 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn HMM Based Named Entity Recognition System for Indian Languages: The JU System at ICON 2013
May 28, 2014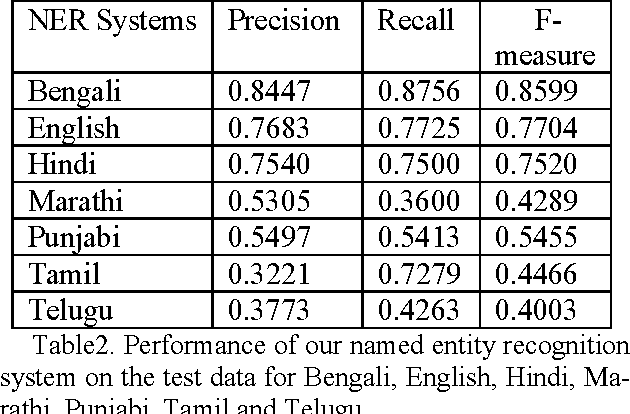
This paper reports about our work in the ICON 2013 NLP TOOLS CONTEST on Named Entity Recognition. We submitted runs for Bengali, English, Hindi, Marathi, Punjabi, Tamil and Telugu. A statistical HMM (Hidden Markov Models) based model has been used to implement our system. The system has been trained and tested on the NLP TOOLS CONTEST: ICON 2013 datasets. Our system obtains F-measures of 0.8599, 0.7704, 0.7520, 0.4289, 0.5455, 0.4466, and 0.4003 for Bengali, English, Hindi, Marathi, Punjabi, Tamil and Telugu respectively.
A Machine Learning Approach for the Identification of Bengali Noun-Noun Compound Multiword Expressions
Jan 25, 2014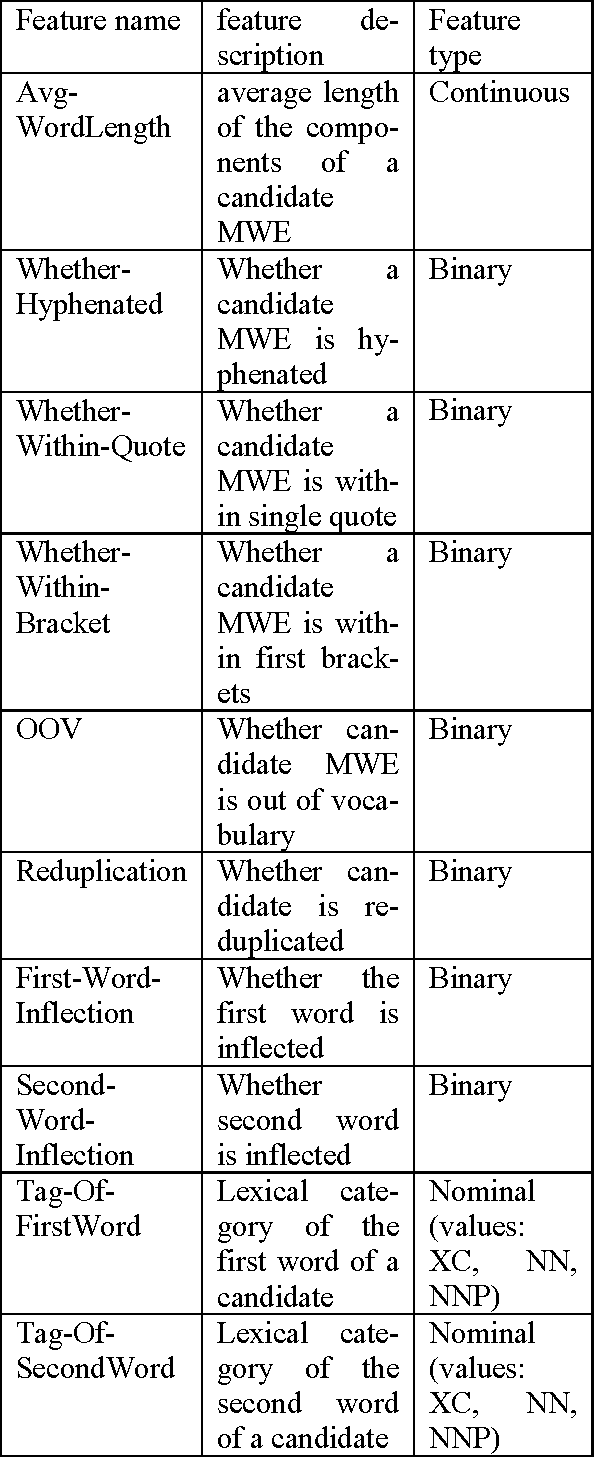


This paper presents a machine learning approach for identification of Bengali multiword expressions (MWE) which are bigram nominal compounds. Our proposed approach has two steps: (1) candidate extraction using chunk information and various heuristic rules and (2) training the machine learning algorithm called Random Forest to classify the candidates into two groups: bigram nominal compound MWE or not bigram nominal compound MWE. A variety of association measures, syntactic and linguistic clues and a set of WordNet-based similarity features have been used for our MWE identification task. The approach presented in this paper can be used to identify bigram nominal compound MWE in Bengali running text.