 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech inpainting: Context-based speech synthesis guided by video
Jun 01, 2023



Audio and visual modalities are inherently connected in speech signals: lip movements and facial expressions are correlated with speech sounds. This motivates studies that incorporate the visual modality to enhance an acoustic speech signal or even restore missing audio information. Specifically, this paper focuses on the problem of audio-visual speech inpainting, which is the task of synthesizing the speech in a corrupted audio segment in a way that it is consistent with the corresponding visual content and the uncorrupted audio context. We present an audio-visual transformer-based deep learning model that leverages visual cues that provide information about the content of the corrupted audio. It outperforms the previous state-of-the-art audio-visual model and audio-only baselines. We also show how visual features extracted with AV-HuBERT, a large audio-visual transformer for speech recognition, are suitable for synthesizing speech.
VocaLiST: An Audio-Visual Synchronisation Model for Lips and Voices
Apr 05, 2022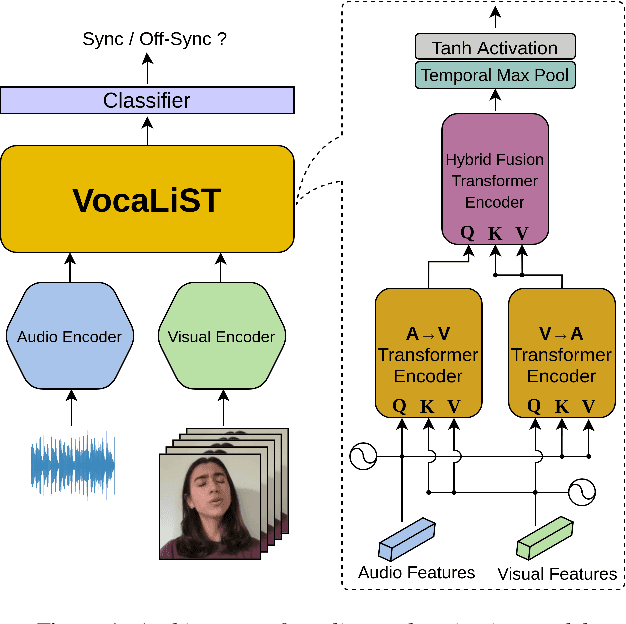



In this paper, we address the problem of lip-voice synchronisation in videos containing human face and voice. Our approach is based on determining if the lips motion and the voice in a video are synchronised or not, depending on their audio-visual correspondence score. We propose an audio-visual cross-modal transformer-based model that outperforms several baseline models in the audio-visual synchronisation task on the standard lip-reading speech benchmark dataset LRS2. While the existing methods focus mainly on the lip synchronisation in speech videos, we also consider the special case of singing voice. Singing voice is a more challenging use case for synchronisation due to sustained vowel sounds. We also investigate the relevance of lip synchronisation models trained on speech datasets in the context of singing voice. Finally, we use the frozen visual features learned by our lip synchronisation model in the singing voice separation task to outperform a baseline audio-visual model which was trained end-to-end. The demos, source code, and the pre-trained model will be made available on https://ipcv.github.io/VocaLiST/
VoViT: Low Latency Graph-based Audio-Visual Voice Separation Transformer
Mar 08, 2022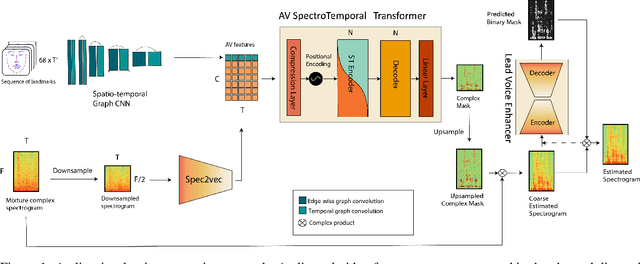
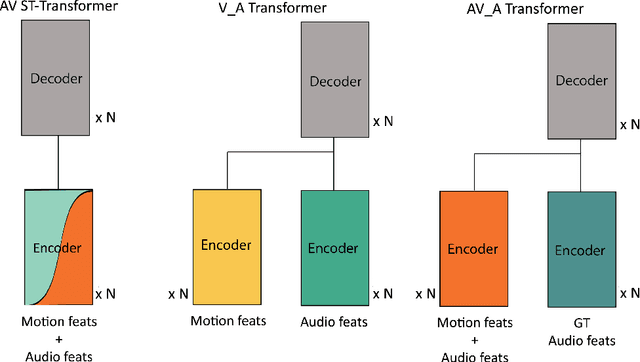

