 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheraAgent: Self-Improving Therapeutic Agent for Precise and Comprehensive Treatment Planning
May 07, 2026Formulating a treatment plan is inherently a complex reasoning and refinement task rather than a simple generation problem. However, existing large language models (LLMs) mainly rely on one-shot output without explicit verification, which may result in rough, incomplete, and potentially unsafe treatment plans. To address these limitations, we propose TheraAgent, an agentic framework that replaces one-shot generation with an iterative generate-judge-refine pipeline. By mirroring the actual reasoning process of human experts who iteratively revise treatment plans, our framework progressively transforms coarse and incomplete drafts into precise, comprehensive, and safer therapeutic regimens. To facilitate the critical judge component, we introduce TheraJudge, a treatment-specific evaluation module integrated into the inference loop to enforce clinical standards. Experiments show TheraAgent achieves state-of-the-art results on HealthBench, leading in Accuracy and Completeness. In expert evaluations, it attains an 86% win rate against physicians, with superior Targeting and Harm Control. Moreover, the highly agreement between TheraJudge and HealthBench evaluations confirms the reliability of our framework.
Beyond Words: Enhancing Desire, Emotion, and Sentiment Recognition with Non-Verbal Cues
Sep 19, 2025

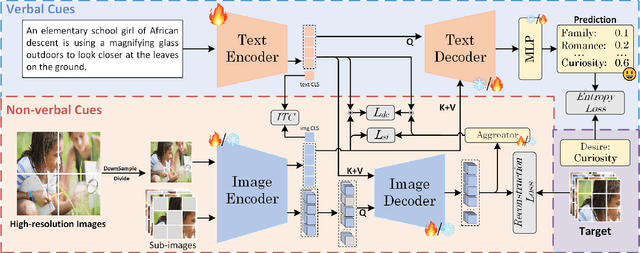
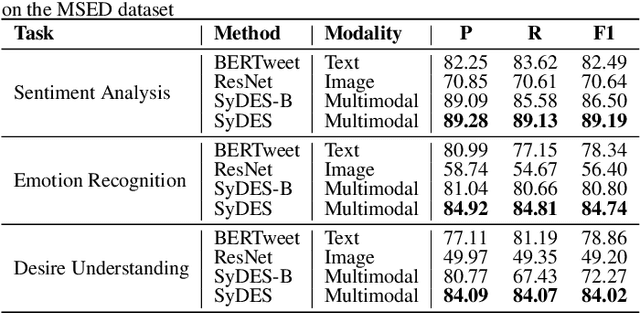
Desire, as an intention that drives human behavior, is closely related to both emotion and sentiment. Multimodal learning has advanced sentiment and emotion recognition, but multimodal approaches specially targeting human desire understanding remain underexplored. And existing methods in sentiment analysis predominantly emphasize verbal cues and overlook images as complementary non-verbal cues. To address these gaps, we propose a Symmetrical Bidirectional Multimodal Learning Framework for Desire, Emotion, and Sentiment Recognition, which enforces mutual guidance between text and image modalities to effectively capture intention-related representations in the image. Specifically, low-resolution images are used to obtain global visual representations for cross-modal alignment, while high resolution images are partitioned into sub-images and modeled with masked image modeling to enhance the ability to capture fine-grained local features. A text-guided image decoder and an image-guided text decoder are introduced to facilitate deep cross-modal interaction at both local and global representations of image information. Additionally, to balance perceptual gains with computation cost, a mixed-scale image strategy is adopted, where high-resolution images are cropped into sub-images for masked modeling. The proposed approach is evaluated on MSED, a multimodal dataset that includes a desire understanding benchmark, as well as emotion and sentiment recognition. Experimental results indicate consistent improvements over other state-of-the-art methods, validating the effectiveness of our proposed method. Specifically, our method outperforms existing approaches, achieving F1-score improvements of 1.1% in desire understanding, 0.6% in emotion recognition, and 0.9% in sentiment analysis. Our code is available at: https://github.com/especiallyW/SyDES.
RCLMuFN: Relational Context Learning and Multiplex Fusion Network for Multimodal Sarcasm Detection
Dec 17, 2024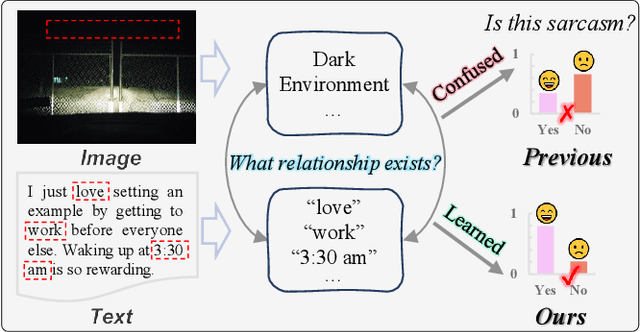
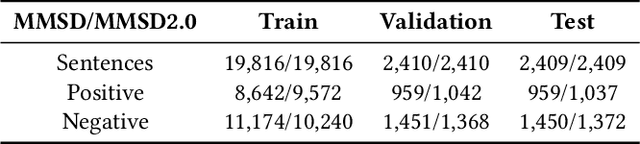
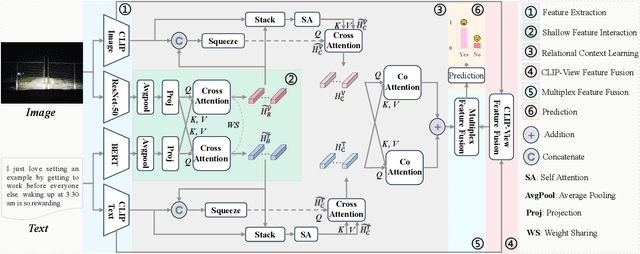

