 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMVD dataset: a dataset of extreme vocal distortion techniques used in heavy metal
Jun 24, 2024



In this paper, we introduce the Extreme Metal Vocals Dataset, which comprises a collection of recordings of extreme vocal techniques performed within the realm of heavy metal music. The dataset consists of 760 audio excerpts of 1 second to 30 seconds long, totaling about 100 min of audio material, roughly composed of 60 minutes of distorted voices and 40 minutes of clear voice recordings. These vocal recordings are from 27 different singers and are provided without accompanying musical instruments or post-processing effects. The distortion taxonomy within this dataset encompasses four distinct distortion techniques and three vocal effects, all performed in different pitch ranges. Performance of a state-of-the-art deep learning model is evaluated for two different classification tasks related to vocal techniques, demonstrating the potential of this resource for the audio processing community.
CoNeTTE: An efficient Audio Captioning system leveraging multiple datasets with Task Embedding
Sep 01, 2023Automated Audio Captioning (AAC) involves generating natural language descriptions of audio content, using encoder-decoder architectures. An audio encoder produces audio embeddings fed to a decoder, usually a Transformer decoder, for caption generation. In this work, we describe our model, which novelty, compared to existing models, lies in the use of a ConvNeXt architecture as audio encoder, adapted from the vision domain to audio classification. This model, called CNext-trans, achieved state-of-the-art scores on the AudioCaps (AC) dataset and performed competitively on Clotho (CL), while using four to forty times fewer parameters than existing models. We examine potential biases in the AC dataset due to its origin from AudioSet by investigating unbiased encoder's impact on performance. Using the well-known PANN's CNN14, for instance, as an unbiased encoder, we observed a 1.7% absolute reduction in SPIDEr score (where higher scores indicate better performance). To improve cross-dataset performance, we conducted experiments by combining multiple AAC datasets (AC, CL, MACS, WavCaps) for training. Although this strategy enhanced overall model performance across datasets, it still fell short compared to models trained specifically on a single target dataset, indicating the absence of a one-size-fits-all model. To mitigate performance gaps between datasets, we introduced a Task Embedding (TE) token, allowing the model to identify the source dataset for each input sample. We provide insights into the impact of these TEs on both the form (words) and content (sound event types) of the generated captions. The resulting model, named CoNeTTE, an unbiased CNext-trans model enriched with dataset-specific Task Embeddings, achieved SPIDEr scores of 44.1% and 30.5% on AC and CL, respectively. Code available: https://github.com/Labbeti/conette-audio-captioning.
Killing two birds with one stone: Can an audio captioning system also be used for audio-text retrieval?
Aug 29, 2023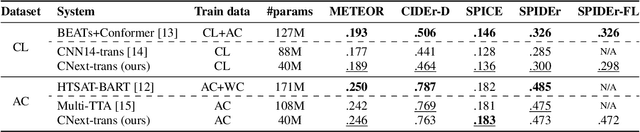
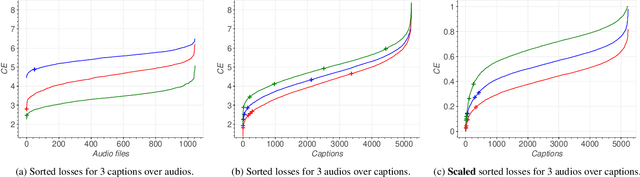
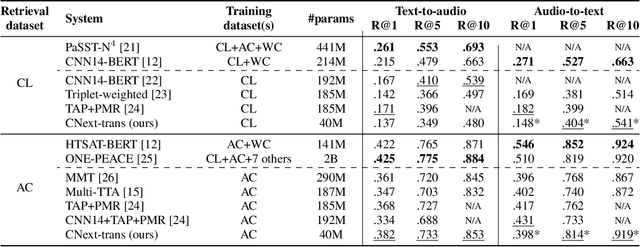
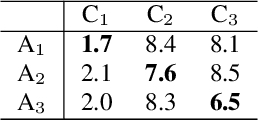
Automated Audio Captioning (AAC) aims to develop systems capable of describing an audio recording using a textual sentence. In contrast, Audio-Text Retrieval (ATR) systems seek to find the best matching audio recording(s) for a given textual query (Text-to-Audio) or vice versa (Audio-to-Text). These tasks require different types of systems: AAC employs a sequence-to-sequence model, while ATR utilizes a ranking model that compares audio and text representations within a shared projection subspace. However, this work investigates the relationship between AAC and ATR by exploring the ATR capabilities of an unmodified AAC system, without fine-tuning for the new task. Our AAC system consists of an audio encoder (ConvNeXt-Tiny) trained on AudioSet for audio tagging, and a transformer decoder responsible for generating sentences. For AAC, it achieves a high SPIDEr-FL score of 0.298 on Clotho and 0.472 on AudioCaps on average. For ATR, we propose using the standard Cross-Entropy loss values obtained for any audio/caption pair. Experimental results on the Clotho and AudioCaps datasets demonstrate decent recall values using this simple approach. For instance, we obtained a Text-to-Audio R@1 value of 0.382 for Au-dioCaps, which is above the current state-of-the-art method without external data. Interestingly, we observe that normalizing the loss values was necessary for Audio-to-Text retrieval.
