 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Einstein Experience: Fast Text-to-Speech for Conversational AI
Jul 21, 2021
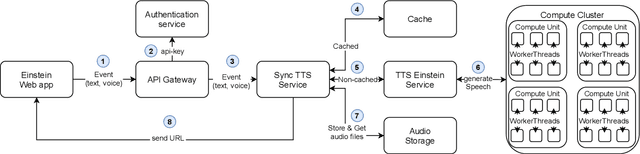
We describe our approach to create and deliver a custom voice for a conversational AI use-case. More specifically, we provide a voice for a Digital Einstein character, to enable human-computer interaction within the digital conversation experience. To create the voice which fits the context well, we first design a voice character and we produce the recordings which correspond to the desired speech attributes. We then model the voice. Our solution utilizes Fastspeech 2 for log-scaled mel-spectrogram prediction from phonemes and Parallel WaveGAN to generate the waveforms. The system supports a character input and gives a speech waveform at the output. We use a custom dictionary for selected words to ensure their proper pronunciation. Our proposed cloud architecture enables for fast voice delivery, making it possible to talk to the digital version of Albert Einstein in real-time.
Comparison of Speech Representations for Automatic Quality Estimation in Multi-Speaker Text-to-Speech Synthesis
Feb 28, 2020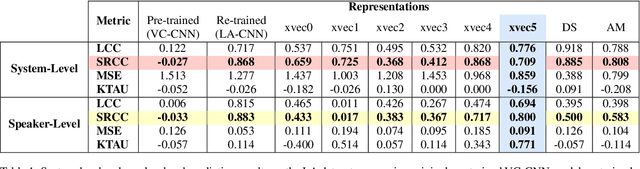
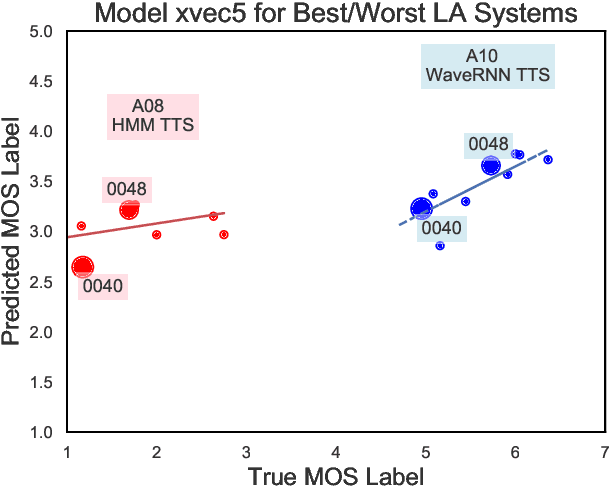

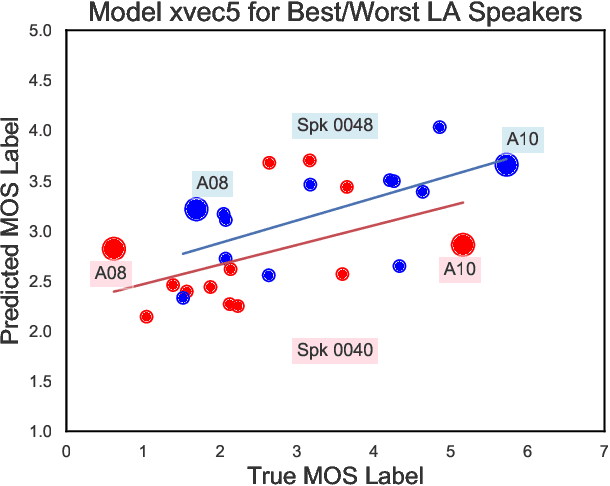
We aim to characterize how different speakers contribute to the perceived output quality of multi-speaker Text-to-Speech (TTS) synthesis. We automatically rate the quality of TTS using a neural network (NN) trained on human mean opinion score (MOS) ratings. First, we train and evaluate our NN model on 13 different TTS and voice conversion (VC) systems from the ASVSpoof 2019 Logical Access (LA) Dataset. Since it is not known how best to represent speech for this task, we compare 8 different representations alongside MOSNet frame-based features. Our representations include image-based spectrogram features and x-vector embeddings that explicitly model different types of noise such as T60 reverberation time. Our NN predicts MOS with a high correlation to human judgments. We report prediction correlation and error. A key finding is the quality achieved for certain speakers seems consistent, regardless of the TTS or VC system. It is widely accepted that some speakers give higher quality than others for building a TTS system: our method provides an automatic way to identify such speakers. Finally, to see if our quality prediction models generalize, we predict quality scores for synthetic speech using a separate multi-speaker TTS system that was trained on LibriTTS data, and conduct our own MOS listening test to compare human ratings with our NN predictions.
