 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe case for delegated AI autonomy for Human AI teaming in healthcare
Mar 24, 2025In this paper we propose an advanced approach to integrating artificial intelligence (AI) into healthcare: autonomous decision support. This approach allows the AI algorithm to act autonomously for a subset of patient cases whilst serving a supportive role in other subsets of patient cases based on defined delegation criteria. By leveraging the complementary strengths of both humans and AI, it aims to deliver greater overall performance than existing human-AI teaming models. It ensures safe handling of patient cases and potentially reduces clinician review time, whilst being mindful of AI tool limitations. After setting the approach within the context of current human-AI teaming models, we outline the delegation criteria and apply them to a specific AI-based tool used in histopathology. The potential impact of the approach and the regulatory requirements for its successful implementation are then discussed.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Safety Analysis of Autonomous Railway Systems: An Introduction to the SACRED Methodology
Mar 18, 2024



As the railway industry increasingly seeks to introduce autonomy and machine learning (ML), several questions arise. How can safety be assured for such systems and technologies? What is the applicability of current safety standards within this new technological landscape? What are the key metrics to classify a system as safe? Currently, safety analysis for the railway reflects the failure modes of existing technology; in contrast, the primary concern of analysis of automation is typically average performance. Such purely statistical approaches to measuring ML performance are limited, as they may overlook classes of situations that may occur rarely but in which the function performs consistently poorly. To combat these difficulties we introduce SACRED, a safety methodology for producing an initial safety case and determining important safety metrics for autonomous systems. The development of SACRED is motivated by the proposed GoA-4 light-rail system in Berlin.
Unravelling Responsibility for AI
Aug 04, 2023



To reason about where responsibility does and should lie in complex situations involving AI-enabled systems, we first need a sufficiently clear and detailed cross-disciplinary vocabulary for talking about responsibility. Responsibility is a triadic relation involving an actor, an occurrence, and a way of being responsible. As part of a conscious effort towards 'unravelling' the concept of responsibility to support practical reasoning about responsibility for AI, this paper takes the three-part formulation, 'Actor A is responsible for Occurrence O' and identifies valid combinations of subcategories of A, is responsible for, and O. These valid combinations - which we term "responsibility strings" - are grouped into four senses of responsibility: role-responsibility; causal responsibility; legal liability-responsibility; and moral responsibility. They are illustrated with two running examples, one involving a healthcare AI-based system and another the fatal collision of an AV with a pedestrian in Tempe, Arizona in 2018. The output of the paper is 81 responsibility strings. The aim is that these strings provide the vocabulary for people across disciplines to be clear and specific about the different ways that different actors are responsible for different occurrences within a complex event for which responsibility is sought, allowing for precise and targeted interdisciplinary normative deliberations.
Safety Assessment for Autonomous Systems' Perception Capabilities
Aug 18, 2022
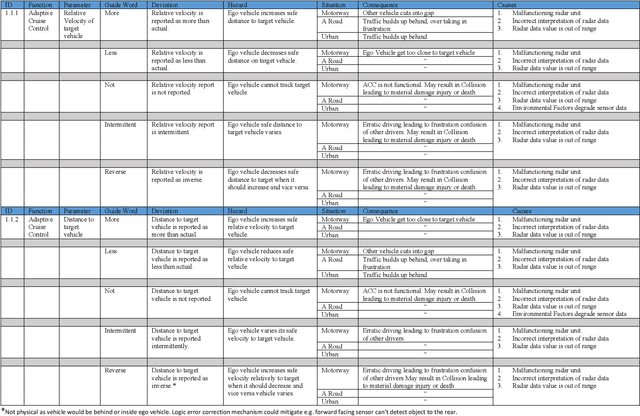

Autonomous Systems (AS) are increasingly proposed, or used, in Safety Critical (SC) applications. Many such systems make use of sophisticated sensor suites and processing to provide scene understanding which informs the AS' decision-making. The sensor processing typically makes use of Machine Learning (ML) and has to work in challenging environments, further the ML-algorithms have known limitations,e.g., the possibility of false-negatives or false-positives in object classification. The well-established safety-analysis methods developed for conventional SC systems are not well-matched to AS, ML, or the sensing systems used by AS. This paper proposes an adaptation of well-established safety-analysis methods to address the specifics of perception-systems for AS, including addressing environmental effects and the potential failure-modes of ML, and provides a rationale for choosing particular sets of guidewords, or prompts, for safety-analysis. It goes on to show how the results of the analysis can be used to inform the design and verification of the AS and illustrates the new method by presenting a partial analysis of a road vehicle. Illustrations in the paper are primarily based on optical sensing, however the paper discusses the applicability of the method to other sensing modalities and its role in a wider safety process addressing the overall capabilities of AS.