* cam ready version (14/08/23)
Multitask learning in Audio Captioning: a sentence embedding regression loss acts as a regularizer
May 02, 2023In this work, we propose to study the performance of a model trained with a sentence embedding regression loss component for the Automated Audio Captioning task. This task aims to build systems that can describe audio content with a single sentence written in natural language. Most systems are trained with the standard Cross-Entropy loss, which does not take into account the semantic closeness of the sentence. We found that adding a sentence embedding loss term reduces overfitting, but also increased SPIDEr from 0.397 to 0.418 in our first setting on the AudioCaps corpus. When we increased the weight decay value, we found our model to be much closer to the current state-of-the-art methods, with a SPIDEr score up to 0.444 compared to a 0.475 score. Moreover, this model uses eight times less trainable parameters. In this training setting, the sentence embedding loss has no more impact on the model performance.
Is my automatic audio captioning system so bad? spider-max: a metric to consider several caption candidates
Nov 14, 2022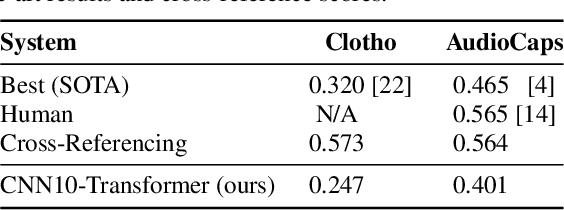
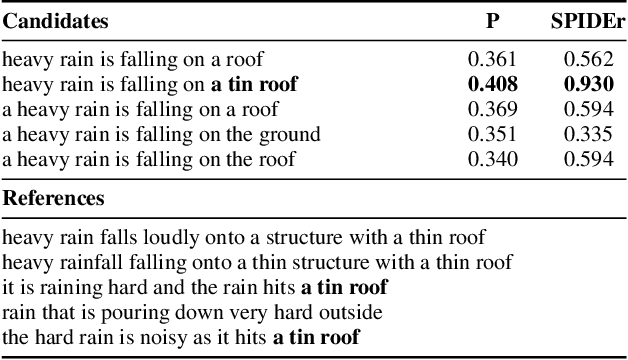
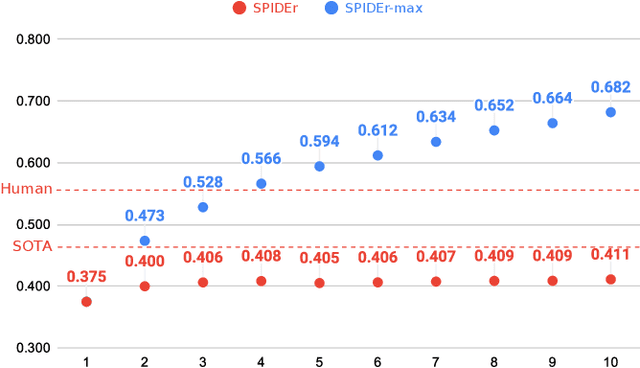
Automatic Audio Captioning (AAC) is the task that aims to describe an audio signal using natural language. AAC systems take as input an audio signal and output a free-form text sentence, called a caption. Evaluating such systems is not trivial, since there are many ways to express the same idea. For this reason, several complementary metrics, such as BLEU, CIDEr, SPICE and SPIDEr, are used to compare a single automatic caption to one or several captions of reference, produced by a human annotator. Nevertheless, an automatic system can produce several caption candidates, either using some randomness in the sentence generation process, or by considering the various competing hypothesized captions during decoding with beam-search, for instance. If we consider an end-user of an AAC system, presenting several captions instead of a single one seems relevant to provide some diversity, similarly to information retrieval systems. In this work, we explore the possibility to consider several predicted captions in the evaluation process instead of one. For this purpose, we propose SPIDEr-max, a metric that takes the maximum SPIDEr value among the scores of several caption candidates. To advocate for our metric, we report experiments on Clotho v2.1 and AudioCaps, with a transformed-based system. On AudioCaps for example, this system reached a SPIDEr-max value (with 5 candidates) close to the SPIDEr human score of reference.
