 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECRM: Efficient Fault Tolerance for Recommendation Model Training via Erasure Coding
Apr 05, 2021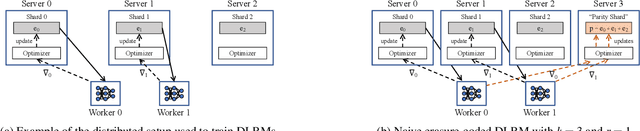

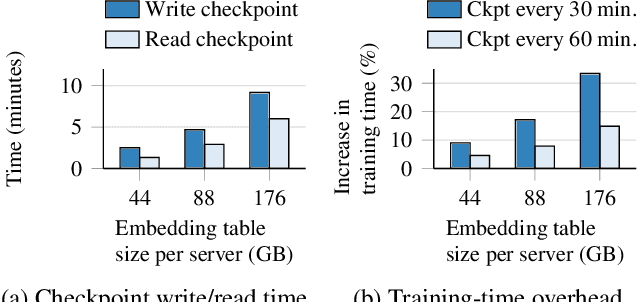
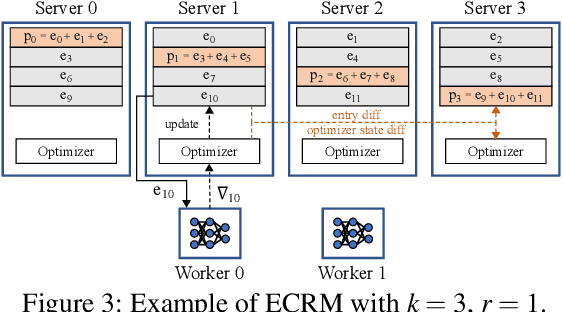
Deep-learning-based recommendation models (DLRMs) are widely deployed to serve personalized content to users. DLRMs are large in size due to their use of large embedding tables, and are trained by distributing the model across the memory of tens or hundreds of servers. Server failures are common in such large distributed systems and must be mitigated to enable training to progress. Checkpointing is the primary approach used for fault tolerance in these systems, but incurs significant training-time overhead both during normal operation and when recovering from failures. As these overheads increase with DLRM size, checkpointing is slated to become an even larger overhead for future DLRMs, which are expected to grow in size. This calls for rethinking fault tolerance in DLRM training. We present ECRM, a DLRM training system that achieves efficient fault tolerance using erasure coding. ECRM chooses which DLRM parameters to encode, correctly and efficiently updates parities, and enables training to proceed without any pauses, while maintaining consistency of the recovered parameters. We implement ECRM atop XDL, an open-source, industrial-scale DLRM training system. Compared to checkpointing, ECRM reduces training-time overhead for large DLRMs by up to 88%, recovers from failures up to 10.3$\times$ faster, and allows training to proceed during recovery. These results show the promise of erasure coding in imparting efficient fault tolerance to training current and future DLRMs.