 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA cappella: Audio-visual Singing Voice Separation
Paper and Code
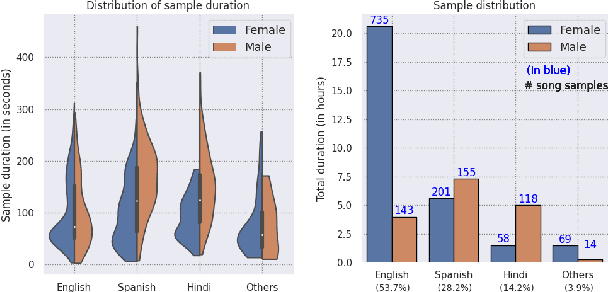

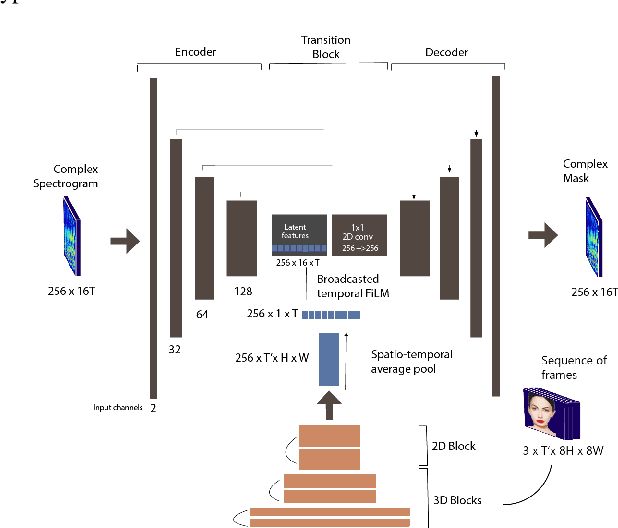
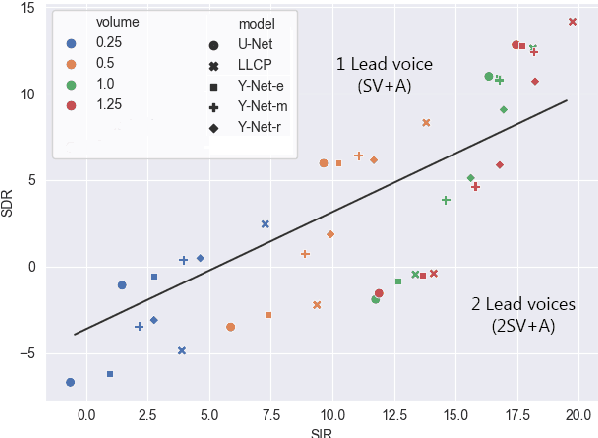
Music source separation can be interpreted as the estimation of the constituent music sources that a music clip is composed of. In this work, we explore the single-channel singing voice separation problem from a multimodal perspective, by jointly learning from audio and visual modalities. To do so, we present Acappella, a dataset spanning around 46 hours of a cappella solo singing videos sourced from YouTube. We propose Y-Net, an audio-visual convolutional neural network which achieves state-of-the-art singing voice separation results on the Acappella dataset and compare it against its audio-only counterpart, U-Net, and a state-of-the-art audio-visual speech separation model. Singing voice separation can be particularly challenging when the audio mixture also comprises of other accompaniment voices and background sounds along with the target voice of interest. We demonstrate that our model can outperform the baseline models in the singing voice separation task in such challenging scenarios. The code, the pre-trained models and the dataset will be publicly available at https://ipcv.github.io/Acappella/