 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParity Models: A General Framework for Coding-Based Resilience in ML Inference
Paper and Code
May 02, 2019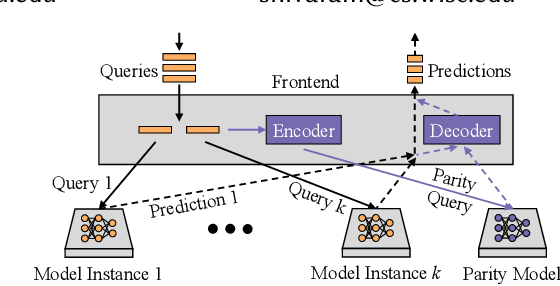
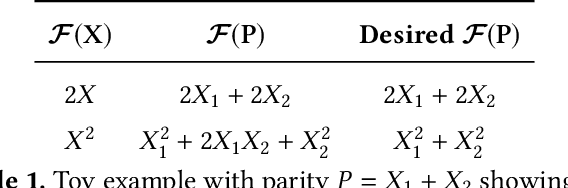
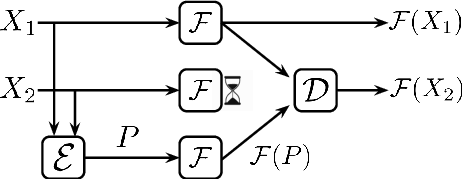
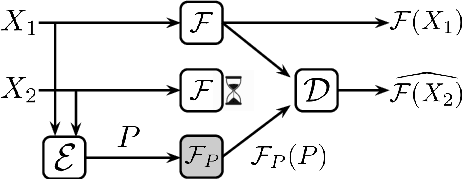
Machine learning models are becoming the primary workhorses for many applications. Production services deploy models through prediction serving systems that take in queries and return predictions by performing inference on machine learning models. In order to scale to high query rates, prediction serving systems are run on many machines in cluster settings, and thus are prone to slowdowns and failures that inflate tail latency and cause violations of strict latency targets. Current approaches to reducing tail latency are inadequate for the latency targets of prediction serving, incur high resource overhead, or are inapplicable to the computations performed during inference. We present ParM, a novel, general framework for making use of ideas from erasure coding and machine learning to achieve low-latency, resource-efficient resilience to slowdowns and failures in prediction serving systems. ParM encodes multiple queries together into a single parity query and performs inference on the parity query using a parity model. A decoder uses the output of a parity model to reconstruct approximations of unavailable predictions. ParM uses neural networks to learn parity models that enable simple, fast encoders and decoders to reconstruct unavailable predictions for a variety of inference tasks such as image classification, speech recognition, and object localization. We build ParM atop an open-source prediction serving system and through extensive evaluation show that ParM improves overall accuracy in the face of unavailability with low latency while using 2-4$\times$ less additional resources than replication-based approaches. ParM reduces the gap between 99.9th percentile and median latency by up to $3.5\times$ compared to approaches that use an equal amount of resources, while maintaining the same median.