 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-splatting: Maximizing Isotropic Constraints for Refined Optimization in 3D Gaussian Splatting
Apr 08, 2025



Recent advancements in 3D Gaussian Splatting have achieved impressive scalability and real-time rendering for large-scale scenes but often fall short in capturing fine-grained details. Conventional approaches that rely on relatively large covariance parameters tend to produce blurred representations, while directly reducing covariance sizes leads to sparsity. In this work, we introduce Micro-splatting (Maximizing Isotropic Constraints for Refined Optimization in 3D Gaussian Splatting), a novel framework designed to overcome these limitations. Our approach leverages a covariance regularization term to penalize excessively large Gaussians to ensure each splat remains compact and isotropic. This work implements an adaptive densification strategy that dynamically refines regions with high image gradients by lowering the splitting threshold, followed by loss function enhancement. This strategy results in a denser and more detailed gaussian means where needed, without sacrificing rendering efficiency. Quantitative evaluations using metrics such as L1, L2, PSNR, SSIM, and LPIPS, alongside qualitative comparisons demonstrate that our method significantly enhances fine-details in 3D reconstructions.
A Practical Gated Recurrent Transformer Network Incorporating Multiple Fusions for Video Denoising
Sep 10, 2024State-of-the-art (SOTA) video denoising methods employ multi-frame simultaneous denoising mechanisms, resulting in significant delays (e.g., 16 frames), making them impractical for real-time cameras. To overcome this limitation, we propose a multi-fusion gated recurrent Transformer network (GRTN) that achieves SOTA denoising performance with only a single-frame delay. Specifically, the spatial denoising module extracts features from the current frame, while the reset gate selects relevant information from the previous frame and fuses it with current frame features via the temporal denoising module. The update gate then further blends this result with the previous frame features, and the reconstruction module integrates it with the current frame. To robustly compute attention for noisy features, we propose a residual simplified Swin Transformer with Euclidean distance (RSSTE) in the spatial and temporal denoising modules. Comparative objective and subjective results show that our GRTN achieves denoising performance comparable to SOTA multi-frame delay networks, with only a single-frame delay.
Gated Recurrent Unit for Video Denoising
Oct 17, 2022

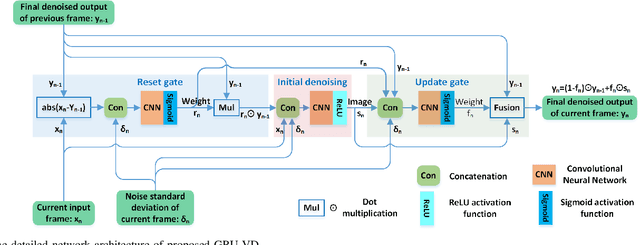

Current video denoising methods perform temporal fusion by designing convolutional neural networks (CNN) or combine spatial denoising with temporal fusion into basic recurrent neural networks (RNNs). However, there have not yet been works which adapt gated recurrent unit (GRU) mechanisms for video denoising. In this letter, we propose a new video denoising model based on GRU, namely GRU-VD. First, the reset gate is employed to mark the content related to the current frame in the previous frame output. Then the hidden activation works as an initial spatial-temporal denoising with the help from the marked relevant content. Finally, the update gate recursively fuses the initial denoised result with previous frame output to further increase accuracy. To handle various light conditions adaptively, the noise standard deviation of the current frame is also fed to these three modules. A weighted loss is adopted to regulate initial denoising and final fusion at the same time. The experimental results show that the GRU-VD network not only can achieve better quality than state of the arts objectively and subjectively, but also can obtain satisfied subjective quality on real video.
Towards fully automated post-event data collection and analysis: pre-event and post-event information fusion
Jun 30, 2019



In post-event reconnaissance missions, engineers and researchers collect perishable information about damaged buildings in the affected geographical region to learn from the consequences of the event. A typical post-event reconnaissance mission is conducted by first doing a preliminary survey, followed by a detailed survey. The preliminary survey is typically conducted by driving slowly along a pre-determined route, observing the damage, and noting where further detailed data should be collected. This involves several manual, time-consuming steps that can be accelerated by exploiting recent advances in computer vision and artificial intelligence. The objective of this work is to develop and validate an automated technique to support post-event reconnaissance teams in the rapid collection of reliable and sufficiently comprehensive data, for planning the detailed survey. The technique incorporates several methods designed to automate the process of categorizing buildings based on their key physical attributes, and rapidly assessing their post-event structural condition. It is divided into pre-event and post-event streams, each intending to first extract all possible information about the target buildings using both pre-event and post-event images. Algorithms based on convolutional neural network (CNNs) are implemented for scene (image) classification. A probabilistic approach is developed to fuse the results obtained from analyzing several images to yield a robust decision regarding the attributes and condition of a target building. We validate the technique using post-event images captured during reconnaissance missions that took place after hurricanes Harvey and Irma. The validation data were collected by a structural wind and coastal engineering reconnaissance team, the National Science Foundation (NSF) funded Structural Extreme Events Reconnaissance (StEER) Network.