 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-video fusion strategies for active speaker detection in meetings
Jun 09, 2022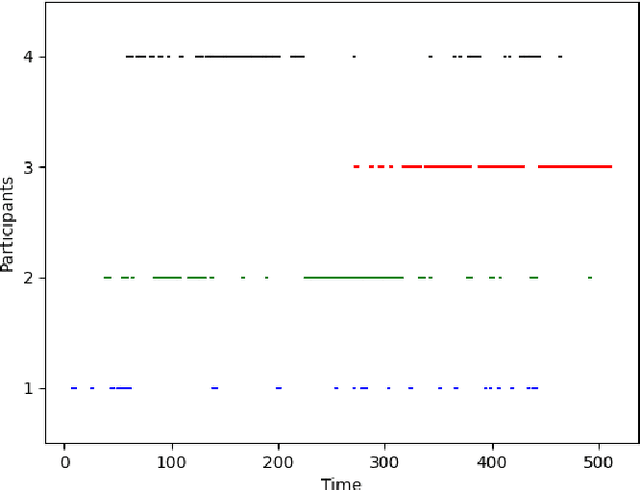



Meetings are a common activity in professional contexts, and it remains challenging to endow vocal assistants with advanced functionalities to facilitate meeting management. In this context, a task like active speaker detection can provide useful insights to model interaction between meeting participants. Motivated by our application context related to advanced meeting assistant, we want to combine audio and visual information to achieve the best possible performance. In this paper, we propose two different types of fusion for the detection of the active speaker, combining two visual modalities and an audio modality through neural networks. For comparison purpose, classical unsupervised approaches for audio feature extraction are also used. We expect visual data centered on the face of each participant to be very appropriate for detecting voice activity, based on the detection of lip and facial gestures. Thus, our baseline system uses visual data and we chose a 3D Convolutional Neural Network architecture, which is effective for simultaneously encoding appearance and movement. To improve this system, we supplemented the visual information by processing the audio stream with a CNN or an unsupervised speaker diarization system. We have further improved this system by adding visual modality information using motion through optical flow. We evaluated our proposal with a public and state-of-the-art benchmark: the AMI corpus. We analysed the contribution of each system to the merger carried out in order to determine if a given participant is currently speaking. We also discussed the results we obtained. Besides, we have shown that, for our application context, adding motion information greatly improves performance. Finally, we have shown that attention-based fusion improves performance while reducing the standard deviation.
Deep learning is a good steganalysis tool when embedding key is reused for different images, even if there is a cover source-mismatch
Jan 12, 2018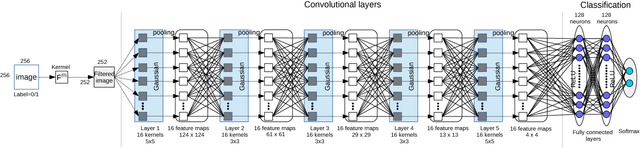

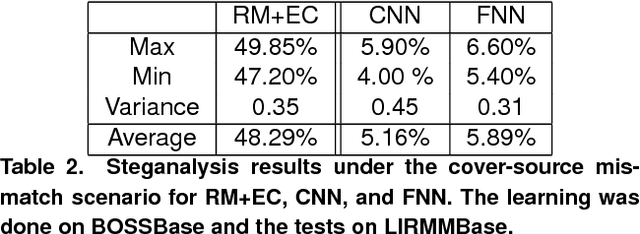

Since the BOSS competition, in 2010, most steganalysis approaches use a learning methodology involving two steps: feature extraction, such as the Rich Models (RM), for the image representation, and use of the Ensemble Classifier (EC) for the learning step. In 2015, Qian et al. have shown that the use of a deep learning approach that jointly learns and computes the features, is very promising for the steganalysis. In this paper, we follow-up the study of Qian et al., and show that, due to intrinsic joint minimization, the results obtained from a Convolutional Neural Network (CNN) or a Fully Connected Neural Network (FNN), if well parameterized, surpass the conventional use of a RM with an EC. First, numerous experiments were conducted in order to find the best " shape " of the CNN. Second, experiments were carried out in the clairvoyant scenario in order to compare the CNN and FNN to an RM with an EC. The results show more than 16% reduction in the classification error with our CNN or FNN. Third, experiments were also performed in a cover-source mismatch setting. The results show that the CNN and FNN are naturally robust to the mismatch problem. In Addition to the experiments, we provide discussions on the internal mechanisms of a CNN, and weave links with some previously stated ideas, in order to understand the impressive results we obtained.