Audio-video fusion strategies for active speaker detection in meetings
Jun 09, 2022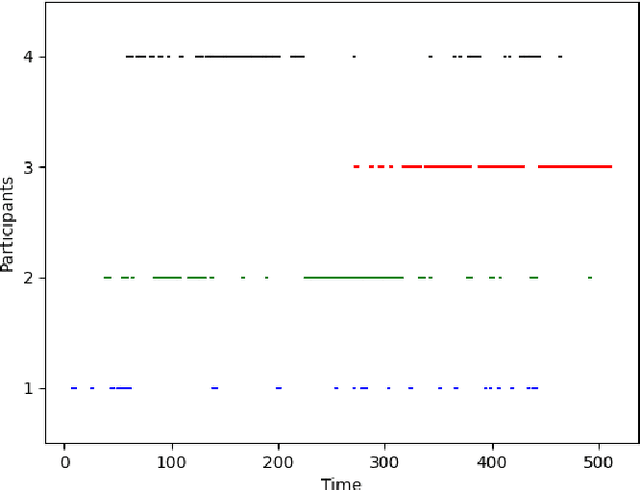



Meetings are a common activity in professional contexts, and it remains challenging to endow vocal assistants with advanced functionalities to facilitate meeting management. In this context, a task like active speaker detection can provide useful insights to model interaction between meeting participants. Motivated by our application context related to advanced meeting assistant, we want to combine audio and visual information to achieve the best possible performance. In this paper, we propose two different types of fusion for the detection of the active speaker, combining two visual modalities and an audio modality through neural networks. For comparison purpose, classical unsupervised approaches for audio feature extraction are also used. We expect visual data centered on the face of each participant to be very appropriate for detecting voice activity, based on the detection of lip and facial gestures. Thus, our baseline system uses visual data and we chose a 3D Convolutional Neural Network architecture, which is effective for simultaneously encoding appearance and movement. To improve this system, we supplemented the visual information by processing the audio stream with a CNN or an unsupervised speaker diarization system. We have further improved this system by adding visual modality information using motion through optical flow. We evaluated our proposal with a public and state-of-the-art benchmark: the AMI corpus. We analysed the contribution of each system to the merger carried out in order to determine if a given participant is currently speaking. We also discussed the results we obtained. Besides, we have shown that, for our application context, adding motion information greatly improves performance. Finally, we have shown that attention-based fusion improves performance while reducing the standard deviation.
End-to-end acoustic modelling for phone recognition of young readers
Mar 04, 2021
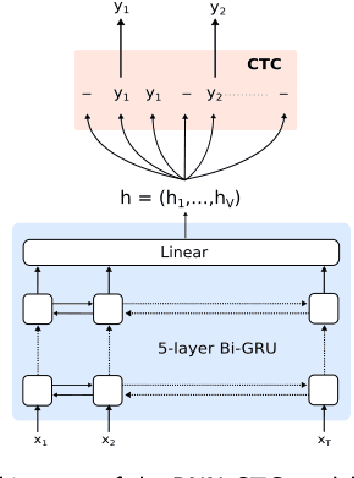

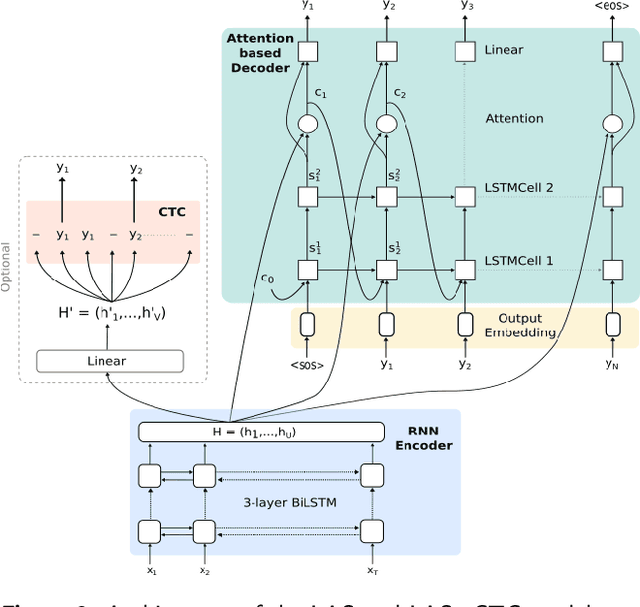
Automatic recognition systems for child speech are lagging behind those dedicated to adult speech in the race of performance. This phenomenon is due to the high acoustic and linguistic variability present in child speech caused by their body development, as well as the lack of available child speech data. Young readers speech additionally displays peculiarities, such as slow reading rate and presence of reading mistakes, that hardens the task. This work attempts to tackle the main challenges