 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLineCap: Line Charts for Data Visualization Captioning Models
Jul 15, 2022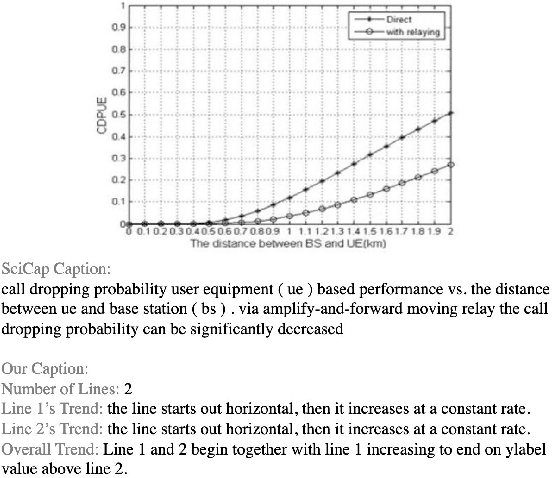
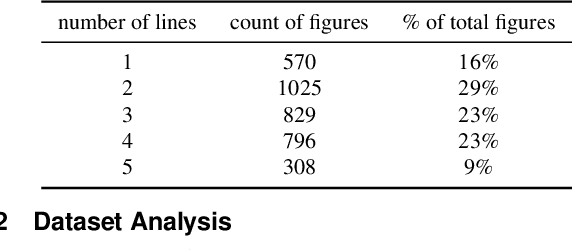
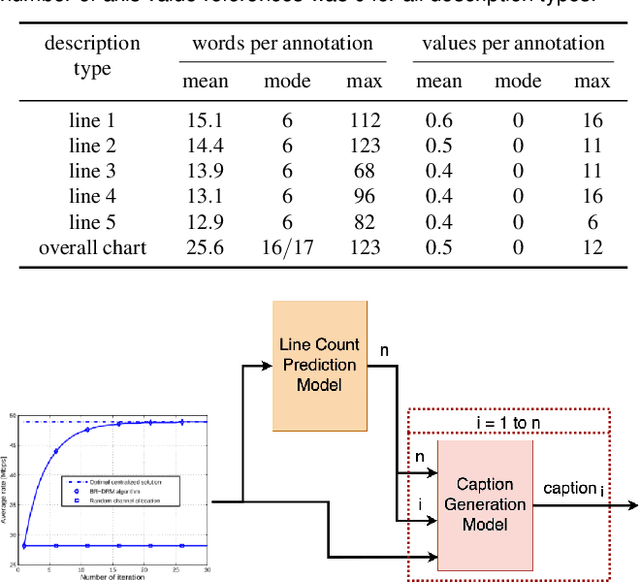
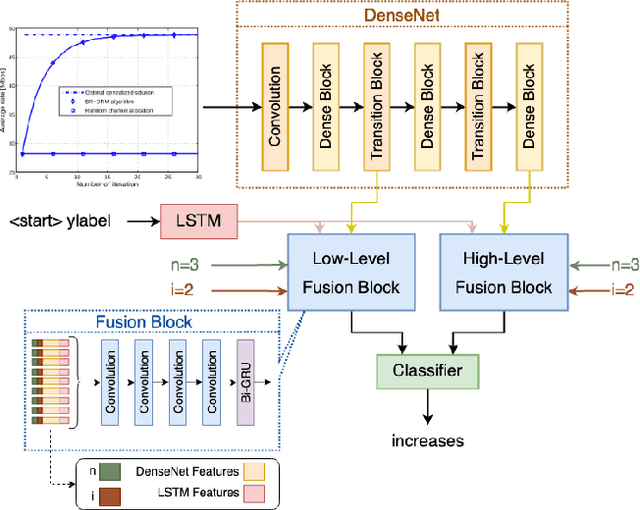
Data visualization captions help readers understand the purpose of a visualization and are crucial for individuals with visual impairments. The prevalence of poor figure captions and the successful application of deep learning approaches to image captioning motivate the use of similar techniques for automated figure captioning. However, research in this field has been stunted by the lack of suitable datasets. We introduce LineCap, a novel figure captioning dataset of 3,528 figures, and we provide insights from curating this dataset and using end-to-end deep learning models for automated figure captioning.
Promises and Pitfalls of Black-Box Concept Learning Models
Jun 24, 2021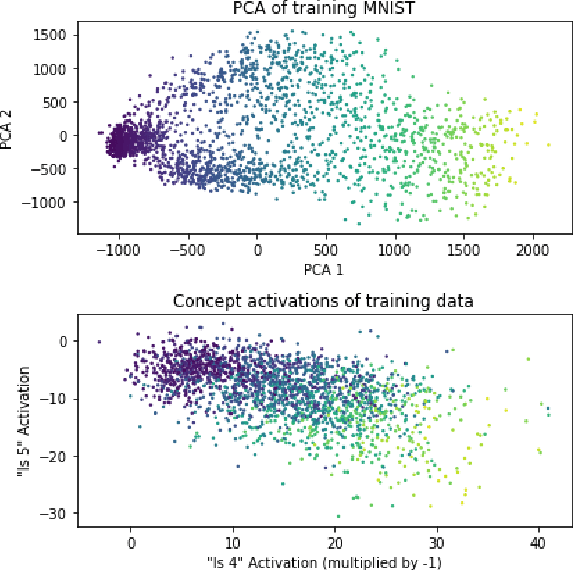
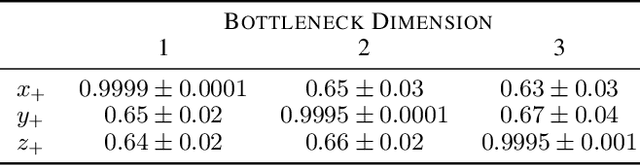
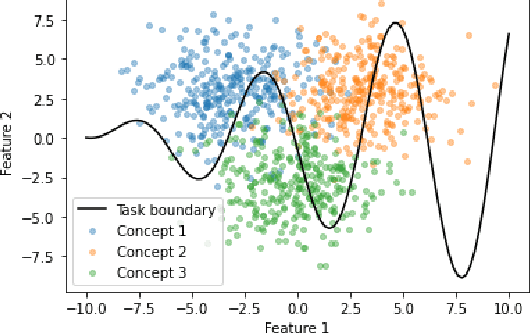

Machine learning models that incorporate concept learning as an intermediate step in their decision making process can match the performance of black-box predictive models while retaining the ability to explain outcomes in human understandable terms. However, we demonstrate that the concept representations learned by these models encode information beyond the pre-defined concepts, and that natural mitigation strategies do not fully work, rendering the interpretation of the downstream prediction misleading. We describe the mechanism underlying the information leakage and suggest recourse for mitigating its effects.