 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoViT: Low Latency Graph-based Audio-Visual Voice Separation Transformer
Paper and Code
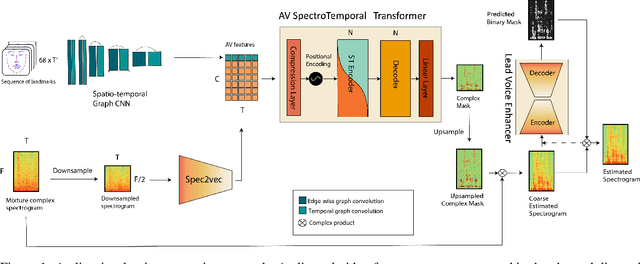
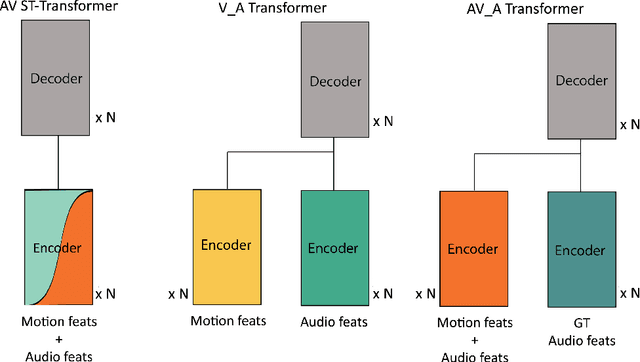

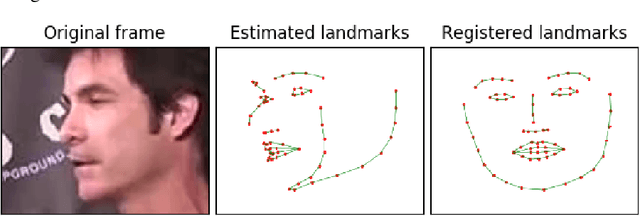
This paper presents an audio-visual approach for voice separation which outperforms state-of-the-art methods at a low latency in two scenarios: speech and singing voice. The model is based on a two-stage network. Motion cues are obtained with a lightweight graph convolutional network that processes face landmarks. Then, both audio and motion features are fed to an audio-visual transformer which produces a fairly good estimation of the isolated target source. In a second stage, the predominant voice is enhanced with an audio-only network. We present different ablation studies and comparison to state-of-the-art methods. Finally, we explore the transferability of models trained for speech separation in the task of singing voice separation. The demos, code, and weights will be made publicly available at https://ipcv.github.io/VoViT/