in phone acoustic modelling for young child speech with limited data, and improve understanding of strengths and weaknesses of a wide selection of model architectures in this domain. We find that transfer learning techniques are highly efficient on end-to-end architectures for adult-to-child adaptation with a small amount of child speech data. Through transfer learning, a Transformer model complemented with a Connectionist Temporal Classification (CTC) objective function, reaches a phone error rate of 28.1%, outperforming a state-of-the-art DNN-HMM model by 6.6% relative, as well as other end-to-end architectures by more than 8.5% relative. An analysis of the models' performance on two specific reading tasks (isolated words and sentences) is provided, showing the influence of the utterance length on attention-based and CTC-based models. The Transformer+CTC model displays an ability to better detect reading mistakes made by children, that can be attributed to the CTC objective function effectively constraining the attention mechanisms to be monotonic.
Deep Neural Networks for Automatic Speech Processing: A Survey from Large Corpora to Limited Data
Mar 09, 2020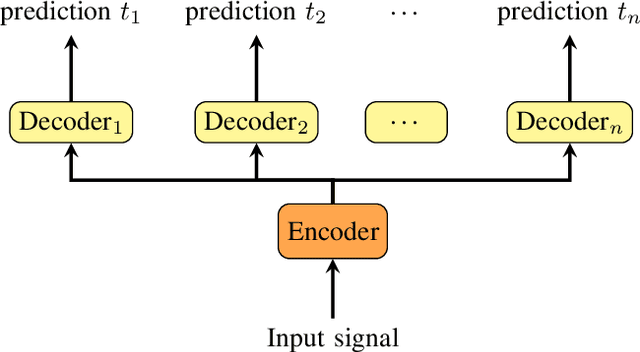
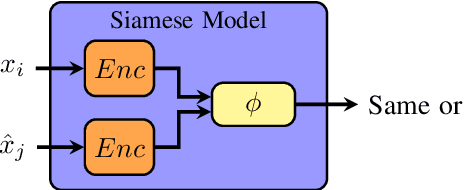
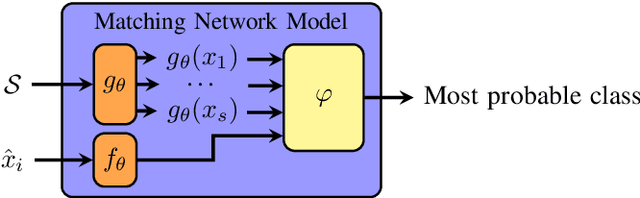
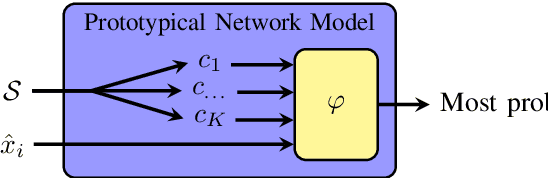
Most state-of-the-art speech systems are using Deep Neural Networks (DNNs). Those systems require a large amount of data to be learned. Hence, learning state-of-the-art frameworks on under-resourced speech languages/problems is a difficult task. Problems could be the limited amount of data for impaired speech. Furthermore, acquiring more data and/or expertise is time-consuming and expensive. In this paper we position ourselves for the following speech processing tasks: Automatic Speech Recognition, speaker identification and emotion recognition. To assess the problem of limited data, we firstly investigate state-of-the-art Automatic Speech Recognition systems as it represents the hardest tasks (due to the large variability in each language). Next, we provide an overview of techniques and tasks requiring fewer data. In the last section we investigate few-shot techniques as we interpret under-resourced speech as a few-shot problem. In that sense we propose an overview of few-shot techniques and perspectives of using such techniques for the focused speech problems in this survey. It occurs that the reviewed techniques are not well adapted for large datasets. Nevertheless, some promising results from the literature encourage the usage of such techniques for speech processing.
