 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Models for Phoneme Recognition: Applications in Children's Speech for Reading Learning
Mar 06, 2025Child speech recognition is still an underdeveloped area of research due to the lack of data (especially on non-English languages) and the specific difficulties of this task. Having explored various architectures for child speech recognition in previous work, in this article we tackle recent self-supervised models. We first compare wav2vec 2.0, HuBERT and WavLM models adapted to phoneme recognition in French child speech, and continue our experiments with the best of them, WavLM base+. We then further adapt it by unfreezing its transformer blocks during fine-tuning on child speech, which greatly improves its performance and makes it significantly outperform our base model, a Transformer+CTC. Finally, we study in detail the behaviour of these two models under the real conditions of our application, and show that WavLM base+ is more robust to various reading tasks and noise levels. Index Terms: speech recognition, child speech, self-supervised learning
Audio classification with Dilated Convolution with Learnable Spacings
Sep 25, 2023Dilated convolution with learnable spacings (DCLS) is a recent convolution method in which the positions of the kernel elements are learned throughout training by backpropagation. Its interest has recently been demonstrated in computer vision (ImageNet classification and downstream tasks). Here we show that DCLS is also useful for audio tagging using the AudioSet classification benchmark. We took two state-of-the-art convolutional architectures using depthwise separable convolutions (DSC), ConvNeXt and ConvFormer, and a hybrid one using attention in addition, FastViT, and drop-in replaced all the DSC layers by DCLS ones. This significantly improved the mean average precision (mAP) with the three architectures without increasing the number of parameters and with only a low cost on the throughput. The method code is based on PyTorch and is available at https://github.com/K-H-Ismail/DCLS-Audio
Multilingual Audio Captioning using machine translated data
Sep 14, 2023Automated Audio Captioning (AAC) systems attempt to generate a natural language sentence, a caption, that describes the content of an audio recording, in terms of sound events. Existing datasets provide audio-caption pairs, with captions written in English only. In this work, we explore multilingual AAC, using machine translated captions. We translated automatically two prominent AAC datasets, AudioCaps and Clotho, from English to French, German and Spanish. We trained and evaluated monolingual systems in the four languages, on AudioCaps and Clotho. In all cases, the models achieved similar performance, about 75% CIDEr on AudioCaps and 43% on Clotho. In French, we acquired manual captions of the AudioCaps eval subset. The French system, trained on the machine translated version of AudioCaps, achieved significantly better results on the manual eval subset, compared to the English system for which we automatically translated the outputs to French. This advocates in favor of building systems in a target language instead of simply translating to a target language the English captions from the English system. Finally, we built a multilingual model, which achieved results in each language comparable to each monolingual system, while using much less parameters than using a collection of monolingual systems.
CoNeTTE: An efficient Audio Captioning system leveraging multiple datasets with Task Embedding
Sep 01, 2023Automated Audio Captioning (AAC) involves generating natural language descriptions of audio content, using encoder-decoder architectures. An audio encoder produces audio embeddings fed to a decoder, usually a Transformer decoder, for caption generation. In this work, we describe our model, which novelty, compared to existing models, lies in the use of a ConvNeXt architecture as audio encoder, adapted from the vision domain to audio classification. This model, called CNext-trans, achieved state-of-the-art scores on the AudioCaps (AC) dataset and performed competitively on Clotho (CL), while using four to forty times fewer parameters than existing models. We examine potential biases in the AC dataset due to its origin from AudioSet by investigating unbiased encoder's impact on performance. Using the well-known PANN's CNN14, for instance, as an unbiased encoder, we observed a 1.7% absolute reduction in SPIDEr score (where higher scores indicate better performance). To improve cross-dataset performance, we conducted experiments by combining multiple AAC datasets (AC, CL, MACS, WavCaps) for training. Although this strategy enhanced overall model performance across datasets, it still fell short compared to models trained specifically on a single target dataset, indicating the absence of a one-size-fits-all model. To mitigate performance gaps between datasets, we introduced a Task Embedding (TE) token, allowing the model to identify the source dataset for each input sample. We provide insights into the impact of these TEs on both the form (words) and content (sound event types) of the generated captions. The resulting model, named CoNeTTE, an unbiased CNext-trans model enriched with dataset-specific Task Embeddings, achieved SPIDEr scores of 44.1% and 30.5% on AC and CL, respectively. Code available: https://github.com/Labbeti/conette-audio-captioning.
Killing two birds with one stone: Can an audio captioning system also be used for audio-text retrieval?