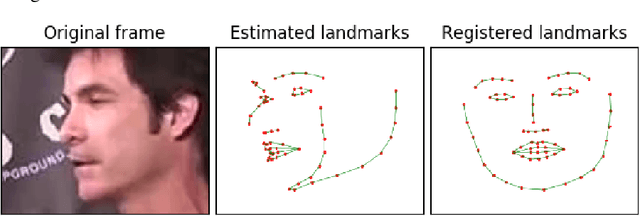
This paper presents an audio-visual approach for voice separation which outperforms state-of-the-art methods at a low latency in two scenarios: speech and singing voice. The model is based on a two-stage network. Motion cues are obtained with a lightweight graph convolutional network that processes face landmarks. Then, both audio and motion features are fed to an audio-visual transformer which produces a fairly good estimation of the isolated target source. In a second stage, the predominant voice is enhanced with an audio-only network. We present different ablation studies and comparison to state-of-the-art methods. Finally, we explore the transferability of models trained for speech separation in the task of singing voice separation. The demos, code, and weights will be made publicly available at https://ipcv.github.io/VoViT/
A cappella: Audio-visual Singing Voice Separation
Apr 20, 2021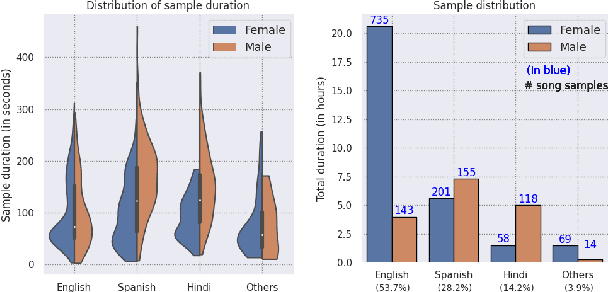

