 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArithmetic-Intensity-Guided Fault Tolerance for Neural Network Inference on GPUs
Apr 19, 2021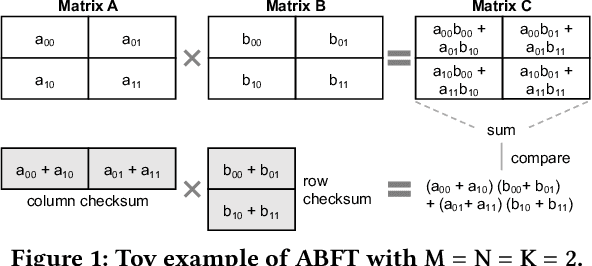
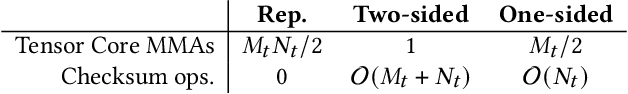
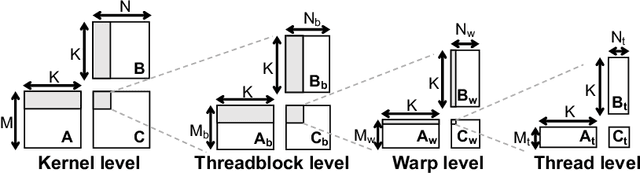
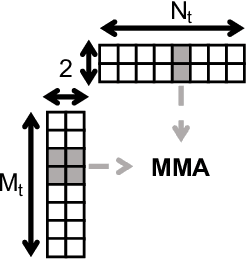
Neural networks (NNs) are increasingly employed in domains that require high reliability, such as scientific computing and safety-critical systems, as well as in environments more prone to unreliability (e.g., soft errors), such as on spacecraft. As recent work has shown that faults in NN inference can lead to mispredictions and safety hazards, it is critical to impart fault tolerance to NN inference. Algorithm-based fault tolerance (ABFT) is emerging as an appealing approach for efficient fault tolerance in NNs. In this work, we identify new, unexploited opportunities for low-overhead ABFT for NN inference: current inference-optimized GPUs have high compute-to-memory-bandwidth ratios, while many layers of current and emerging NNs have low arithmetic intensity. This leaves many convolutional and fully-connected layers in NNs memory-bandwidth-bound. These layers thus exhibit stalls in computation that could be filled by redundant execution, but that current approaches to ABFT for NN inference cannot exploit. To reduce execution-time overhead for such memory-bandwidth-bound layers, we first investigate thread-level ABFT schemes for inference-optimized GPUs that exploit this fine-grained compute underutilization. We then propose intensity-guided ABFT, an adaptive, arithmetic-intensity-guided approach to ABFT that selects the best ABFT scheme for each individual layer between traditional approaches to ABFT, which are suitable for compute-bound layers, and thread-level ABFT, which is suitable for memory-bandwidth-bound layers. Through this adaptive approach, intensity-guided ABFT reduces execution-time overhead by 1.09--5.3$\times$ across a variety of NNs, lowering the cost of fault tolerance for current and future NN inference workloads.
ECRM: Efficient Fault Tolerance for Recommendation Model Training via Erasure Coding
Apr 05, 2021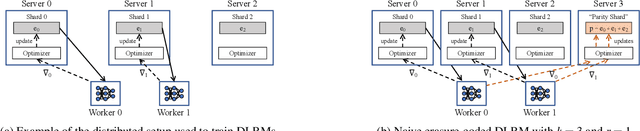

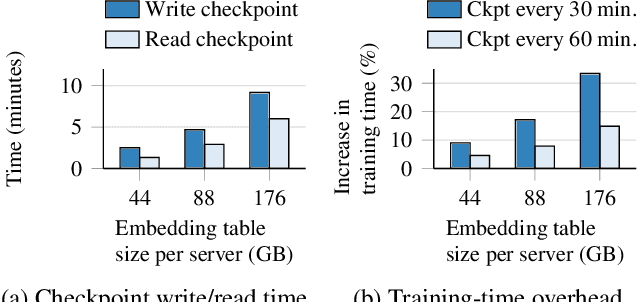
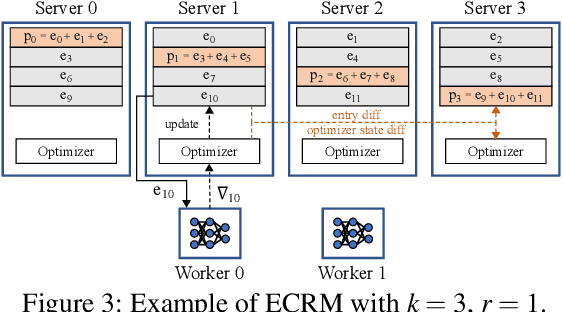
Deep-learning-based recommendation models (DLRMs) are widely deployed to serve personalized content to users. DLRMs are large in size due to their use of large embedding tables, and are trained by distributing the model across the memory of tens or hundreds of servers. Server failures are common in such large distributed systems and must be mitigated to enable training to progress. Checkpointing is the primary approach used for fault tolerance in these systems, but incurs significant training-time overhead both during normal operation and when recovering from failures. As these overheads increase with DLRM size, checkpointing is slated