 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART: Dropouts meet Multiple Additive Regression Trees
Paper and Code
May 07, 2015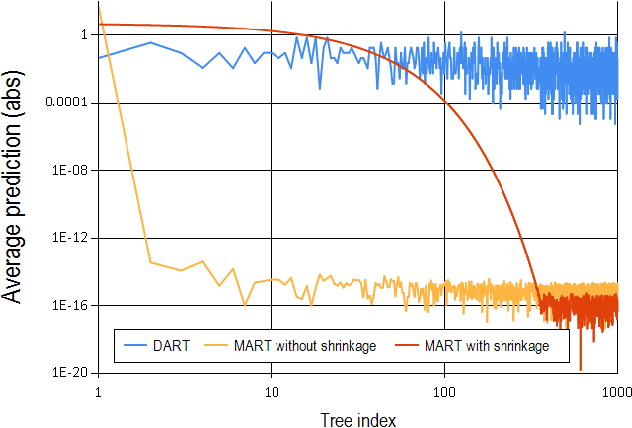



Multiple Additive Regression Trees (MART), an ensemble model of boosted regression trees, is known to deliver high prediction accuracy for diverse tasks, and it is widely used in practice. However, it suffers an issue which we call over-specialization, wherein trees added at later iterations tend to impact the prediction of only a few instances, and make negligible contribution towards the remaining instances. This negatively affects the performance of the model on unseen data, and also makes the model over-sensitive to the contributions of the few, initially added tress. We show that the commonly used tool to address this issue, that of shrinkage, alleviates the problem only to a certain extent and the fundamental issue of over-specialization still remains. In this work, we explore a different approach to address the problem that of employing dropouts, a tool that has been recently proposed in the context of learning deep neural networks. We propose a novel way of employing dropouts in MART, resulting in the DART algorithm. We evaluate DART on ranking, regression and classification tasks, using large scale, publicly available datasets, and show that DART outperforms MART in each of the tasks, with a significant margin. We also show that DART overcomes the issue of over-specialization to a considerable extent.