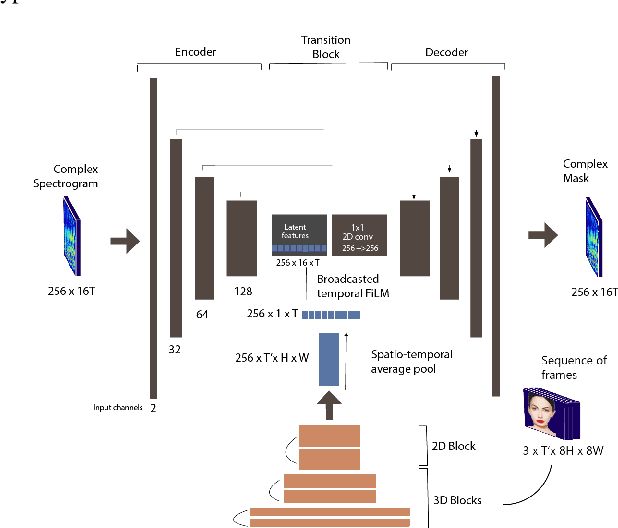
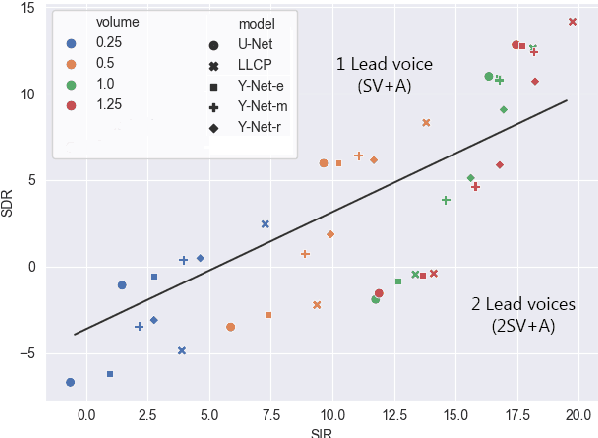
Music source separation can be interpreted as the estimation of the constituent music sources that a music clip is composed of. In this work, we explore the single-channel singing voice separation problem from a multimodal perspective, by jointly learning from audio and visual modalities. To do so, we present Acappella, a dataset spanning around 46 hours of a cappella solo singing videos sourced from YouTube. We propose Y-Net, an audio-visual convolutional neural network which achieves state-of-the-art singing voice separation results on the Acappella dataset and compare it against its audio-only counterpart, U-Net, and a state-of-the-art audio-visual speech separation model. Singing voice separation can be particularly challenging when the audio mixture also comprises of other accompaniment voices and background sounds along with the target voice of interest. We demonstrate that our model can outperform the baseline models in the singing voice separation task in such challenging scenarios. The code, the pre-trained models and the dataset will be publicly available at https://ipcv.github.io/Acappella/
Multi-task U-Net for Music Source Separation
Mar 23, 2020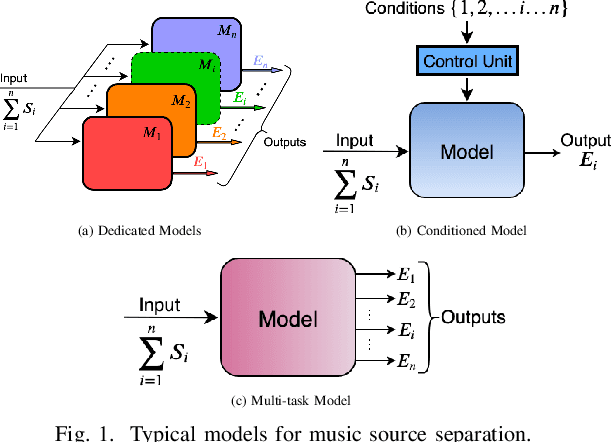


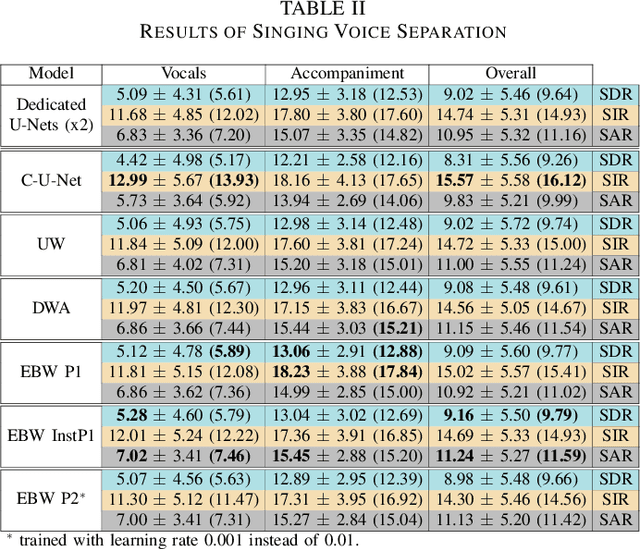
A fairly straightforward approach for music source separation is to train independent models, wherein each model is dedicated for estimating only a specific source. Training a single model to estimate multiple sources generally does not perform as well as the independent dedicated models. However, Conditioned U-Net (C-U-Net) uses a control mechanism to train a single model for multi-source separation and attempts to achieve a performance comparable to that of the dedicated models. We propose a multi-task U-Net (M-U-Net) trained using a weighted multi-task loss as an alternative to the C-U-Net. We investigate two weighting strategies for our multi-task loss: 1) Dynamic Weighted Average (DWA), and 2) Energy Based Weighting (EBW). DWA determines the weights by tracking the rate of change of loss of each task during training. EBW aims to neutralize the effect of the training bias arising from the difference in energy levels of each of the sources in a mixture. Our methods provide two-fold advantages compared to the C-U-Net: 1) Fewer effective training iterations with no conditioning, and 2) Fewer trainable network parameters (no control parameters). Our methods achieve performance comparable to that of C-U-Net and the dedicated U-Nets at a much lower training cost.