 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Precision Policy Distillation with Application to Low-Power, Real-time Sensation-Cognition-Action Loop with Neuromorphic Computing
Sep 25, 2018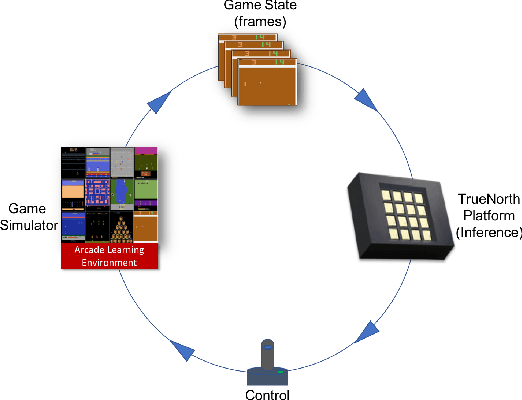
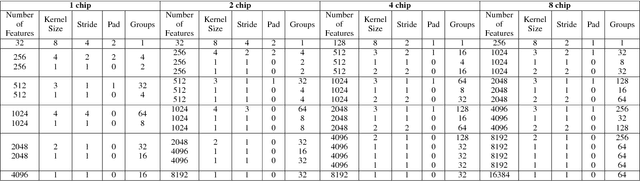
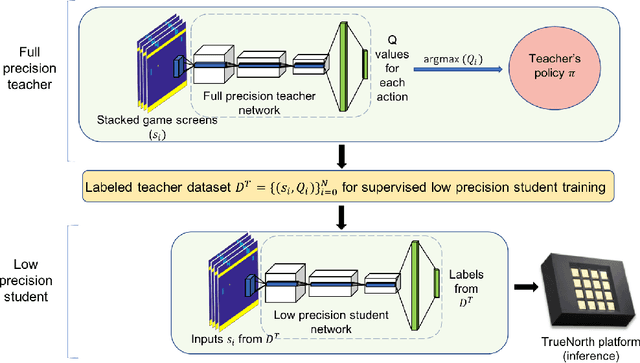
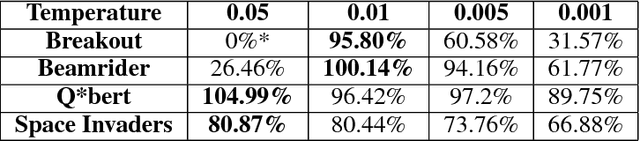
Low precision networks in the reinforcement learning (RL) setting are relatively unexplored because of the limitations of binary activations for function approximation. Here, in the discrete action ATARI domain, we demonstrate, for the first time, that low precision policy distillation from a high precision network provides a principled, practical way to train an RL agent. As an application, on 10 different ATARI games, we demonstrate real-time end-to-end game playing on low-power neuromorphic hardware by converting a sequence of game frames into discrete actions.
Discovering Low-Precision Networks Close to Full-Precision Networks for Efficient Embedded Inference
Sep 11, 2018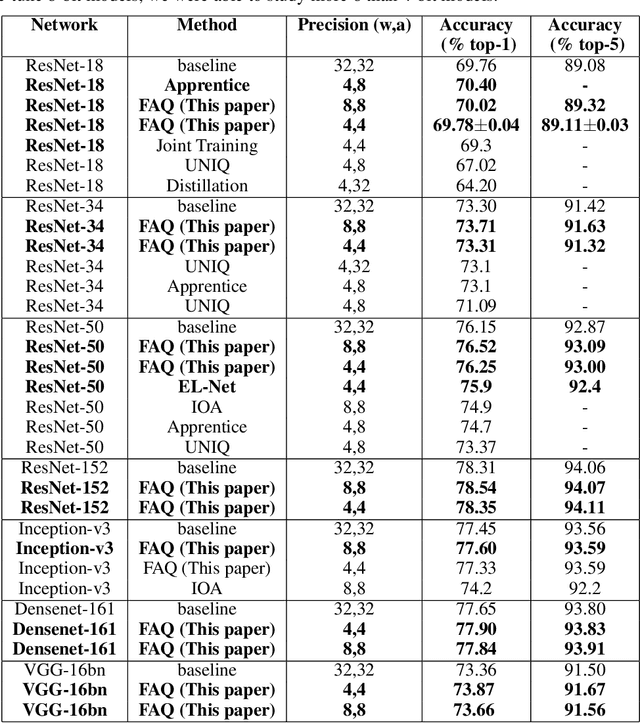
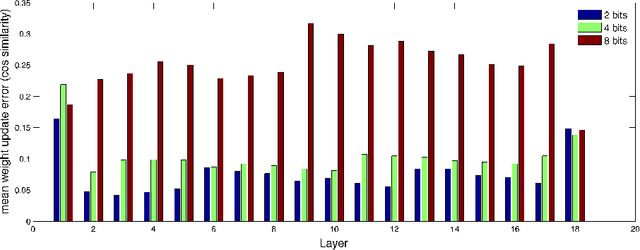
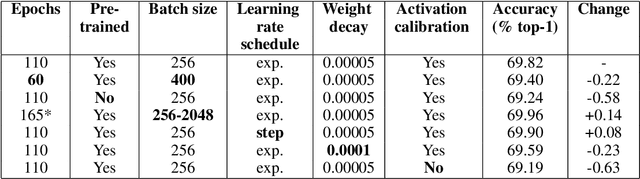

To realize the promise of ubiquitous embedded deep network inference, it is essential to seek limits of energy and area efficiency. To this end, low-precision networks offer tremendous promise because both energy and area scale down quadratically with the reduction in precision. Here, for the first time, we demonstrate ResNet-18, ResNet-34, ResNet-50, ResNet-152, Inception-v3, densenet-161, and VGG-16bn networks on the ImageNet classification benchmark that, at 8-bit precision exceed the accuracy of the full-precision baseline networks after one epoch of finetuning, thereby leveraging the availability of pretrained models. We also demonstrate for the first time ResNet-18, ResNet-34, and ResNet-50 4-bit models that match the accuracy of the full-precision baseline networks. Surprisingly, the weights of the low-precision networks are very close (in cosine similarity) to the weights of the corresponding baseline networks, making