 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Speech Representations for Automatic Quality Estimation in Multi-Speaker Text-to-Speech Synthesis
Paper and Code
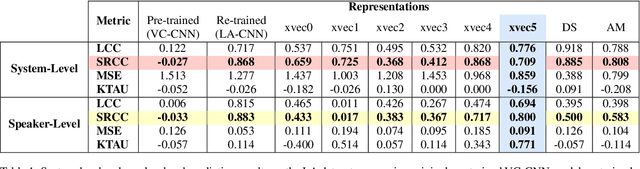
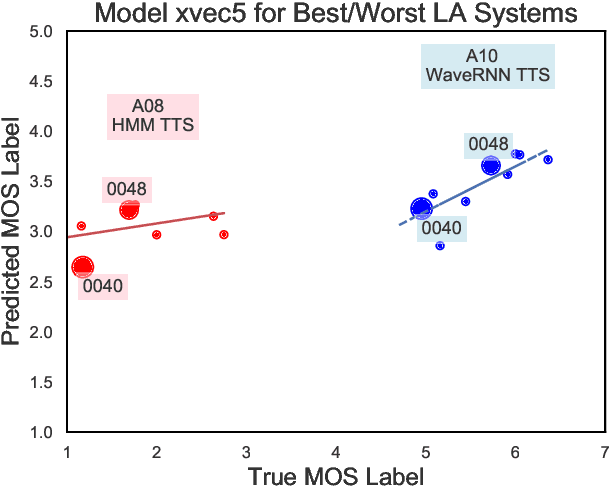

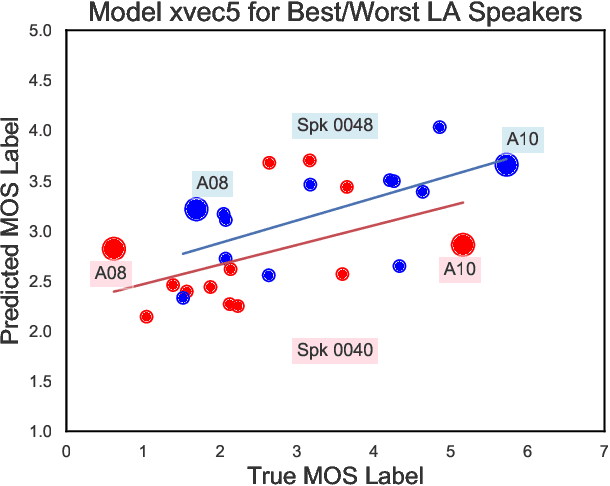
We aim to characterize how different speakers contribute to the perceived output quality of multi-speaker Text-to-Speech (TTS) synthesis. We automatically rate the quality of TTS using a neural network (NN) trained on human mean opinion score (MOS) ratings. First, we train and evaluate our NN model on 13 different TTS and voice conversion (VC) systems from the ASVSpoof 2019 Logical Access (LA) Dataset. Since it is not known how best to represent speech for this task, we compare 8 different representations alongside MOSNet frame-based features. Our representations include image-based spectrogram features and x-vector embeddings that explicitly model different types of noise such as T60 reverberation time. Our NN predicts MOS with a high correlation to human judgments. We report prediction correlation and error. A key finding is the quality achieved for certain speakers seems consistent, regardless of the TTS or VC system. It is widely accepted that some speakers give higher quality than others for building a TTS system: our method provides an automatic way to identify such speakers. Finally, to see if our quality prediction models generalize, we predict quality scores for synthetic speech using a separate multi-speaker TTS system that was trained on LibriTTS data, and conduct our own MOS listening test to compare human ratings with our NN predictions.