 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Koopman operators for coupled systems via information on governing equations of subsystems
May 03, 2026Nonlinear coupled systems are ubiquitous in science and engineering. The analysis and modeling of such systems is challenging due to their high dimensionality and complex interactions among subsystems. In recent years, operator-theoretic methods based on the Koopman operator have attracted attention as a powerful tool for analyzing and modeling nonlinear dynamical systems. Extended dynamic mode decomposition (EDMD) is one of the most popular methods to approximate the Koopman operator. However, EDMD is a purely data-driven method, and it could be unstable and inaccurate for coupled systems under limited data availability. In this paper, we propose a method to learn the Koopman operator for coupled systems using the differential equations governing each subsystem. We also demonstrate its effectiveness through numerical experiments on coupled oscillator systems.
Tensor-based computation of the Koopman generator via operator logarithm
Apr 09, 2026Identifying governing equations of nonlinear dynamical systems from data is challenging. While sparse identification of nonlinear dynamics (SINDy) and its extensions are widely used for system identification, operator-logarithm approaches use the logarithm to avoid time differentiation, enabling larger sampling intervals. However, they still suffer from the curse of dimensionality. Then, we propose a data-driven method to compute the Koopman generator in a low-rank tensor train (TT) format by taking logarithms of Koopman eigenvalues while preserving the TT format. Experiments on 4-dimensional Lotka-Volterra and 10-dimensional Lorenz-96 systems show accurate recovery of vector field coefficients and scalability to higher-dimensional systems.
Extraction of linearized models from pre-trained networks via knowledge distillation
Apr 08, 2026Recent developments in hardware, such as photonic integrated circuits and optical devices, are driving demand for research on constructing machine learning architectures tailored for linear operations. Hence, it is valuable to explore methods for constructing learning machines with only linear operations after simple nonlinear preprocessing. In this study, we propose a framework to extract a linearized model from a pre-trained neural network for classification tasks by integrating Koopman operator theory with knowledge distillation. Numerical demonstrations on the MNIST and the Fashion-MNIST datasets reveal that the proposed model consistently outperforms the conventional least-squares-based Koopman approximation in both classification accuracy and numerical stability.
Integrated utilization of equations and small dataset in the Koopman operator: applications to forward and inverse Problems
Mar 26, 2025
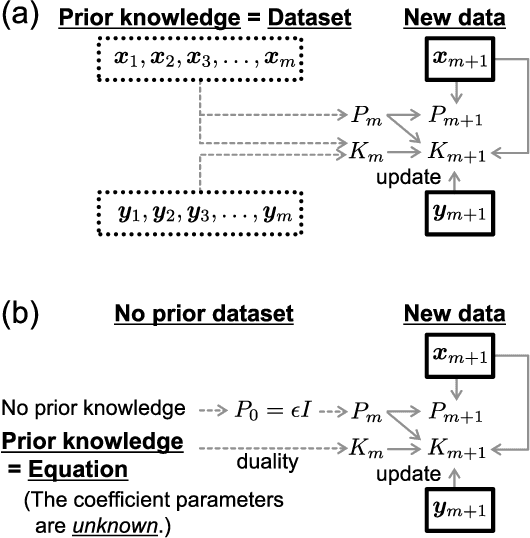


In recent years, there has been a growing interest in data-driven approaches in physics, such as extended dynamic mode decomposition (EDMD). The EDMD algorithm focuses on nonlinear time-evolution systems, and the constructed Koopman matrix yields the next-time prediction with only linear matrix-product operations. Note that data-driven approaches generally require a large dataset. However, assume that one has some prior knowledge, even if it may be ambiguous. Then, one could achieve sufficient learning from only a small dataset by taking advantage of the prior knowledge. This paper yields methods for incorporating ambiguous prior knowledge into the EDMD algorithm. The ambiguous prior knowledge in this paper corresponds to the underlying time-evolution equations with unknown parameters. First, we apply the proposed method to forward problems, i.e., prediction tasks. Second, we propose a scheme to apply the proposed method to inverse problems, i.e., parameter estimation tasks. We demonstrate the learning with only a small dataset using guiding examples, i.e., the Duffing and the van der Pol systems.
Aspects of importance sampling in parameter selection for neural networks using ridgelet transform
Jul 26, 2024



The choice of parameters in neural networks is crucial in the performance, and an oracle distribution derived from the ridgelet transform enables us to obtain suitable initial parameters. In other words, the distribution of parameters is connected to the integral representation of target functions. The oracle distribution allows us to avoid the conventional backpropagation learning process; only a linear regression is enough to construct the neural network in simple cases. This study provides a new look at the oracle distributions and ridgelet transforms, i.e., an aspect of importance sampling. In addition, we propose extensions of the parameter sampling methods. We demonstrate the aspect of importance sampling and the proposed sampling algorithms via one-dimensional and high-dimensional examples; the results imply that the magnitude of weight parameters could be more crucial than the intercept parameters.
Compression of the Koopman matrix for nonlinear physical models via hierarchical clustering
Mar 27, 2024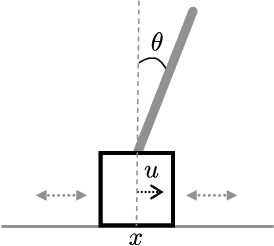