training from scratch unnecessary. The number of iterations required by stochastic gradient descent to achieve a given training error is related to the square of (a) the distance of the initial solution from the final plus (b) the maximum variance of the gradient estimates. By drawing inspiration from this observation, we (a) reduce solution distance by starting with pretrained fp32 precision baseline networks and fine-tuning, and (b) combat noise introduced by quantizing weights and activations during training, by using larger batches along with matched learning rate annealing. Together, these two techniques offer a promising heuristic to discover low-precision networks, if they exist, close to fp32 precision baseline networks.
Convolutional Networks for Fast, Energy-Efficient Neuromorphic Computing
May 24, 2016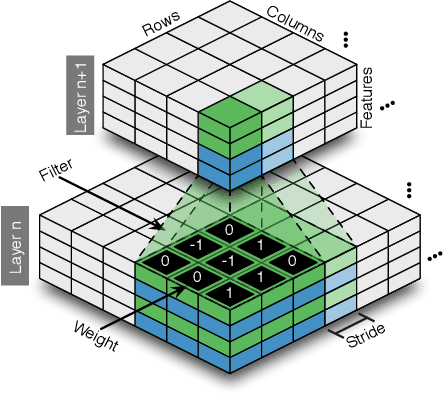
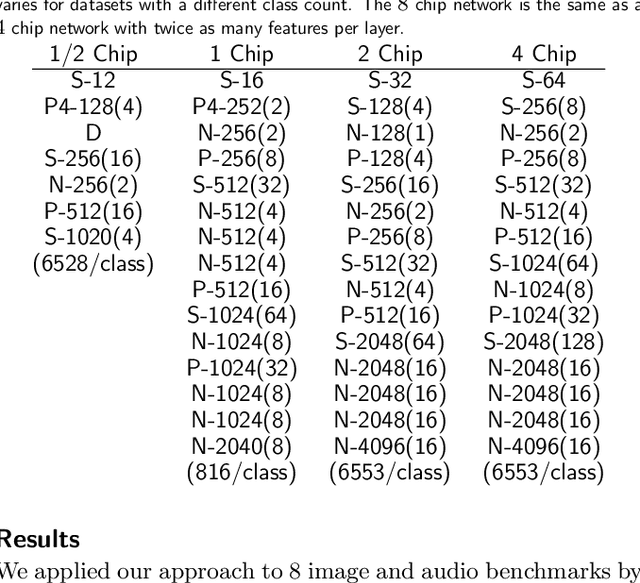
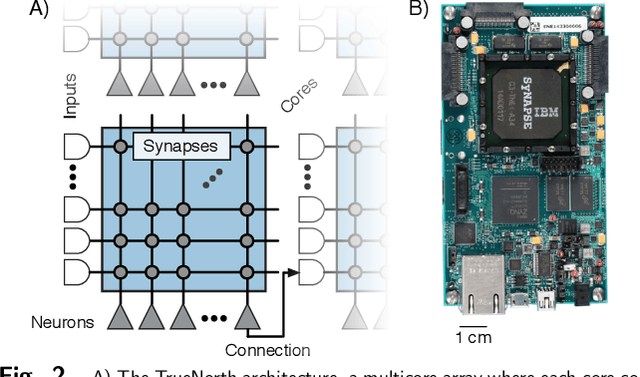

Deep networks are now able to achieve human-level performance on a broad spectrum of recognition tasks. Independently, neuromorphic computing has now demonstrated unprecedented energy-efficiency through a new chip architecture based on spiking neurons, low precision synapses, and a scalable communication network. Here, we demonstrate that neuromorphic computing, despite its novel architectural primitives, can implement deep convolution networks that i) approach state-of-the-art classification accuracy across 8 standard datasets, encompassing vision and speech, ii) perform inference while preserving the hardware's underlying energy-efficiency and high throughput, running on the aforementioned datasets at between 1200 and 2600 frames per second and using between 25 and 275 mW (effectively > 6000 frames / sec / W) and iii) can be specified and trained using backpropagation with the same ease-of-use as contemporary deep learning. For the first time, the algorithmic power of deep learning can be merged with the efficiency of neuromorphic processors, bringing the promise of embedded, intelligent, brain-inspired computing one step closer.
