out by us at Jadavpur University as part of the participation in FIRE 2015 task: Entity Extraction from Social Media Text - Indian Languages (ESM-IL). The tool that we have developed for the task is based on Trigram Hidden Markov Model that utilizes information like gazetteer list, POS tag and some other word level features to enhance the observation probabilities of the known tokens as well as unknown tokens. We submitted runs for English only. A statistical HMM (Hidden Markov Models) based model has been used to implement our system. The system has been trained and tested on the datasets released for FIRE 2015 task: Entity Extraction from Social Media Text - Indian Languages (ESM-IL). Our system is the best performer for English language and it obtains precision, recall and F-measures of 61.96, 39.46 and 48.21 respectively.
An HMM Based Named Entity Recognition System for Indian Languages: The JU System at ICON 2013
May 28, 2014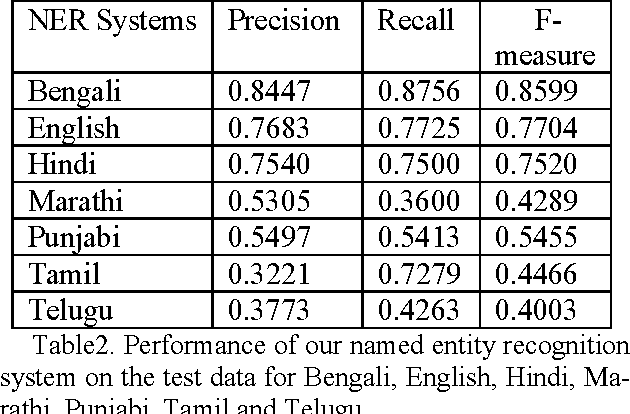
This paper reports about our work in the ICON 2013 NLP TOOLS CONTEST on Named Entity Recognition. We submitted runs for Bengali, English, Hindi, Marathi, Punjabi, Tamil and Telugu. A statistical HMM (Hidden Markov Models) based model has been used to implement our system. The system has been trained and tested on the NLP TOOLS CONTEST: ICON 2013 datasets. Our system obtains F-measures of 0.8599, 0.7704, 0.7520, 0.4289, 0.5455, 0.4466, and 0.4003 for Bengali, English, Hindi, Marathi, Punjabi, Tamil and Telugu respectively.