to become an even larger overhead for future DLRMs, which are expected to grow in size. This calls for rethinking fault tolerance in DLRM training. We present ECRM, a DLRM training system that achieves efficient fault tolerance using erasure coding. ECRM chooses which DLRM parameters to encode, correctly and efficiently updates parities, and enables training to proceed without any pauses, while maintaining consistency of the recovered parameters. We implement ECRM atop XDL, an open-source, industrial-scale DLRM training system. Compared to checkpointing, ECRM reduces training-time overhead for large DLRMs by up to 88%, recovers from failures up to 10.3$\times$ faster, and allows training to proceed during recovery. These results show the promise of erasure coding in imparting efficient fault tolerance to training current and future DLRMs.
Parity Models: A General Framework for Coding-Based Resilience in ML Inference
May 02, 2019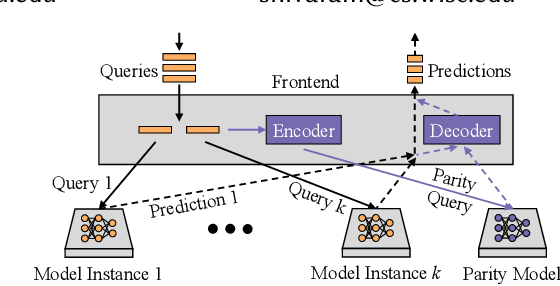
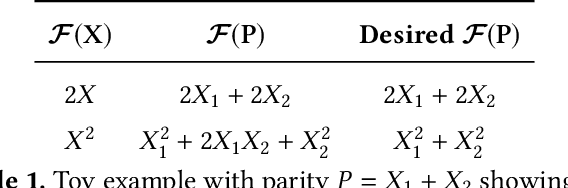
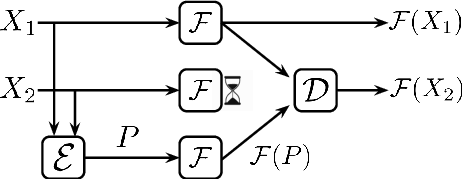
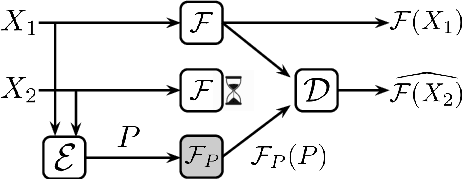
Machine learning models are becoming the primary workhorses for many applications. Production services deploy models through prediction serving systems that take in queries and return predictions by performing inference on machine learning models. In order to scale to high query rates, prediction serving systems are run on many machines in cluster settings, and thus are prone to slowdowns and failures that inflate tail latency and cause violations of strict latency targets. Current approaches to reducing tail latency are inadequate for the latency targets of prediction serving, incur high resource overhead, or are inapplicable to the computations performed during inference. We present ParM, a novel, general framework for making use of ideas from erasure coding and machine learning to achieve low-latency, resource-efficient resilience to slowdowns and failures in prediction serving systems. ParM encodes multiple queries together into a single parity query and performs inference on the parity query using a parity model. A decoder uses the output of a parity model to reconstruct approximations of unavailable predictions. ParM uses neural networks to learn parity models that enable simple, fast encoders and decoders to reconstruct unavailable predictions for a variety of inference tasks such as image classification, speech recognition, and object localization. We build ParM atop an open-source prediction serving system and through extensive evaluation show that ParM improves overall accuracy in the face of unavailability with low latency while using 2-4$\times$ less additional resources than replication-based approaches. ParM reduces the gap between 99.9th percentile and median latency by up to $3.5\times$ compared to approaches that use an equal amount of resources, while maintaining the same median.