Aug 29, 2023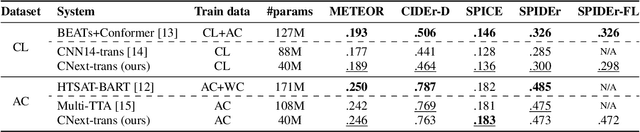
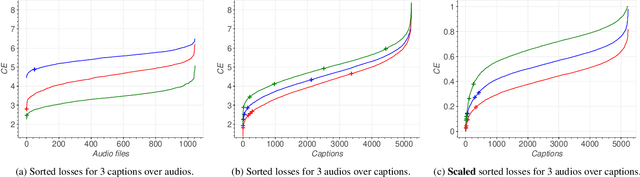
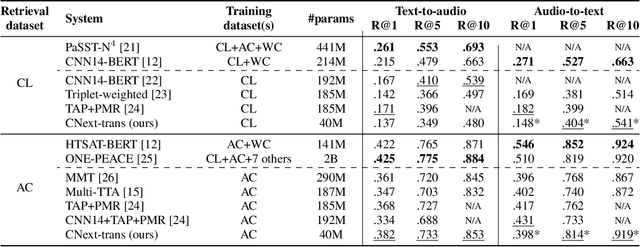
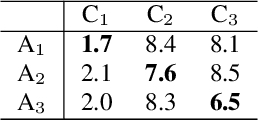
Automated Audio Captioning (AAC) aims to develop systems capable of describing an audio recording using a textual sentence. In contrast, Audio-Text Retrieval (ATR) systems seek to find the best matching audio recording(s) for a given textual query (Text-to-Audio) or vice versa (Audio-to-Text). These tasks require different types of systems: AAC employs a sequence-to-sequence model, while ATR utilizes a ranking model that compares audio and text representations within a shared projection subspace. However, this work investigates the relationship between AAC and ATR by exploring the ATR capabilities of an unmodified AAC system, without fine-tuning for the new task. Our AAC system consists of an audio encoder (ConvNeXt-Tiny) trained on AudioSet for audio tagging, and a transformer decoder responsible for generating sentences. For AAC, it achieves a high SPIDEr-FL score of 0.298 on Clotho and 0.472 on AudioCaps on average. For ATR, we propose using the standard Cross-Entropy loss values obtained for any audio/caption pair. Experimental results on the Clotho and AudioCaps datasets demonstrate decent recall values using this simple approach. For instance, we obtained a Text-to-Audio R@1 value of 0.382 for Au-dioCaps, which is above the current state-of-the-art method without external data. Interestingly, we observe that normalizing the loss values was necessary for Audio-to-Text retrieval.
* cam ready version (14/08/23)
Adapting a ConvNeXt model to audio classification on AudioSet
Jun 01, 2023In computer vision, convolutional neural networks (CNN) such as ConvNeXt, have been able to surpass state-of-the-art transformers, partly thanks to depthwise separable convolutions (DSC). DSC, as an approximation of the regular convolution, has made CNNs more efficient in time and memory complexity without deteriorating their accuracy, and sometimes even improving it. In this paper, we first implement DSC into the Pretrained Audio Neural Networks (PANN) family for audio classification on AudioSet, to show its benefits in terms of accuracy/model size trade-off. Second, we adapt the now famous ConvNeXt model to the same task. It rapidly overfits, so we report on techniques that improve the learning process. Our best ConvNeXt model reached 0.471 mean-average precision on AudioSet, which is better than or equivalent to recent large audio transformers, while using three times less parameters. We also achieved positive results in audio captioning and audio retrieval with this model. Our PyTorch source code and checkpoint models are available at https://github.com/topel/audioset-convnext-inf.
