 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Models for Phoneme Recognition: Applications in Children's Speech for Reading Learning
Mar 06, 2025Child speech recognition is still an underdeveloped area of research due to the lack of data (especially on non-English languages) and the specific difficulties of this task. Having explored various architectures for child speech recognition in previous work, in this article we tackle recent self-supervised models. We first compare wav2vec 2.0, HuBERT and WavLM models adapted to phoneme recognition in French child speech, and continue our experiments with the best of them, WavLM base+. We then further adapt it by unfreezing its transformer blocks during fine-tuning on child speech, which greatly improves its performance and makes it significantly outperform our base model, a Transformer+CTC. Finally, we study in detail the behaviour of these two models under the real conditions of our application, and show that WavLM base+ is more robust to various reading tasks and noise levels. Index Terms: speech recognition, child speech, self-supervised learning
End-to-end acoustic modelling for phone recognition of young readers
Mar 04, 2021
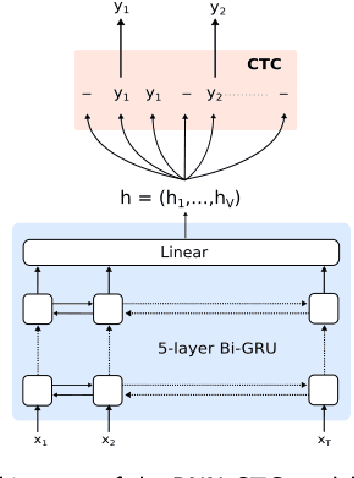

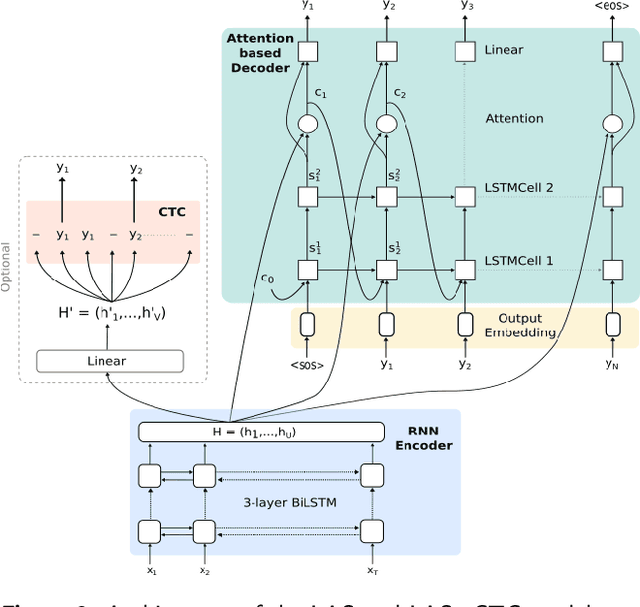
Automatic recognition systems for child speech are lagging behind those dedicated to adult speech in the race of performance. This phenomenon is due to the high acoustic and linguistic variability present in child speech caused by their body development, as well as the lack of available child speech data. Young readers speech additionally displays peculiarities, such as slow reading rate and presence of reading mistakes, that hardens the task. This work attempts to tackle the main challenges in phone acoustic modelling for young child speech with limited data, and improve understanding of strengths and weaknesses of a wide selection of model architectures in this domain. We find that transfer learning techniques are highly efficient on end-to-end architectures for adult-to-child adaptation with a small amount of child speech data. Through transfer learning, a Transformer model complemented with a Connectionist Temporal Classification (CTC) objective function, reaches a phone error rate of 28.1%, outperforming a state-of-the-art DNN-HMM model by 6.6% relative, as well as other end-to-end architectures by more than 8.5% relative. An analysis of the models' performance on two specific reading tasks (isolated words and sentences) is provided, showing the influence of the utterance length on attention-based and CTC-based models. The Transformer+CTC model displays an ability to better detect reading mistakes made by children, that can be attributed to the CTC objective function effectively constraining the attention mechanisms to be monotonic.