Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Precision Policy Distillation with Application to Low-Power, Real-time Sensation-Cognition-Action Loop with Neuromorphic Computing
Paper and Code
Sep 25, 2018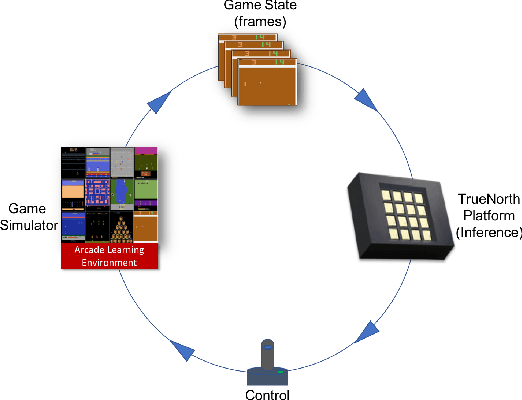
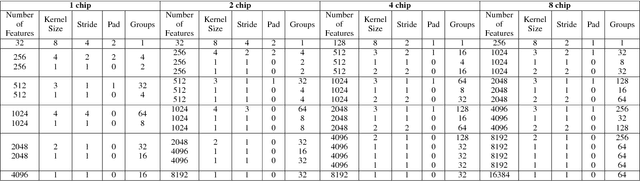
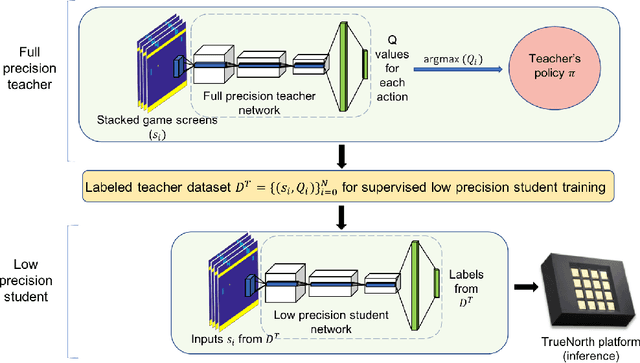
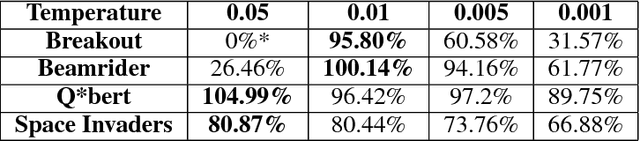
Low precision networks in the reinforcement learning (RL) setting are relatively unexplored because of the limitations of binary activations for function approximation. Here, in the discrete action ATARI domain, we demonstrate, for the first time, that low precision policy distillation from a high precision network provides a principled, practical way to train an RL agent. As an application, on 10 different ATARI games, we demonstrate real-time end-to-end game playing on low-power neuromorphic hardware by converting a sequence of game frames into discrete actions.
View paper on