Dilated Convolution with Learnable Spacings: beyond bilinear interpolation
Jun 01, 2023



Dilated Convolution with Learnable Spacings (DCLS) is a recently proposed variation of the dilated convolution in which the spacings between the non-zero elements in the kernel, or equivalently their positions, are learnable. Non-integer positions are handled via interpolation. Thanks to this trick, positions have well-defined gradients. The original DCLS used bilinear interpolation, and thus only considered the four nearest pixels. Yet here we show that longer range interpolations, and in particular a Gaussian interpolation, allow improving performance on ImageNet1k classification on two state-of-the-art convolutional architectures (ConvNeXt and Conv\-Former), without increasing the number of parameters. The method code is based on PyTorch and is available at https://github.com/K-H-Ismail/Dilated-Convolution-with-Learnable-Spacings-PyTorch
Multitask learning in Audio Captioning: a sentence embedding regression loss acts as a regularizer
May 02, 2023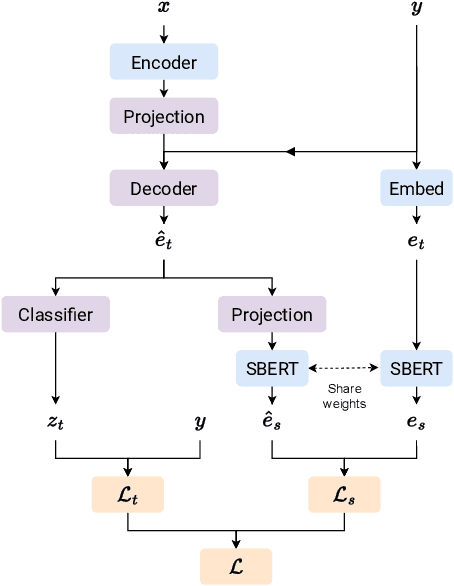
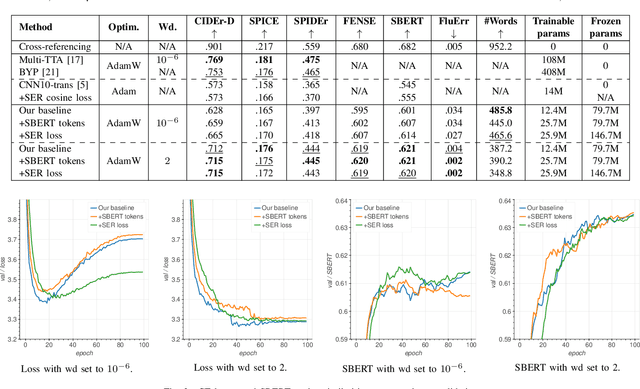
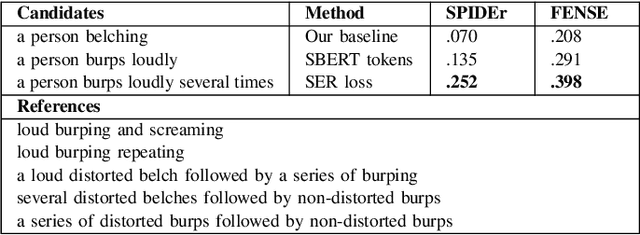
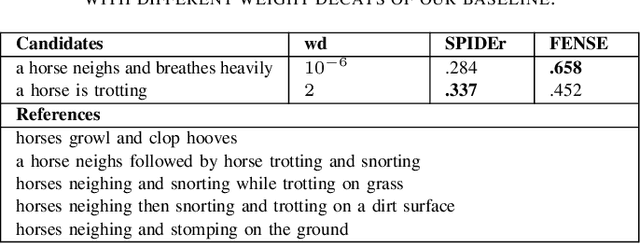
In this work, we propose to study the performance of a model trained with a sentence embedding regression loss component for the Automated Audio Captioning task. This task aims to build systems that can describe audio content with a single sentence written in natural language. Most systems are trained with the standard Cross-Entropy loss, which does not take into account the semantic closeness of the sentence. We found that adding a sentence embedding loss term reduces overfitting, but also increased SPIDEr from 0.397 to 0.418 in our first setting on the AudioCaps corpus. When we increased the weight decay value, we found our model to be much closer to the current state-of-the-art methods, with a SPIDEr score up to 0.444 compared to a 0.475 score. Moreover, this model uses eight times less trainable parameters. In this training setting, the sentence embedding loss has no more impact on the model performance.