Multi-scale Octave Convolutions for Robust Speech Recognition
Oct 31, 2019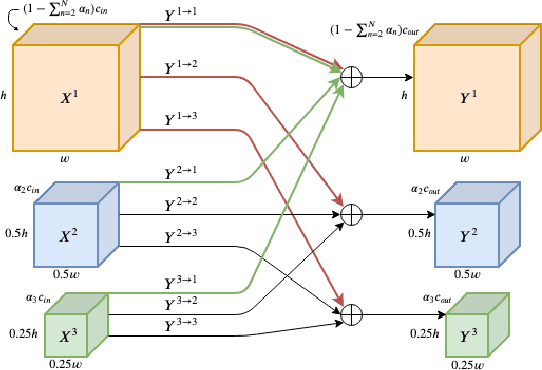
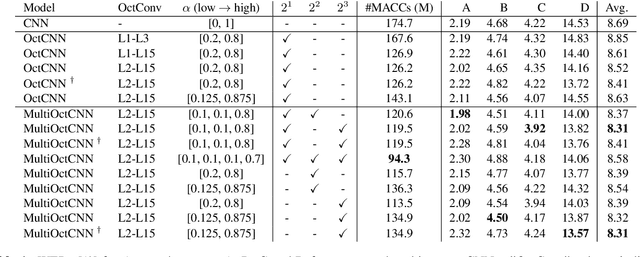
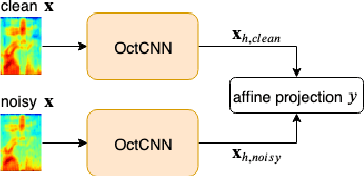
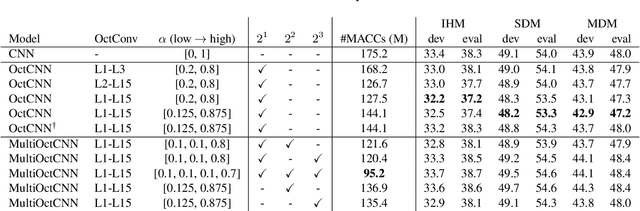
We propose a multi-scale octave convolution layer to learn robust speech representations efficiently. Octave convolutions were introduced by Chen et al [1] in the computer vision field to reduce the spatial redundancy of the feature maps by decomposing the output of a convolutional layer into feature maps at two different spatial resolutions, one octave apart. This approach improved the efficiency as well as the accuracy of the CNN models. The accuracy gain was attributed to the enlargement of the receptive field in the original input space. We argue that octave convolutions likewise improve the robustness of learned representations due to the use of average pooling in the lower resolution group, acting as a low-pass filter. We test this hypothesis by evaluating on two noisy speech corpora - Aurora-4 and AMI. We extend the octave convolution concept to multiple resolution groups and multiple octaves. To evaluate the robustness of the inferred representations, we report the similarity between clean and noisy encodings using an affine projection loss as a proxy robustness measure. The results show that proposed method reduces the WER by up to 6.6% relative for Aurora-4 and 3.6% for AMI, while improving the computational efficiency of the CNN acoustic models.