A Principle-based Ethical Assurance Argument for AI and Autonomous Systems
Mar 29, 2022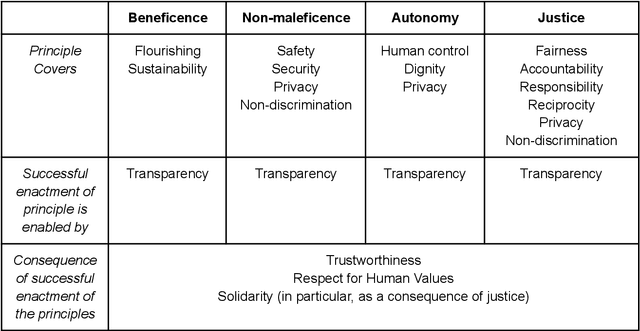

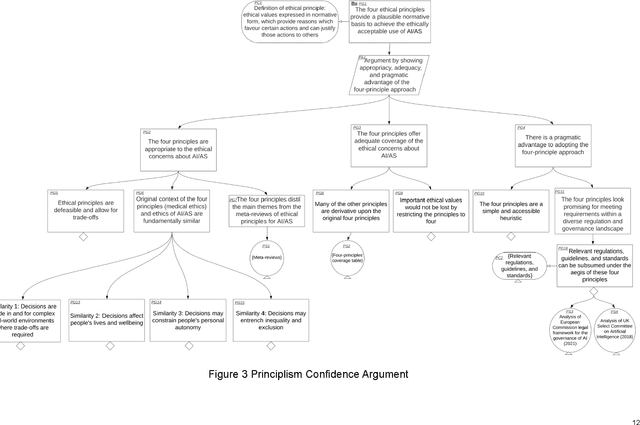
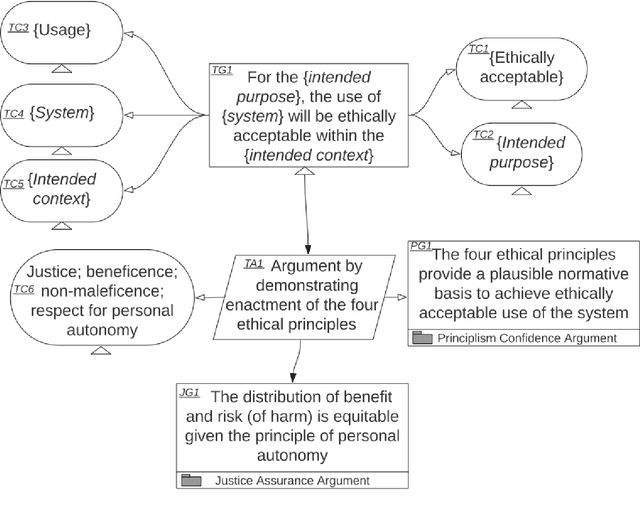
An assurance case presents a clear and defensible argument, supported by evidence, that a system will operate as intended in a particular context. Assurance cases often inform third party certification of a system. One emerging proposal within the trustworthy AI and Autonomous Systems (AS) research community is to extend and apply the assurance case methodology to achieve justified confidence that a system will be ethically acceptable when used in a particular context. In this paper, we develop and further advance this proposal, in order to bring the idea of ethical assurance cases to life. First, we discuss the assurance case methodology and the Goal Structuring Notation (GSN), which is a graphical notation that is widely used to record and present assurance cases. Second, we describe four core ethical principles to guide the design and deployment of AI/AS: justice; beneficence; non-maleficence; and respect for personal autonomy. Third, we bring these two components together and structure an ethical assurance argument pattern - a reusable template for ethical assurance cases - on the basis of the four ethical principles. We call this a Principle-based Ethical Assurance Argument pattern. Throughout, we connect stages of the argument to examples of AI/AS applications and contexts. This helps to show the initial plausibility of the proposed methodology.