Learning a Code: Machine Learning for Approximate Non-Linear Coded Computation
Jun 04, 2018
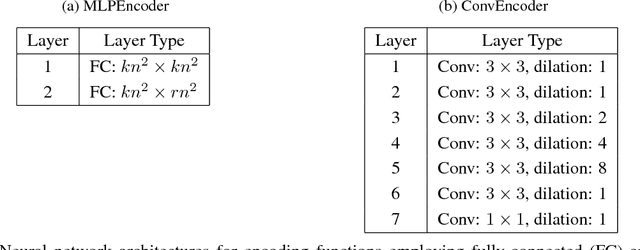
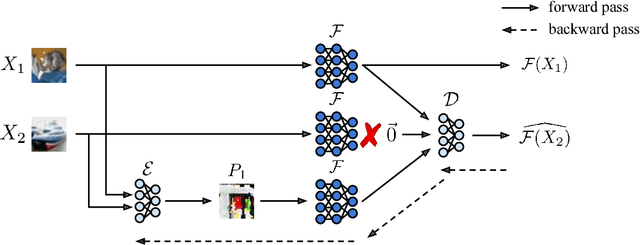

Machine learning algorithms are typically run on large scale, distributed compute infrastructure that routinely face a number of unavailabilities such as failures and temporary slowdowns. Adding redundant computations using coding-theoretic tools called "codes" is an emerging technique to alleviate the adverse effects of such unavailabilities. A code consists of an encoding function that proactively introduces redundant computation and a decoding function that reconstructs unavailable outputs using the available ones. Past work focuses on using codes to provide resilience for linear computations and specific iterative optimization algorithms. However, computations performed for a variety of applications including inference on state-of-the-art machine learning algorithms, such as neural networks, typically fall outside this realm. In this paper, we propose taking a learning-based approach to designing codes that can handle non-linear computations. We present carefully designed neural network architectures and a training methodology for learning encoding and decoding functions that produce approximate reconstructions of unavailable computation results. We present extensive experimental results demonstrating the effectiveness of the proposed approach: we show that the our learned codes can accurately reconstruct $64 - 98\%$ of the unavailable predictions from neural-network based image classifiers on the MNIST, Fashion-MNIST, and CIFAR-10 datasets. To the best of our knowledge, this work proposes the first learning-based approach for designing codes, and also presents the first coding-theoretic solution that can provide resilience for any non-linear (differentiable) computation. Our results show that learning can be an effective technique for designing codes, and that learned codes are a highly promising approach for bringing the benefits of coding to non-linear computations.
DART: Dropouts meet Multiple Additive Regression Trees
May 07, 2015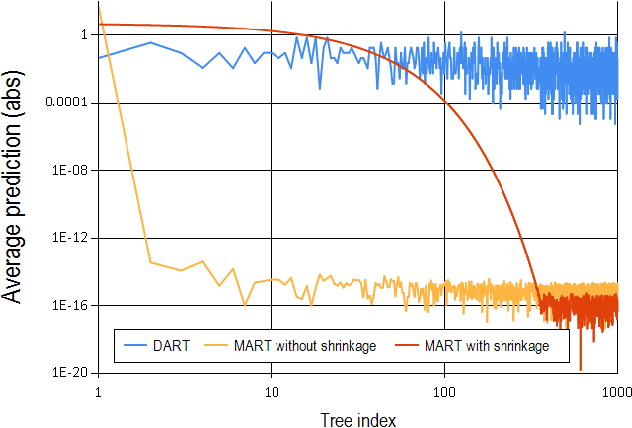



Multiple Additive Regression Trees (MART), an ensemble model of boosted regression trees, is known to deliver high prediction accuracy for diverse tasks, and it is widely used in practice. However, it suffers an issue which we call over-specialization, wherein trees added at later iterations tend to impact the prediction of only a few instances, and make negligible contribution towards the remaining instances. This negatively affects the performance of the model on unseen data, and also makes the model over-sensitive to the contributions of the few, initially added tress. We show that the commonly used tool to address this issue, that of shrinkage, alleviates the problem only to a certain extent and the fundamental issue of over-specialization still remains. In this work, we explore a different approach to address the problem that of employing dropouts, a tool that has been recently proposed in the context of learning deep neural networks. We propose a novel way of employing dropouts in MART, resulting in the DART algorithm. We evaluate DART on ranking, regression and classification tasks, using large scale, publicly available datasets, and show that DART outperforms MART in each of the tasks, with a significant margin. We also show that DART overcomes the issue of over-specialization to a considerable extent.