A Machine Learning Approach for the Identification of Bengali Noun-Noun Compound Multiword Expressions
Jan 25, 2014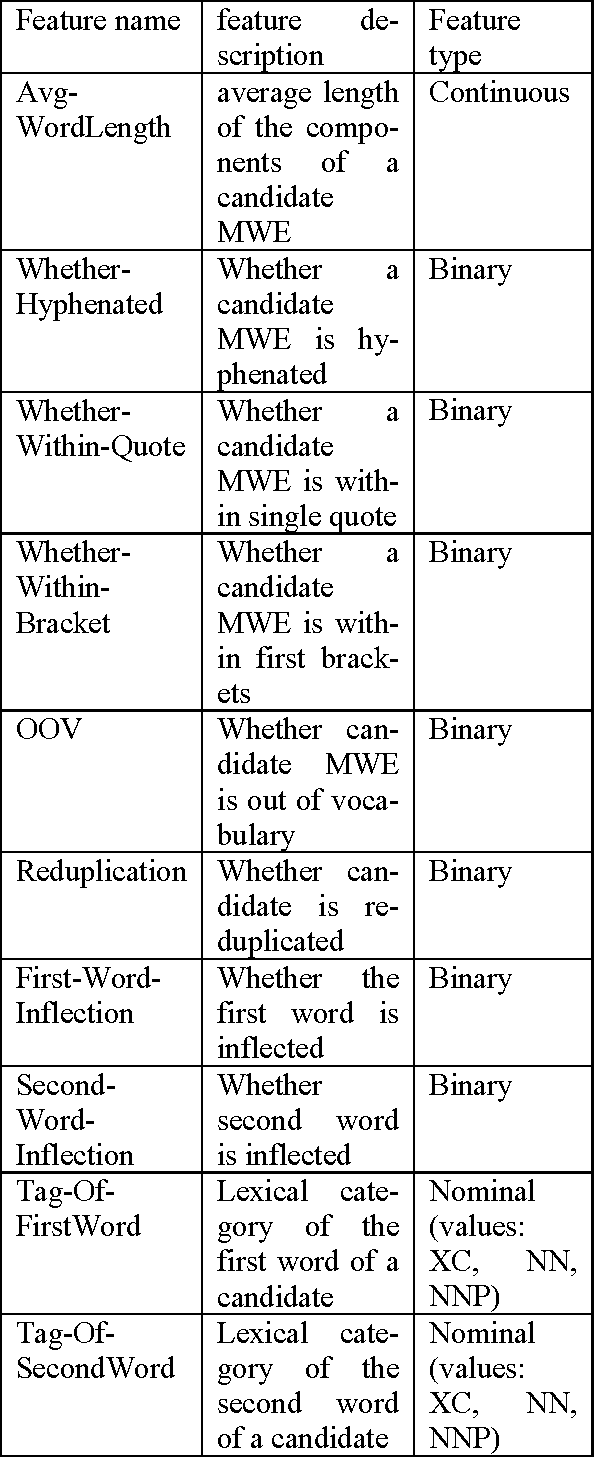


This paper presents a machine learning approach for identification of Bengali multiword expressions (MWE) which are bigram nominal compounds. Our proposed approach has two steps: (1) candidate extraction using chunk information and various heuristic rules and (2) training the machine learning algorithm called Random Forest to classify the candidates into two groups: bigram nominal compound MWE or not bigram nominal compound MWE. A variety of association measures, syntactic and linguistic clues and a set of WordNet-based similarity features have been used for our MWE identification task. The approach presented in this paper can be used to identify bigram nominal compound MWE in Bengali running text.
A Hybrid Approach to Extract Keyphrases from Medical Documents
Jan 25, 2014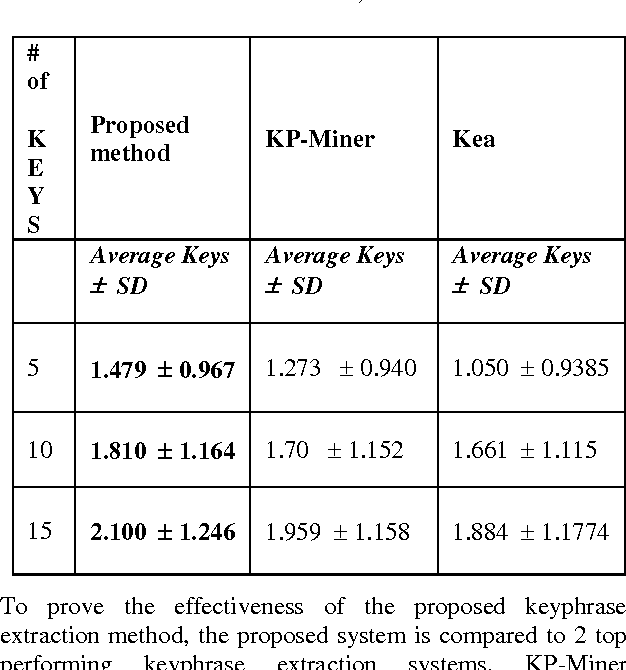
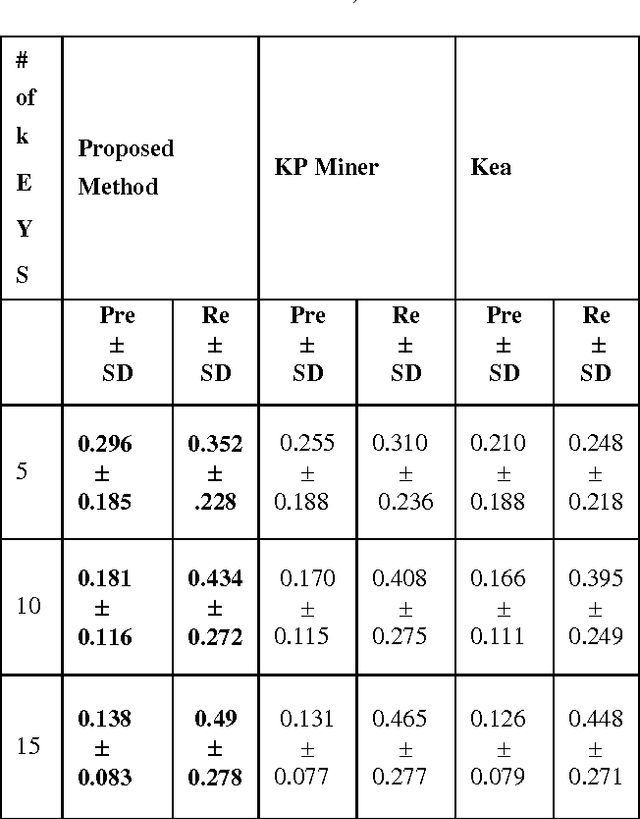
Keyphrases are the phrases, consisting of one or more words, representing the important concepts in the articles. Keyphrases are useful for a variety of tasks such as text summarization, automatic indexing, clustering/classification, text mining etc. This paper presents a hybrid approach to keyphrase extraction from medical documents. The keyphrase extraction approach presented in this paper is an amalgamation of two methods: the