Is my automatic audio captioning system so bad? spider-max: a metric to consider several caption candidates
Nov 14, 2022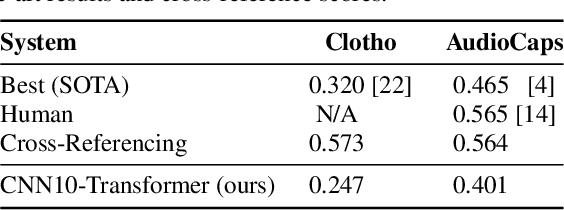
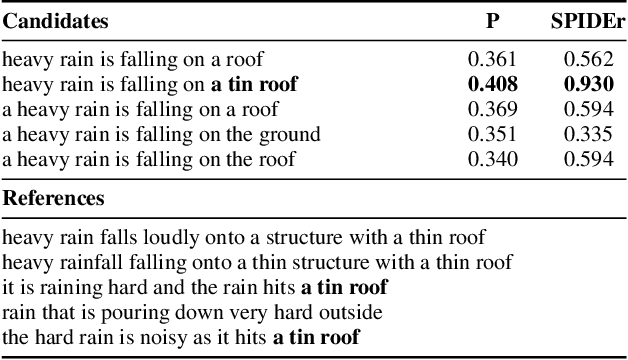
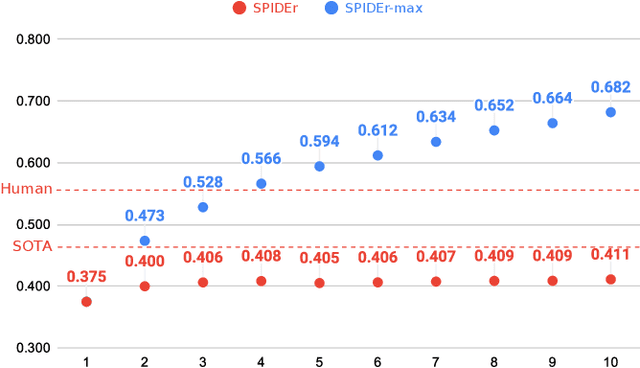
Automatic Audio Captioning (AAC) is the task that aims to describe an audio signal using natural language. AAC systems take as input an audio signal and output a free-form text sentence, called a caption. Evaluating such systems is not trivial, since there are many ways to express the same idea. For this reason, several complementary metrics, such as BLEU, CIDEr, SPICE and SPIDEr, are used to compare a single automatic caption to one or several captions of reference, produced by a human annotator. Nevertheless, an automatic system can produce several caption candidates, either using some randomness in the sentence generation process, or by considering the various competing hypothesized captions during decoding with beam-search, for instance. If we consider an end-user of an AAC system, presenting several captions instead of a single one seems relevant to provide some diversity, similarly to information retrieval systems. In this work, we explore the possibility to consider several predicted captions in the evaluation process instead of one. For this purpose, we propose SPIDEr-max, a metric that takes the maximum SPIDEr value among the scores of several caption candidates. To advocate for our metric, we report experiments on Clotho v2.1 and AudioCaps, with a transformed-based system. On AudioCaps for example, this system reached a SPIDEr-max value (with 5 candidates) close to the SPIDEr human score of reference.
Audio-video fusion strategies for active speaker detection in meetings
Jun 09, 2022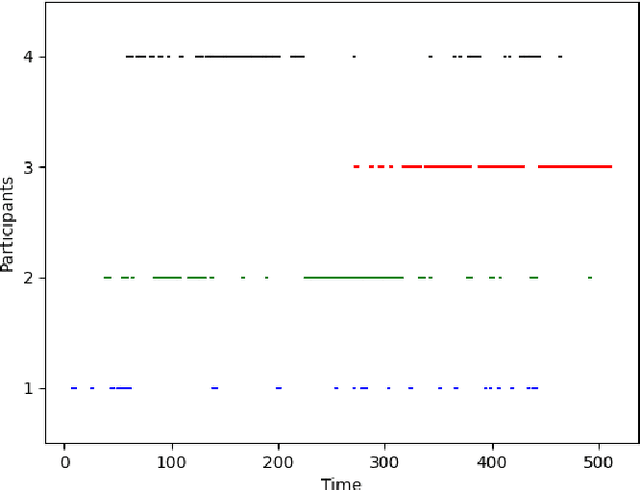



Meetings are a common activity in professional contexts, and it remains challenging to endow vocal assistants with advanced functionalities to facilitate meeting management. In this context, a task like active speaker detection can provide useful insights to model interaction between meeting participants. Motivated by our application context related to advanced meeting assistant, we want to combine audio and visual information to achieve the best possible performance. In this paper, we propose two different types of fusion for the detection of the active speaker, combining two visual modalities and an audio modality through neural networks. For comparison purpose, classical unsupervised approaches for audio feature extraction are also used. We expect visual data centered on the face of each participant to be very appropriate for detecting voice activity, based on the detection of lip and facial gestures. Thus, our baseline system uses visual data and we chose a 3D Convolutional Neural Network architecture, which is effective for simultaneously encoding appearance and movement. To improve this system, we supplemented the visual information by processing the audio stream with a CNN or an unsupervised speaker diarization system. We have further improved this system by adding visual modality information using motion through optical flow. We evaluated our proposal with a public and state-of-the-art benchmark: the AMI corpus. We analysed the contribution of each system to the merger carried out in order to determine if a given participant is currently speaking. We also discussed the results we obtained. Besides, we have shown that, for our application context, adding motion information greatly improves performance. Finally, we have shown that attention-based fusion improves performance while reducing the standard deviation.