 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Octave Convolutions for Robust Speech Recognition
Paper and Code
Oct 31, 2019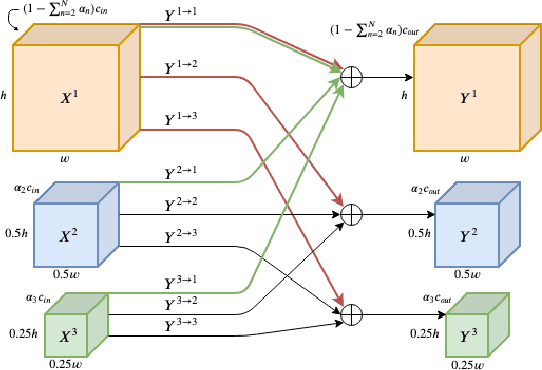
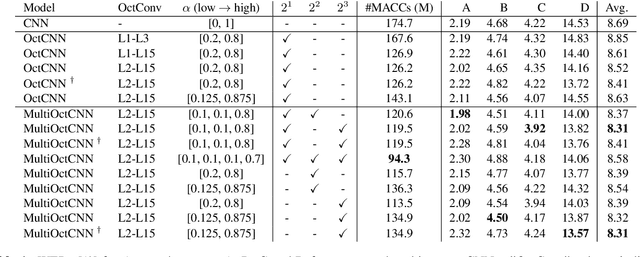
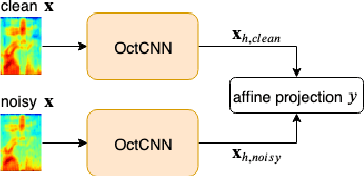
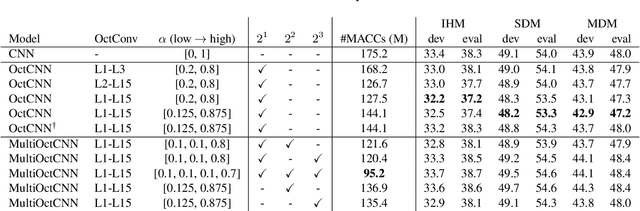
We propose a multi-scale octave convolution layer to learn robust speech representations efficiently. Octave convolutions were introduced by Chen et al [1] in the computer vision field to reduce the spatial redundancy of the feature maps by decomposing the output of a convolutional layer into feature maps at two different spatial resolutions, one octave apart. This approach improved the efficiency as well as the accuracy of the CNN models. The accuracy gain was attributed to the enlargement of the receptive field in the original input space. We argue that octave convolutions likewise improve the robustness of learned representations due to the use of average pooling in the lower resolution group, acting as a low-pass filter. We test this hypothesis by evaluating on two noisy speech corpora - Aurora-4 and AMI. We extend the octave convolution concept to multiple resolution groups and multiple octaves. To evaluate the robustness of the inferred representations, we report the similarity between clean and noisy encodings using an affine projection loss as a proxy robustness measure. The results show that proposed method reduces the WER by up to 6.6% relative for Aurora-4 and 3.6% for AMI, while improving the computational efficiency of the CNN acoustic models.