 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Approach to Extract Keyphrases from Medical Documents
Paper and Code
Jan 25, 2014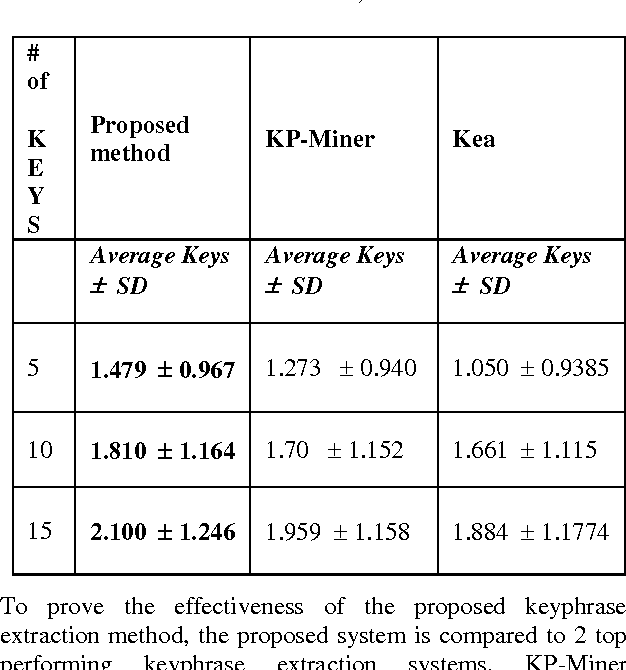
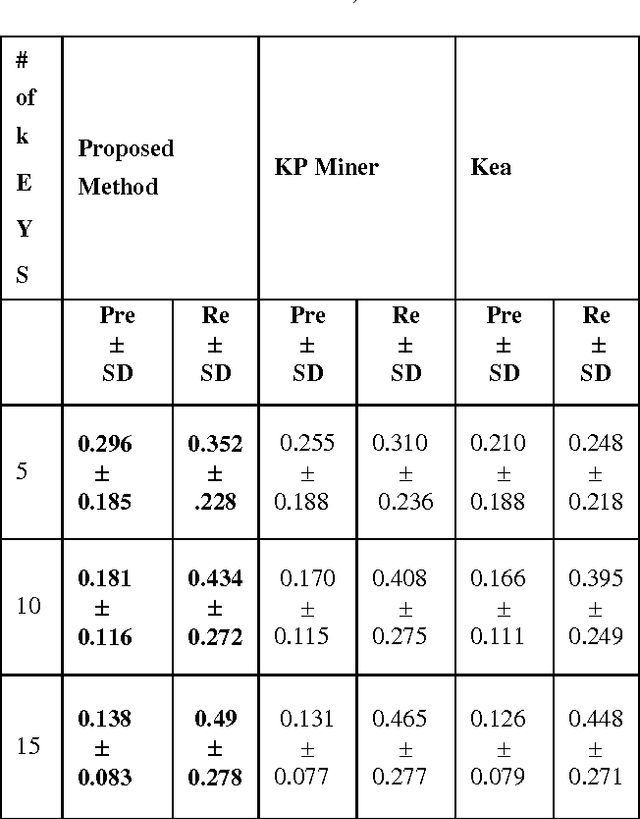
Keyphrases are the phrases, consisting of one or more words, representing the important concepts in the articles. Keyphrases are useful for a variety of tasks such as text summarization, automatic indexing, clustering/classification, text mining etc. This paper presents a hybrid approach to keyphrase extraction from medical documents. The keyphrase extraction approach presented in this paper is an amalgamation of two methods: the first one assigns weights to candidate keyphrases based on an effective combination of features such as position, term frequency, inverse document frequency and the second one assign weights to candidate keyphrases using some knowledge about their similarities to the structure and characteristics of keyphrases available in the memory (stored list of keyphrases). An efficient candidate keyphrase identification method as the first component of the proposed keyphrase extraction system has also been introduced in this paper. The experimental results show that the proposed hybrid approach performs better than some state-of-the art keyphrase extraction approaches.