Embeddings for DNN speaker adaptive training
Sep 30, 2019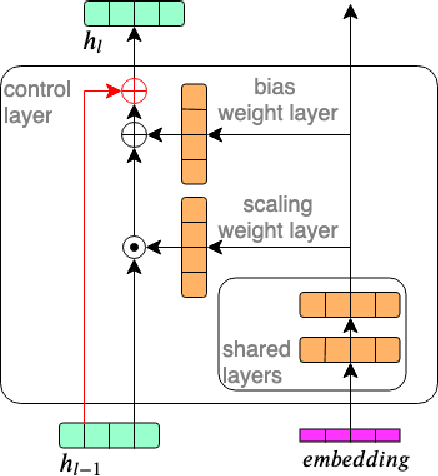
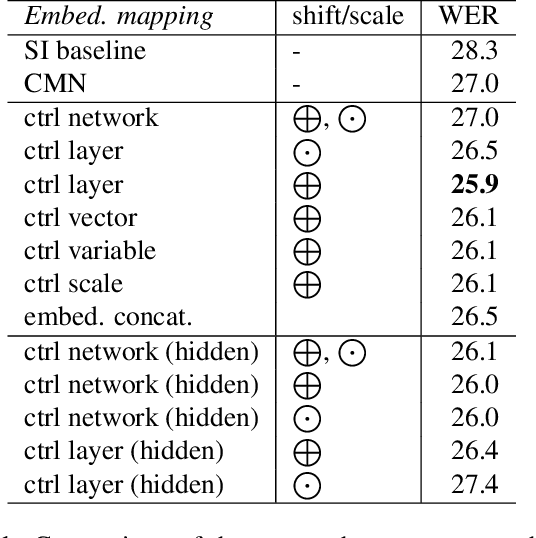
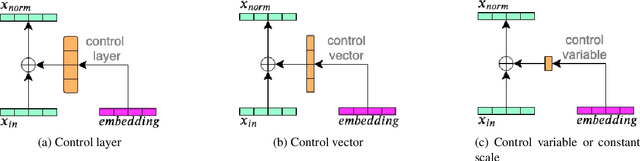
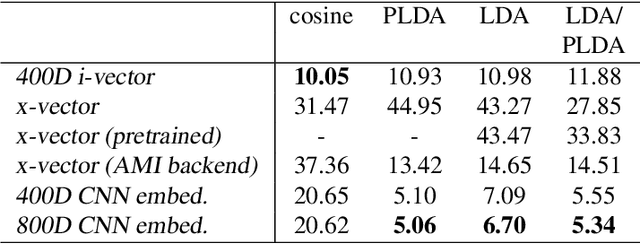
In this work, we investigate the use of embeddings for speaker-adaptive training of DNNs (DNN-SAT) focusing on a small amount of adaptation data per speaker. DNN-SAT can be viewed as learning a mapping from each embedding to transformation parameters that are applied to the shared parameters of the DNN. We investigate different approaches to applying these transformations, and find that with a good training strategy, a multi-layer adaptation network applied to all hidden layers is no more effective than a single linear layer acting on the embeddings to transform the input features. In the second part of our work, we evaluate different embeddings (i-vectors, x-vectors and deep CNN embeddings) in an additional speaker recognition task in order to gain insight into what should characterize an embedding for DNN-SAT. We find the performance for speaker recognition of a given representation is not correlated with its ASR performance; in fact, ability to capture more speech attributes than just speaker identity was the most important characteristic of the embeddings for efficient DNN-SAT ASR. Our best models achieved relative WER gains of 4% and 9% over DNN baselines using speaker-level cepstral mean normalisation (CMN), and a fully speaker-independent model, respectively.
