 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Networks for Automatic Speech Processing: A Survey from Large Corpora to Limited Data
Paper and Code
Mar 09, 2020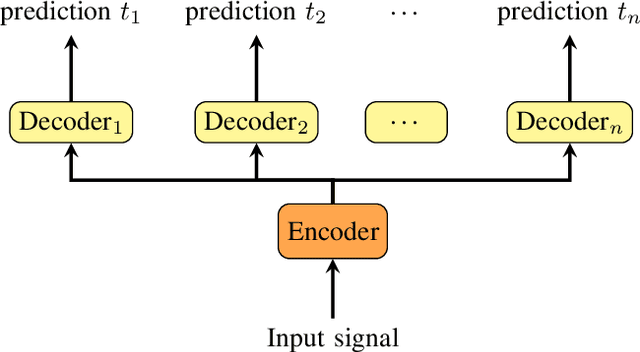
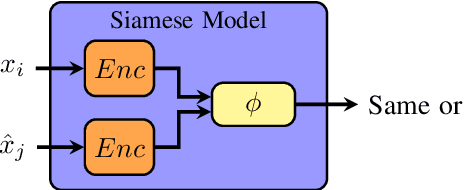
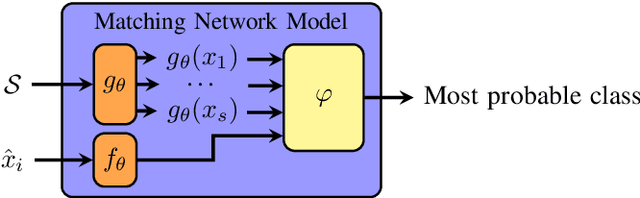
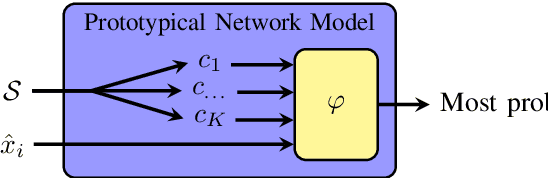
Most state-of-the-art speech systems are using Deep Neural Networks (DNNs). Those systems require a large amount of data to be learned. Hence, learning state-of-the-art frameworks on under-resourced speech languages/problems is a difficult task. Problems could be the limited amount of data for impaired speech. Furthermore, acquiring more data and/or expertise is time-consuming and expensive. In this paper we position ourselves for the following speech processing tasks: Automatic Speech Recognition, speaker identification and emotion recognition. To assess the problem of limited data, we firstly investigate state-of-the-art Automatic Speech Recognition systems as it represents the hardest tasks (due to the large variability in each language). Next, we provide an overview of techniques and tasks requiring fewer data. In the last section we investigate few-shot techniques as we interpret under-resourced speech as a few-shot problem. In that sense we propose an overview of few-shot techniques and perspectives of using such techniques for the focused speech problems in this survey. It occurs that the reviewed techniques are not well adapted for large datasets. Nevertheless, some promising results from the literature encourage the usage of such techniques for speech processing.