The Role of Explainability in Assuring Safety of Machine Learning in Healthcare
Sep 01, 2021
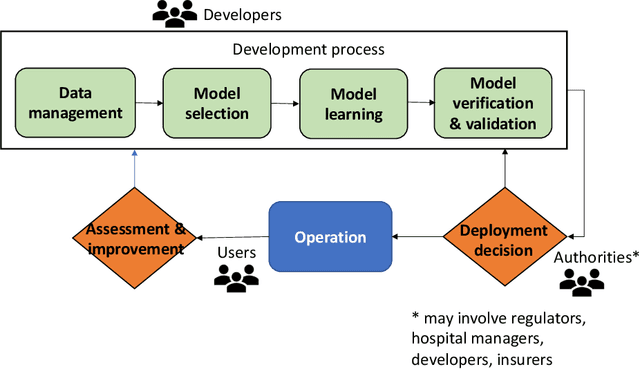
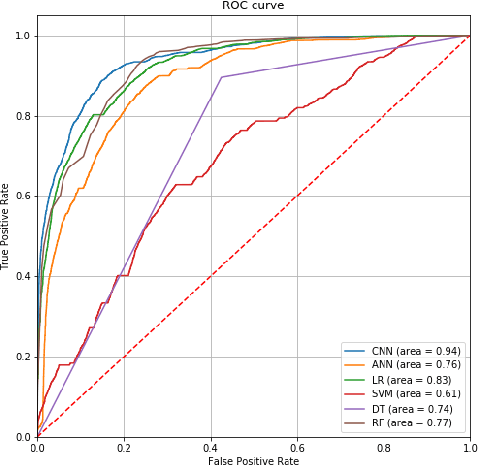
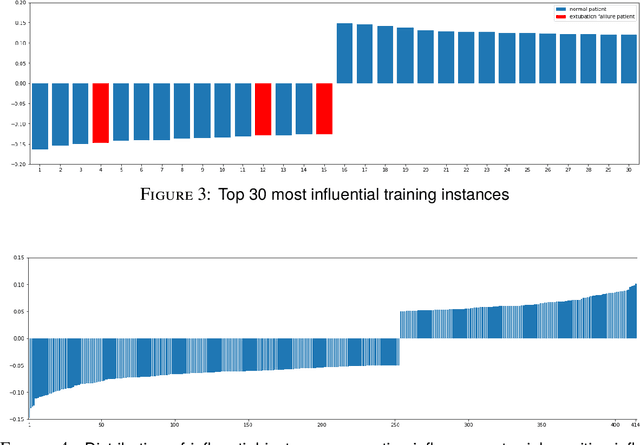
Established approaches to assuring safety-critical systems and software are difficult to apply to systems employing machine learning (ML). In many cases, ML is used on ill-defined problems, e.g. optimising sepsis treatment, where there is no clear, pre-defined specification against which to assess validity. This problem is exacerbated by the "opaque" nature of ML where the learnt model is not amenable to human scrutiny. Explainable AI methods have been proposed to tackle this issue by producing human-interpretable representations of ML models which can help users to gain confidence and build trust in the ML system. However, there is not much work explicitly investigating the role of explainability for safety assurance in the context of ML development. This paper identifies ways in which explainable AI methods can contribute to safety assurance of ML-based systems. It then uses a concrete ML-based clinical decision support system, concerning weaning of patients from mechanical ventilation, to demonstrate how explainable AI methods can be employed to produce evidence to support safety assurance. The results are also represented in a safety argument to show where, and in what way, explainable AI methods can contribute to a safety case. Overall, we conclude that explainable AI methods have a valuable role in safety assurance of ML-based systems in healthcare but that they are not sufficient in themselves to assure safety.