Speech Replay Detection with x-Vector Attack Embeddings and Spectral Features
Sep 23, 2019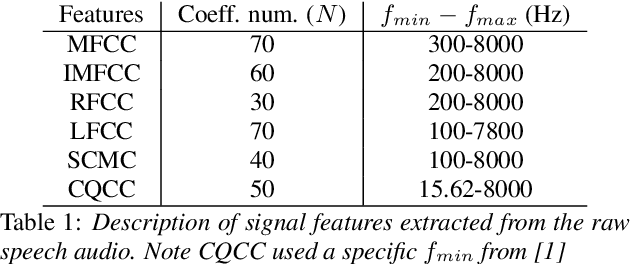
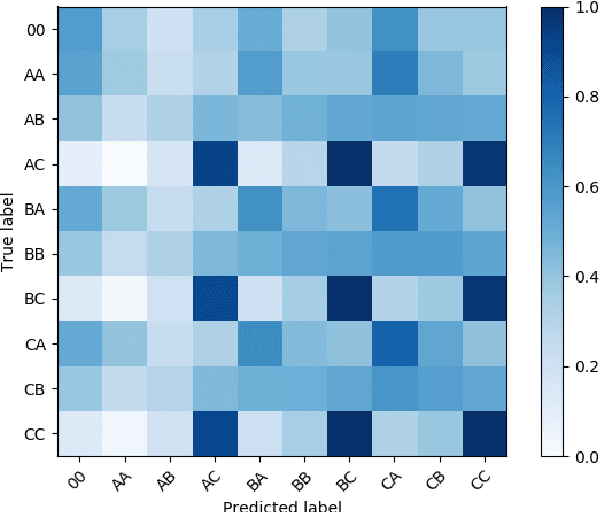
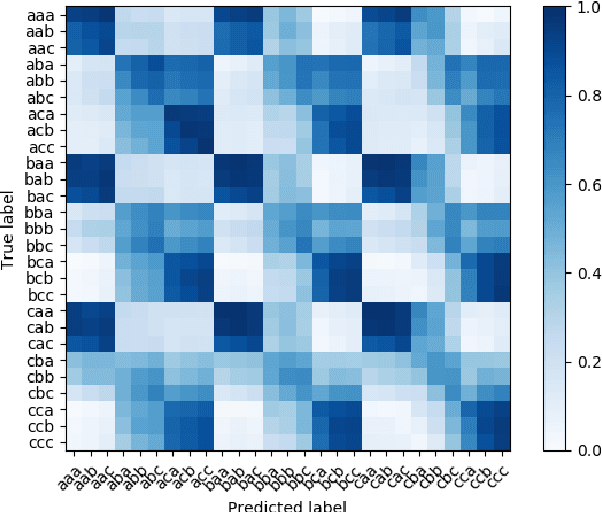
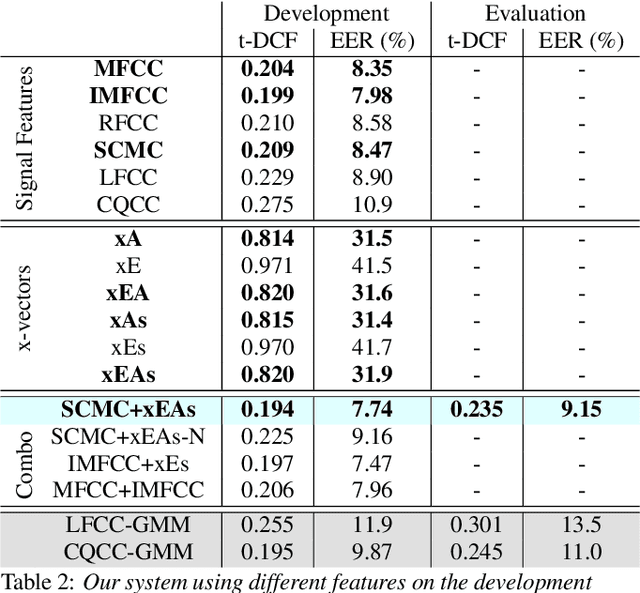
We present our system submission to the ASVspoof 2019 Challenge Physical Access (PA) task. The objective for this challenge was to develop a countermeasure that identifies speech audio as either bona fide or intercepted and replayed. The target prediction was a value indicating that a speech segment was bona fide (positive values) or "spoofed" (negative values). Our system used convolutional neural networks (CNNs) and a representation of the speech audio that combined x-vector attack embeddings with signal processing features. The x-vector attack embeddings were created from mel-frequency cepstral coefficients (MFCCs) using a time-delay neural network (TDNN). These embeddings jointly modeled 27 different environments and 9 types of attacks from the labeled data. We also used sub-band spectral centroid magnitude coefficients (SCMCs) as features. We included an additive Gaussian noise layer during training as a way to augment the data to make our system more robust to previously unseen attack examples. We report system performance using the tandem detection cost function (tDCF) and equal error rate (EER). Our approach performed better that both of the challenge baselines. Our technique suggests that our x-vector attack embeddings can help regularize the CNN predictions even when environments or attacks are more challenging.