Improving Vehicle Re-Identification using CNN Latent Spaces: Metrics Comparison and Track-to-track Extension
Oct 21, 2019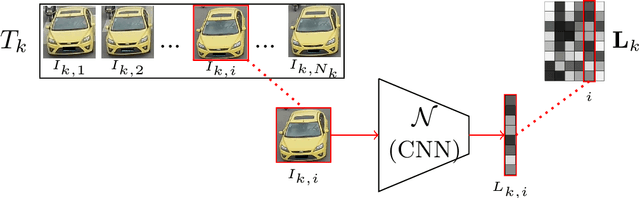
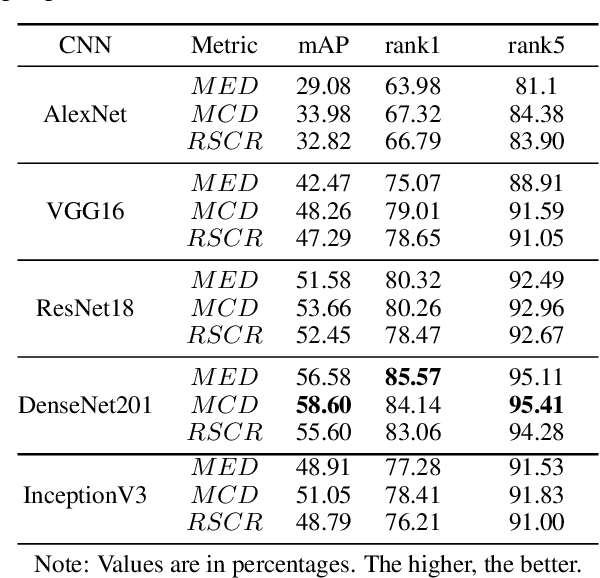
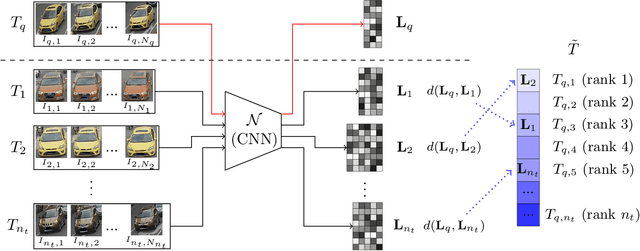
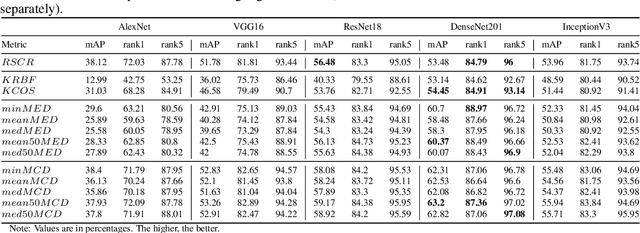
This paper addresses the problem of vehicle re-identification using distance comparison of images in CNN latent spaces. First, we study the impact of the distance metrics, comparing performances obtained with different metrics: the minimal Euclidean distance (MED), the minimal cosine distance (MCD), and the residue of the sparse coding reconstruction (RSCR). These metrics are applied using features extracted through five different CNN architectures, namely ResNet18, AlexNet, VGG16, InceptionV3 and DenseNet201. We use the specific vehicle re-identification dataset VeRI to fine-tune these CNNs and evaluate results. In overall, independently from the CNN used, MCD outperforms MED, commonly used in the literature. Secondly, the state-of-the-art image-to-track process (I2TP) is extended to a track-to-track process (T2TP) without using complementary metadata. Metrics are extended to measure distance between tracks, enabling the evaluation of T2TP and comparison with I2TP using the same CNN models. Results show that T2TP outperforms I2TP for MCD and RSCR. T2TP combining DenseNet201 and MCD-based metrics exhibits the best performances, outperforming the state-of-the-art I2TP models that use complementary metadata. Finally, our experiments highlight two main results: i) the importance of the metric choice for vehicle re-identification, and ii) T2TP improves the performances compared to I2TP, especially when coupled with MCD-based metrics.