Sarcasm typically conveys emotions of contempt or criticism by expressing a meaning that is contrary to the speaker's true intent. Accurate detection of sarcasm aids in identifying and filtering undesirable information on the Internet, thereby reducing malicious defamation and rumor-mongering. Nonetheless, the task of automatic sarcasm detection remains highly challenging for machines, as it critically depends on intricate factors such as relational context. Most existing multimodal sarcasm detection methods focus on introducing graph structures to establish entity relationships between text and images while neglecting to learn the relational context between text and images, which is crucial evidence for understanding the meaning of sarcasm. In addition, the meaning of sarcasm changes with the evolution of different contexts, but existing methods may not be accurate in modeling such dynamic changes, limiting the generalization ability of the models. To address the above issues, we propose a relational context learning and multiplex fusion network (RCLMuFN) for multimodal sarcasm detection. Firstly, we employ four feature extractors to comprehensively extract features from raw text and images, aiming to excavate potential features that may have been previously overlooked. Secondly, we utilize the relational context learning module to learn the contextual information of text and images and capture the dynamic properties through shallow and deep interactions. Finally, we employ a multiplex feature fusion module to enhance the generalization of the model by penetratingly integrating multimodal features derived from various interaction contexts. Extensive experiments on two multimodal sarcasm detection datasets show that our proposed method achieves state-of-the-art performance.
Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents
May 05, 2024



In this paper, we introduce a simulacrum of hospital called Agent Hospital that simulates the entire process of treating illness. All patients, nurses, and doctors are autonomous agents powered by large language models (LLMs). Our central goal is to enable a doctor agent to learn how to treat illness within the simulacrum. To do so, we propose a method called MedAgent-Zero. As the simulacrum can simulate disease onset and progression based on knowledge bases and LLMs, doctor agents can keep accumulating experience from both successful and unsuccessful cases. Simulation experiments show that the treatment performance of doctor agents consistently improves on various tasks. More interestingly, the knowledge the doctor agents have acquired in Agent Hospital is applicable to real-world medicare benchmarks. After treating around ten thousand patients (real-world doctors may take over two years), the evolved doctor agent achieves a state-of-the-art accuracy of 93.06% on a subset of the MedQA dataset that covers major respiratory diseases. This work paves the way for advancing the applications of LLM-powered agent techniques in medical scenarios.
Citation-Enhanced Generation for LLM-based Chatbots
Mar 04, 2024



Large language models (LLMs) exhibit powerful general intelligence across diverse scenarios, including their integration into chatbots. However, a vital challenge of LLM-based chatbots is that they may produce hallucinated content in responses, which significantly limits their applicability. Various efforts have been made to alleviate hallucination, such as retrieval augmented generation and reinforcement learning with human feedback, but most of them require additional training and data annotation. In this paper, we propose a novel post-hoc Citation-Enhanced Generation (CEG) approach combined with retrieval argumentation. Unlike previous studies that focus on preventing hallucinations during generation, our method addresses this issue in a post-hoc way. It incorporates a retrieval module to search for supporting documents relevant to the generated content, and employs a natural language inference-based citation generation module. Once the statements in the generated content lack of reference, our model can regenerate responses until all statements are supported by citations. Note that our method is a training-free plug-and-play plugin that is capable of various LLMs. Experiments on various hallucination-related datasets show our framework outperforms state-of-the-art methods in both hallucination detection and response regeneration on three benchmarks. Our codes and dataset will be publicly available.