Analyzing deep CNN-based utterance embeddings for acoustic model adaptation
Nov 12, 2018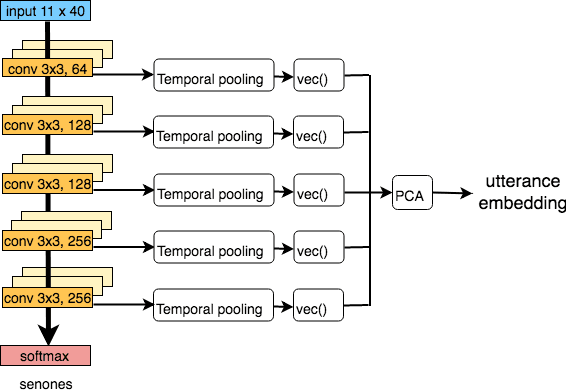
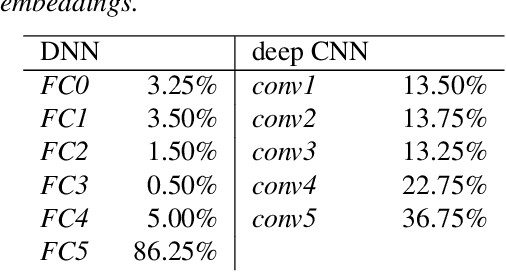
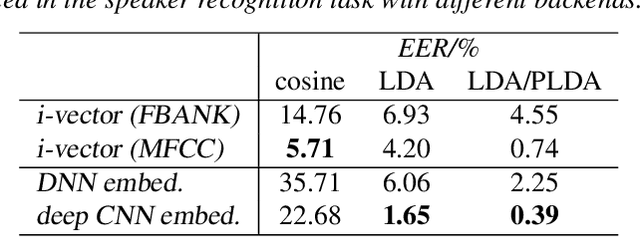
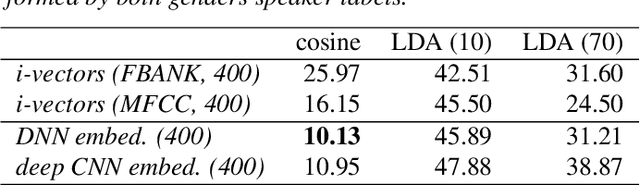
We explore why deep convolutional neural networks (CNNs) with small two-dimensional kernels, primarily used for modeling spatial relations in images, are also effective in speech recognition. We analyze the representations learned by deep CNNs and compare them with deep neural network (DNN) representations and i-vectors, in the context of acoustic model adaptation. To explore whether interpretable information can be decoded from the learned representations we evaluate their ability to discriminate between speakers, acoustic conditions, noise type, and gender using the Aurora-4 dataset. We extract both whole model embeddings (to capture the information learned across the whole network) and layer-specific embeddings which enable understanding of the flow of information across the network. We also use learned representations as the additional input for a time-delay neural network (TDNN) for the Aurora-4 and MGB-3 English datasets. We find that deep CNN embeddings outperform DNN embeddings for acoustic model adaptation and auxiliary features based on deep CNN embeddings result in similar word error rates to i-vectors.