Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Approach for the Identification of Bengali Noun-Noun Compound Multiword Expressions
Paper and Code
Jan 25, 2014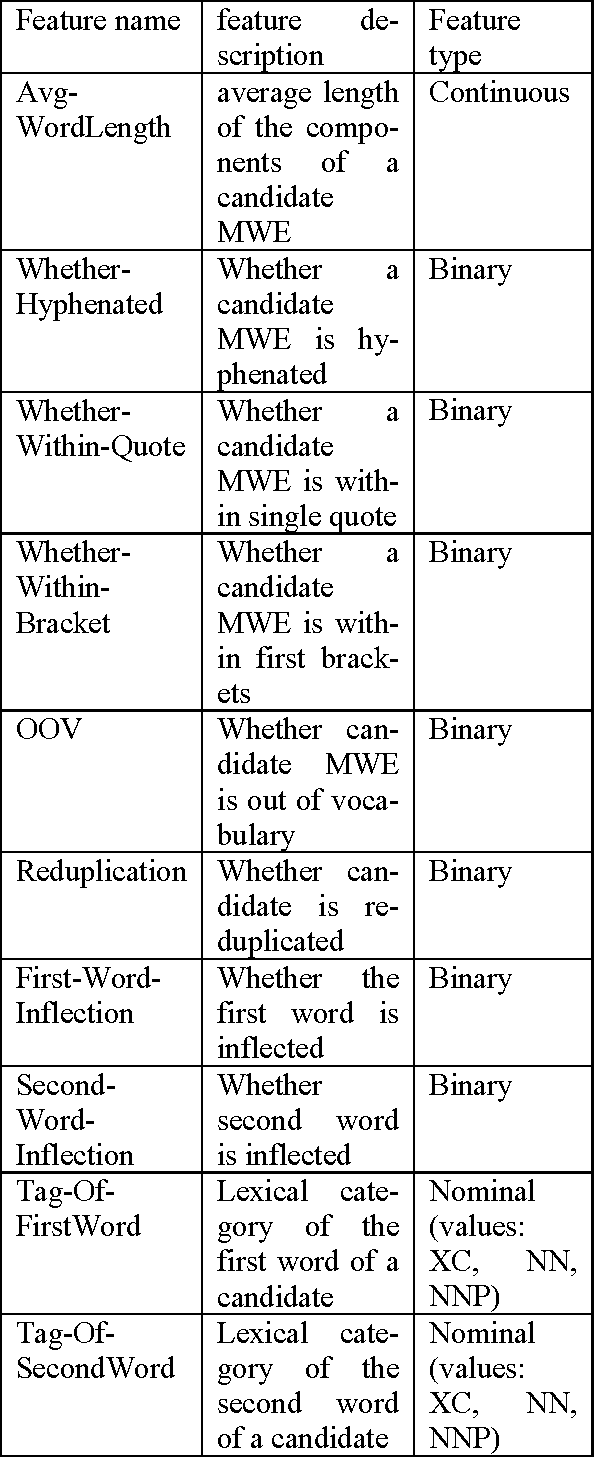


This paper presents a machine learning approach for identification of Bengali multiword expressions (MWE) which are bigram nominal compounds. Our proposed approach has two steps: (1) candidate extraction using chunk information and various heuristic rules and (2) training the machine learning algorithm called Random Forest to classify the candidates into two groups: bigram nominal compound MWE or not bigram nominal compound MWE. A variety of association measures, syntactic and linguistic clues and a set of WordNet-based similarity features have been used for our MWE identification task. The approach presented in this paper can be used to identify bigram nominal compound MWE in Bengali running text.
* In Proceedings of ICON-2013: 10th International Conference on
Natural Language Processing, pp 290-296
View paper on