Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn HMM Based Named Entity Recognition System for Indian Languages: The JU System at ICON 2013
Paper and Code
May 28, 2014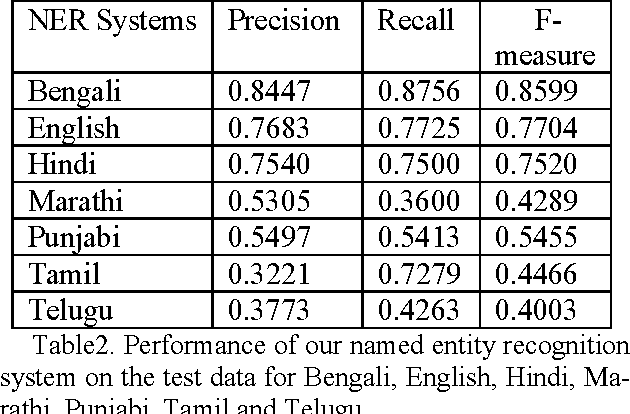
This paper reports about our work in the ICON 2013 NLP TOOLS CONTEST on Named Entity Recognition. We submitted runs for Bengali, English, Hindi, Marathi, Punjabi, Tamil and Telugu. A statistical HMM (Hidden Markov Models) based model has been used to implement our system. The system has been trained and tested on the NLP TOOLS CONTEST: ICON 2013 datasets. Our system obtains F-measures of 0.8599, 0.7704, 0.7520, 0.4289, 0.5455, 0.4466, and 0.4003 for Bengali, English, Hindi, Marathi, Punjabi, Tamil and Telugu respectively.
* The ICON 2013 tools contest on Named Entity Recognition in Indian
languages (IL) co-located with the 10th International Conference on Natural
Language Processing(ICON), CDAC Noida, India,18-20 December, 2013
View paper on