* 7 pages, 6 figures
Mapping Generative Models onto a Network of Digital Spiking Neurons
Oct 09, 2015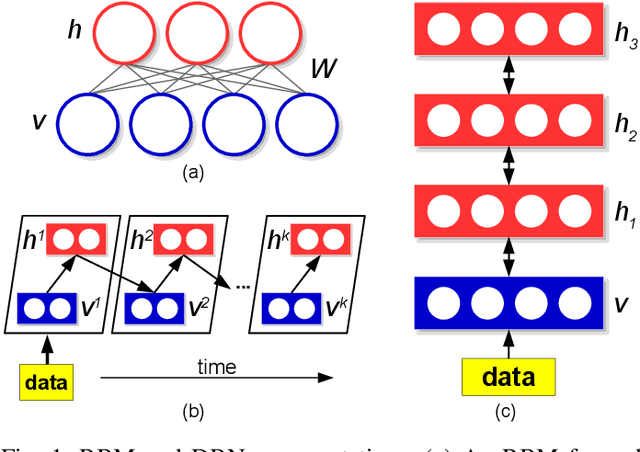
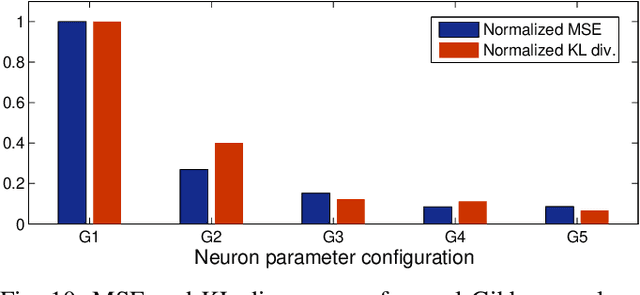
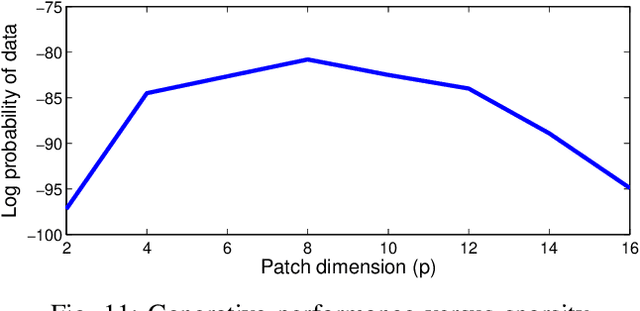
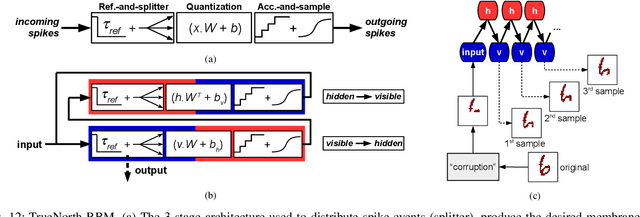
Stochastic neural networks such as Restricted Boltzmann Machines (RBMs) have been successfully used in applications ranging from speech recognition to image classification. Inference and learning in these algorithms use a Markov Chain Monte Carlo procedure called Gibbs sampling, where a logistic function forms the kernel of this sampler. On the other side of the spectrum, neuromorphic systems have shown great promise for low-power and parallelized cognitive computing, but lack well-suited applications and automation procedures. In this work, we propose a systematic method for bridging the RBM algorithm and digital neuromorphic systems, with a generative pattern completion task as proof of concept. For this, we first propose a method of producing the Gibbs sampler using bio-inspired digital noisy integrate-and-fire neurons. Next, we describe the process of mapping generative RBMs trained offline onto the IBM TrueNorth neurosynaptic processor -- a low-power digital neuromorphic VLSI substrate. Mapping these algorithms onto neuromorphic hardware presents unique challenges in network connectivity and weight and bias quantization, which, in turn, require architectural and design strategies for the physical realization. Generative performance metrics are analyzed to validate the neuromorphic requirements and to best select the neuron parameters for the model. Lastly, we describe a design automation procedure which achieves optimal resource usage, accounting for the novel hardware adaptations. This work represents the first implementation of generative RBM inference on a neuromorphic VLSI substrate.