Machine learning methods allow the prediction of nonlinear dynamical systems from data alone. The Koopman operator is one of them, which enables us to employ linear analysis for nonlinear dynamical systems. The linear characteristics of the Koopman operator are hopeful to understand the nonlinear dynamics and perform rapid predictions. The extended dynamic mode decomposition (EDMD) is one of the methods to approximate the Koopman operator as a finite-dimensional matrix. In this work, we propose a method to compress the Koopman matrix using hierarchical clustering. Numerical demonstrations for the cart-pole model and comparisons with the conventional singular value decomposition (SVD) are shown; the results indicate that the hierarchical clustering performs better than the naive SVD compressions.
Extraction of nonlinearity in neural networks and model compression with Koopman operator
Feb 18, 2024Nonlinearity plays a crucial role in deep neural networks. In this paper, we first investigate the degree to which the nonlinearity of the neural network is essential. For this purpose, we employ the Koopman operator, extended dynamic mode decomposition, and the tensor-train format. The results imply that restricted nonlinearity is enough for the classification of handwritten numbers. Then, we propose a model compression method for deep neural networks, which could be beneficial to handling large networks in resource-constrained environments. Leveraging the Koopman operator, the proposed method enables us to use linear algebra in the internal processing of neural networks. We numerically show that the proposed method performs comparably or better than conventional methods in highly compressed model settings for the handwritten number recognition task.
Attention-Enhanced Reservoir Computing
Dec 27, 2023



Photonic reservoir computing has been recently utilized in time series forecasting as the need for hardware implementations to accelerate these predictions has increased. Forecasting chaotic time series remains a significant challenge, an area where the conventional reservoir computing framework encounters limitations of prediction accuracy. We introduce an attention mechanism to the reservoir computing model in the output stage. This attention layer is designed to prioritize distinct features and temporal sequences, thereby substantially enhancing the forecasting accuracy. Our results show that a photonic reservoir computer enhanced with the attention mechanism exhibits improved forecasting capabilities for smaller reservoirs. These advancements highlight the transformative possibilities of reservoir computing for practical applications where accurate forecasting of chaotic time series is crucial.
Characterization of Locality in Spin States and Forced Moves for Optimizations
Dec 05, 2023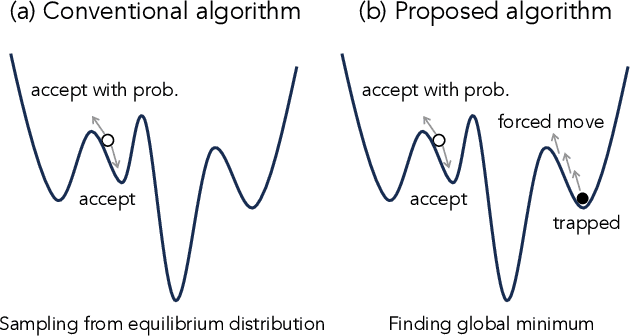


Ising formulations are widely utilized to solve combinatorial optimization problems, and a variety of quantum or semiconductor-based hardware has recently been made available. In combinatorial optimization problems, the existence of local minima in energy landscapes is problematic to use to seek the global minimum. We note that the aim of the optimization is not to obtain exact samplings from the Boltzmann distribution, and there is thus no need to satisfy detailed balance conditions. In light of this fact, we develop an algorithm to get out of the local minima efficiently while it does not yield the exact samplings. For this purpose, we utilize a feature that characterizes locality in the current state, which is easy to obtain with a type of specialized hardware. Furthermore, as the proposed algorithm is based on a rejection-free algorithm, the computational cost is low. In this work, after presenting the details of the proposed algorithm, we report the results of numerical experiments that demonstrate the effectiveness of the proposed feature and algorithm.
Embedding stochastic differential equations into neural networks via dual processes
Jun 08, 2023We propose a new approach to constructing a neural network for predicting expectations of stochastic differential equations. The proposed method does not need data sets of inputs and outputs; instead, the information obtained from the time-evolution equations, i.e., the corresponding dual process, is directly compared with the weights in the neural network. As a demonstration, we construct neural networks for the Ornstein-Uhlenbeck process and the noisy van der Pol system. The remarkable feature of learned networks with the proposed method is the accuracy of inputs near the origin. Hence, it would be possible to avoid the overfitting problem because the learned network does not depend on training data sets.