A Framework for Assurance of Medication Safety using Machine Learning
Jan 11, 2021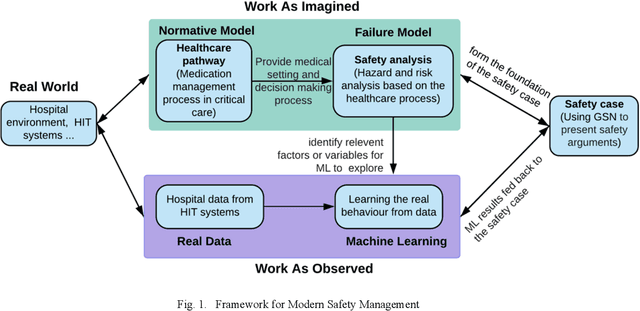
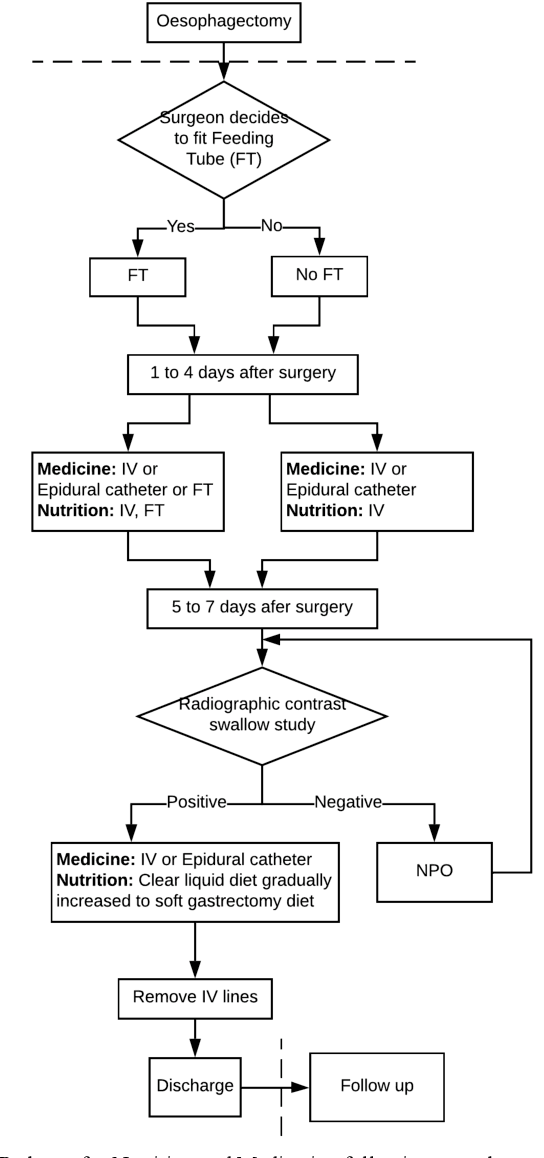
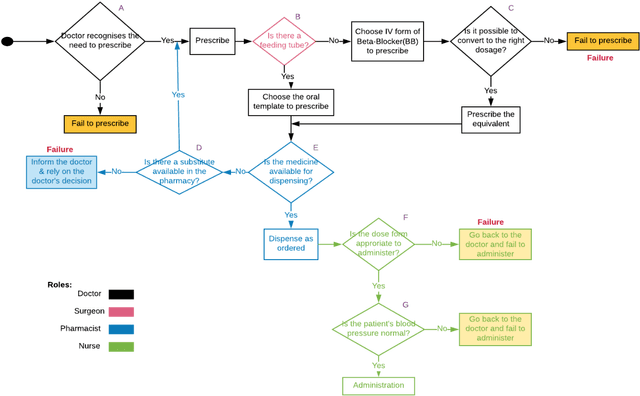
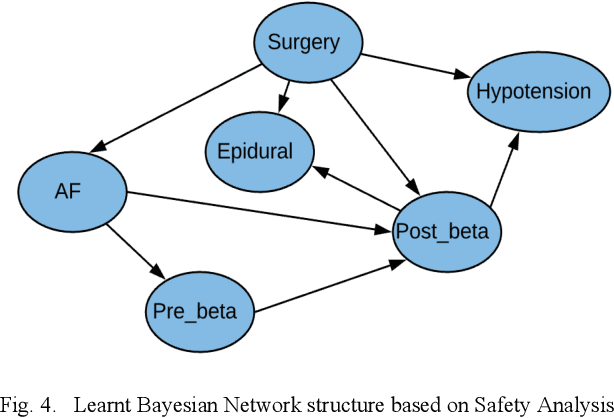
Medication errors continue to be the leading cause of avoidable patient harm in hospitals. This paper sets out a framework to assure medication safety that combines machine learning and safety engineering methods. It uses safety analysis to proactively identify potential causes of medication error, based on expert opinion. As healthcare is now data rich, it is possible to augment safety analysis with machine learning to discover actual causes of medication error from the data, and to identify where they deviate from what was predicted in the safety analysis. Combining these two views has the potential to enable the risk of medication errors to be managed proactively and dynamically. We apply the framework to a case study involving thoracic surgery, e.g. oesophagectomy, where errors in giving beta-blockers can be critical to control atrial fibrillation. This case study combines a HAZOP-based safety analysis method known as SHARD with Bayesian network structure learning and process mining to produce the analysis results, showing the potential of the framework for ensuring patient safety, and for transforming the way that safety is managed in complex healthcare environments.