 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCLMuFN: Relational Context Learning and Multiplex Fusion Network for Multimodal Sarcasm Detection
Dec 17, 2024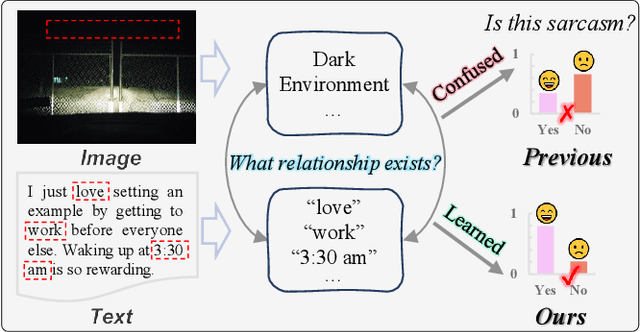
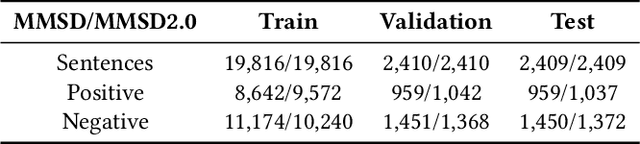
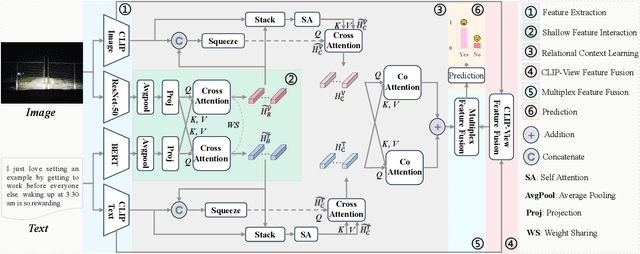

Sarcasm typically conveys emotions of contempt or criticism by expressing a meaning that is contrary to the speaker's true intent. Accurate detection of sarcasm aids in identifying and filtering undesirable information on the Internet, thereby reducing malicious defamation and rumor-mongering. Nonetheless, the task of automatic sarcasm detection remains highly challenging for machines, as it critically depends on intricate factors such as relational context. Most existing multimodal sarcasm detection methods focus on introducing graph structures to establish entity relationships between text and images while neglecting to learn the relational context between text and images, which is crucial evidence for understanding the meaning of sarcasm. In addition, the meaning of sarcasm changes with the evolution of different contexts, but existing methods may not be accurate in modeling such dynamic changes, limiting the generalization ability of the models. To address the above issues, we propose a relational context learning and multiplex fusion network (RCLMuFN) for multimodal sarcasm detection. Firstly, we employ four feature extractors to comprehensively extract features from raw text and images, aiming to excavate potential features that may have been previously overlooked. Secondly, we utilize the relational context learning module to learn the contextual information of text and images and capture the dynamic properties through shallow and deep interactions. Finally, we employ a multiplex feature fusion module to enhance the generalization of the model by penetratingly integrating multimodal features derived from various interaction contexts. Extensive experiments on two multimodal sarcasm detection datasets show that our proposed method achieves state-of-the-art performance.