first one assigns weights to candidate keyphrases based on an effective combination of features such as position, term frequency, inverse document frequency and the second one assign weights to candidate keyphrases using some knowledge about their similarities to the structure and characteristics of keyphrases available in the memory (stored list of keyphrases). An efficient candidate keyphrase identification method as the first component of the proposed keyphrase extraction system has also been introduced in this paper. The experimental results show that the proposed hybrid approach performs better than some state-of-the art keyphrase extraction approaches.
Bengali text summarization by sentence extraction
Jan 11, 2012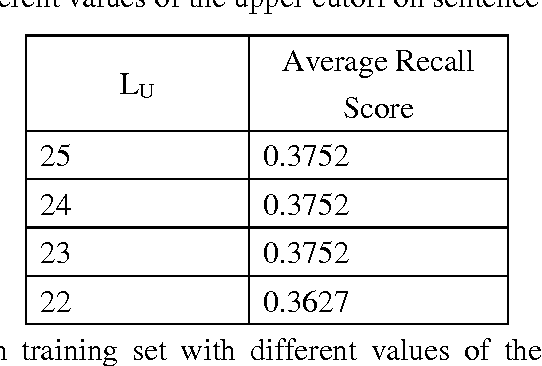
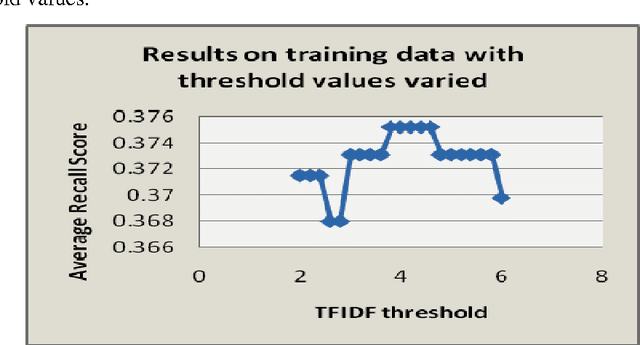
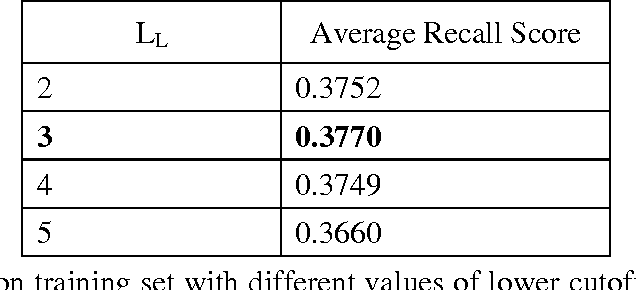
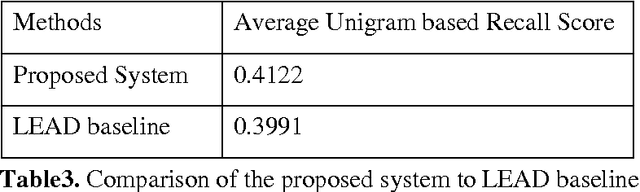
Text summarization is a process to produce an abstract or a summary by selecting significant portion of the information from one or more texts. In an automatic text summarization process, a text is given to the computer and the computer returns a shorter less redundant extract or abstract of the original text(s). Many techniques have been developed for summarizing English text(s). But, a very few attempts have been made for Bengali text summarization. This paper presents a method for Bengali text summarization which extracts important sentences from a Bengali document to produce a summary.