 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Little Things Big Things Grow: A Collection with Seed Studies for Medical Systematic Review Literature Search
Apr 06, 2022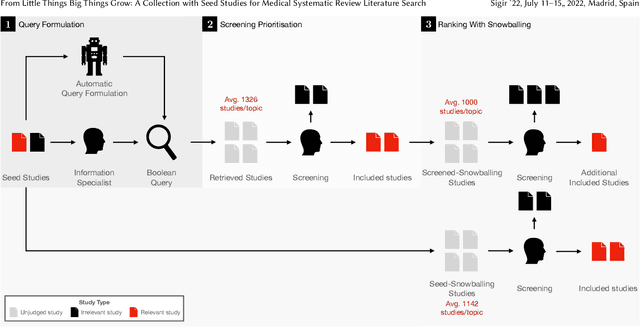

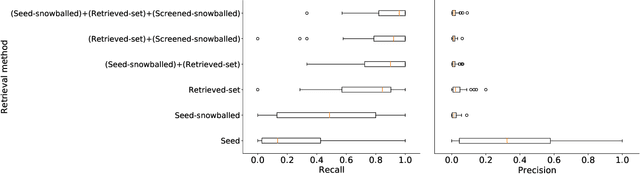
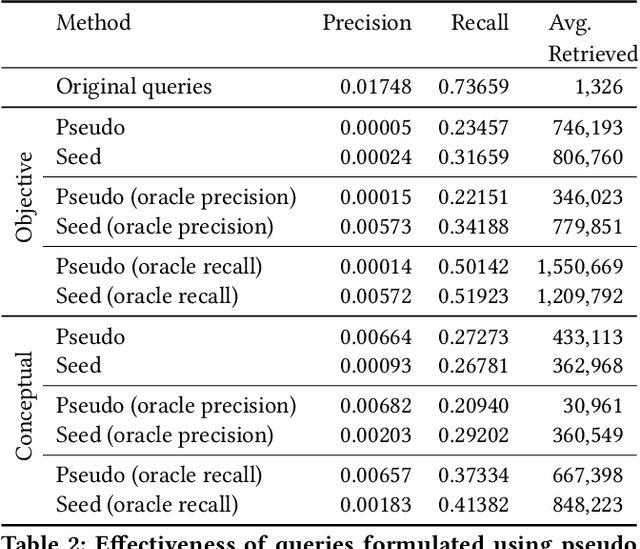
Medical systematic review query formulation is a highly complex task done by trained information specialists. Complexity comes from the reliance on lengthy Boolean queries, which express a detailed research question. To aid query formulation, information specialists use a set of exemplar documents, called `seed studies', prior to query formulation. Seed studies help verify the effectiveness of a query prior to the full assessment of retrieved studies. Beyond this use of seeds, specific IR methods can exploit seed studies for guiding both automatic query formulation and new retrieval models. One major limitation of work to date is that these methods exploit `pseudo seed studies' through retrospective use of included studies (i.e., relevance assessments). However, we show pseudo seed studies are not representative of real seed studies used by information specialists. Hence, we provide a test collection with real world seed studies used to assist with the formulation of queries. To support our collection, we provide an analysis, previously not possible, on how seed studies impact retrieval and perform several experiments using seed-study based methods to compare the effectiveness of using seed studies versus pseudo seed studies. We make our test collection and the results of all of our experiments and analysis available at http://github.com/ielab/sysrev-seed-collection
Promises and Pitfalls of Black-Box Concept Learning Models
Jun 24, 2021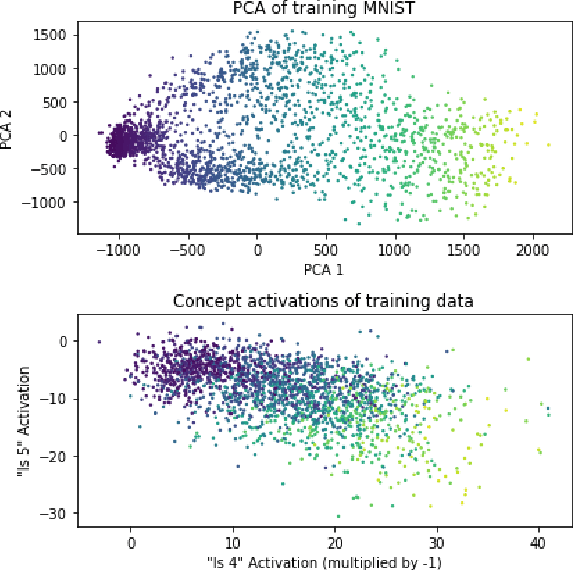
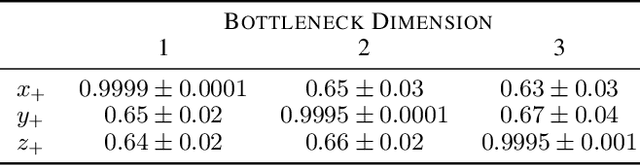
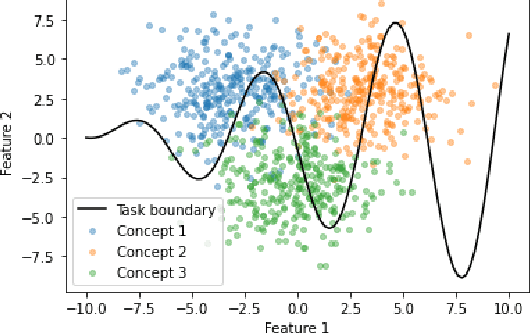

Machine learning models that incorporate concept learning as an intermediate step in their decision making process can match the performance of black-box predictive models while retaining the ability to explain outcomes in human understandable terms. However, we demonstrate that the concept representations learned by these models encode information beyond the pre-defined concepts, and that natural mitigation strategies do not fully work, rendering the interpretation of the downstream prediction misleading. We describe the mechanism underlying the information leakage and suggest recourse for mitigating its effects.