 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocaLiST: An Audio-Visual Synchronisation Model for Lips and Voices
Paper and Code
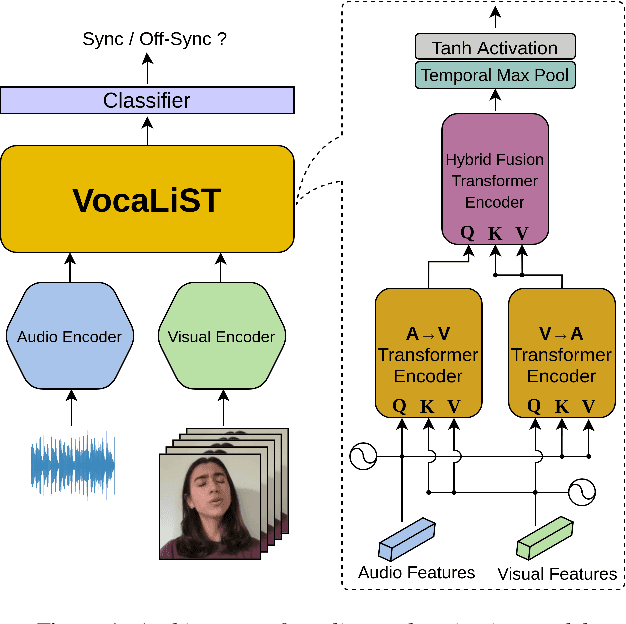



In this paper, we address the problem of lip-voice synchronisation in videos containing human face and voice. Our approach is based on determining if the lips motion and the voice in a video are synchronised or not, depending on their audio-visual correspondence score. We propose an audio-visual cross-modal transformer-based model that outperforms several baseline models in the audio-visual synchronisation task on the standard lip-reading speech benchmark dataset LRS2. While the existing methods focus mainly on the lip synchronisation in speech videos, we also consider the special case of singing voice. Singing voice is a more challenging use case for synchronisation due to sustained vowel sounds. We also investigate the relevance of lip synchronisation models trained on speech datasets in the context of singing voice. Finally, we use the frozen visual features learned by our lip synchronisation model in the singing voice separation task to outperform a baseline audio-visual model which was trained end-to-end. The demos, source code, and the pre-trained model will be made available on https://ipcv.github.io/VocaLiST/