 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Molecular Representation in a Cell
Jun 17, 2024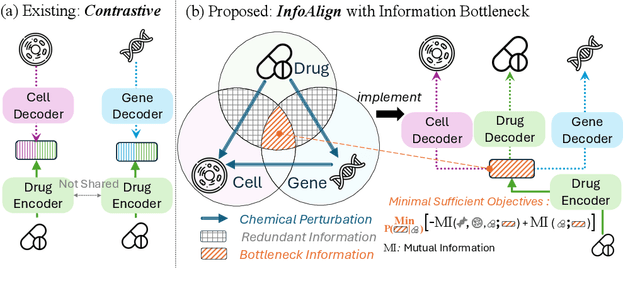

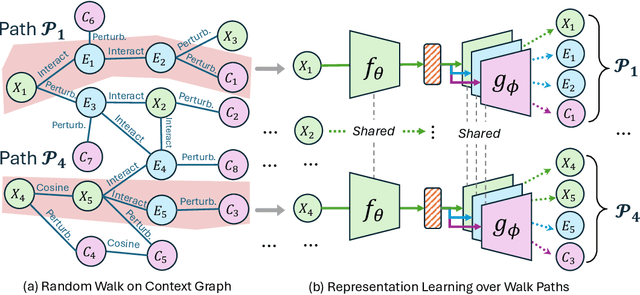
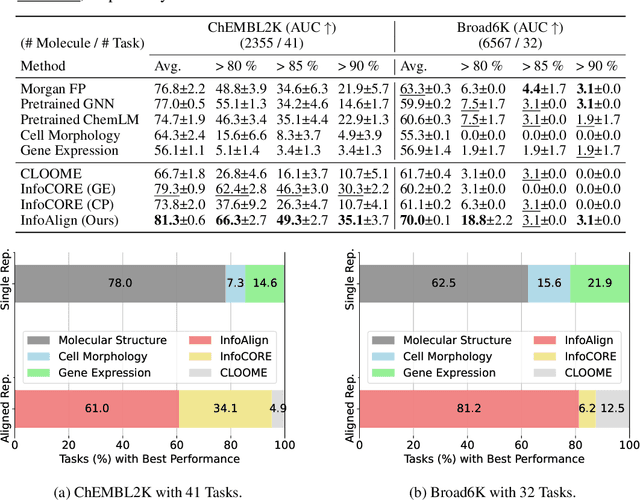
Predicting drug efficacy and safety in vivo requires information on biological responses (e.g., cell morphology and gene expression) to small molecule perturbations. However, current molecular representation learning methods do not provide a comprehensive view of cell states under these perturbations and struggle to remove noise, hindering model generalization. We introduce the Information Alignment (InfoAlign) approach to learn molecular representations through the information bottleneck method in cells. We integrate molecules and cellular response data as nodes into a context graph, connecting them with weighted edges based on chemical, biological, and computational criteria. For each molecule in a training batch, InfoAlign optimizes the encoder's latent representation with a minimality objective to discard redundant structural information. A sufficiency objective decodes the representation to align with different feature spaces from the molecule's neighborhood in the context graph. We demonstrate that the proposed sufficiency objective for alignment is tighter than existing encoder-based contrastive methods. Empirically, we validate representations from InfoAlign in two downstream tasks: molecular property prediction against up to 19 baseline methods across four datasets, plus zero-shot molecule-morphology matching.
MOTI$\mathcal{VE}$: A Drug-Target Interaction Graph For Inductive Link Prediction
Jun 12, 2024



Drug-target interaction (DTI) prediction is crucial for identifying new therapeutics and detecting mechanisms of action. While structure-based methods accurately model physical interactions between a drug and its protein target, cell-based assays such as Cell Painting can better capture complex DTI interactions. This paper introduces MOTI$\mathcal{VE}$, a Morphological cOmpound Target Interaction Graph dataset that comprises Cell Painting features for $11,000$ genes and $3,600$ compounds along with their relationships extracted from seven publicly available databases. We provide random, cold-source (new drugs), and cold-target (new genes) data splits to enable rigorous evaluation under realistic use cases. Our benchmark results show that graph neural networks that use Cell Painting features consistently outperform those that learn from graph structure alone, feature-based models, and topological heuristics. MOTI$\mathcal{VE}$ accelerates both graph ML research and drug discovery by promoting the development of more reliable DTI prediction models. MOTI$\mathcal{VE}$ resources are available at https://github.com/carpenter-singh-lab/motive.
Gated Multimodal Units for Information Fusion
Feb 07, 2017
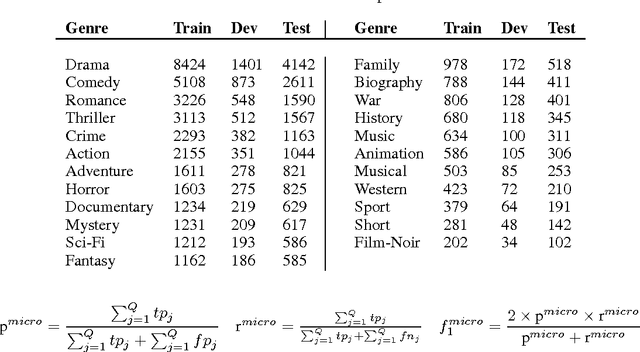
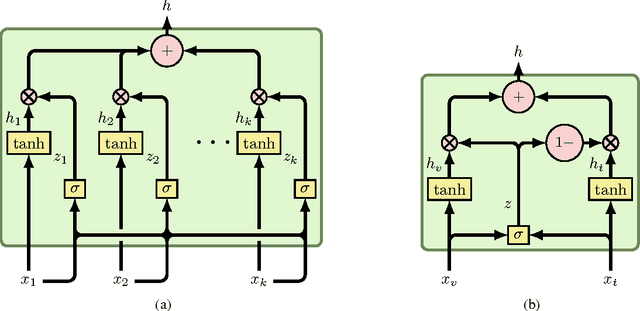
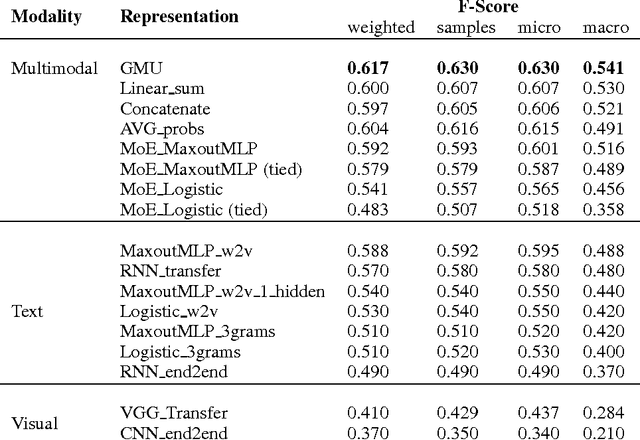
This paper presents a novel model for multimodal learning based on gated neural networks. The Gated Multimodal Unit (GMU) model is intended to be used as an internal unit in a neural network architecture whose purpose is to find an intermediate representation based on a combination of data from different modalities. The GMU learns to decide how modalities influence the activation of the unit using multiplicative gates. It was evaluated on a multilabel scenario for genre classification of movies using the plot and the poster. The GMU improved the macro f-score performance of single-modality approaches and outperformed other fusion strategies, including mixture of experts models. Along with this work, the MM-IMDb dataset is released which, to the best of our knowledge, is the largest publicly available multimodal dataset for genre prediction on movies.