 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Replay Detection with x-Vector Attack Embeddings and Spectral Features
Paper and Code
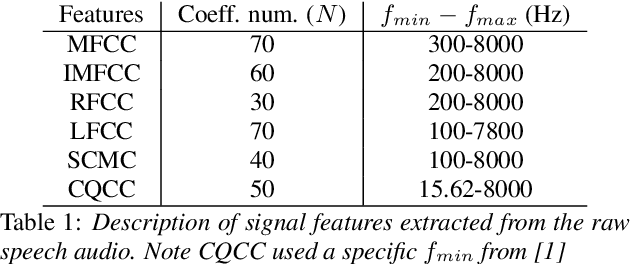
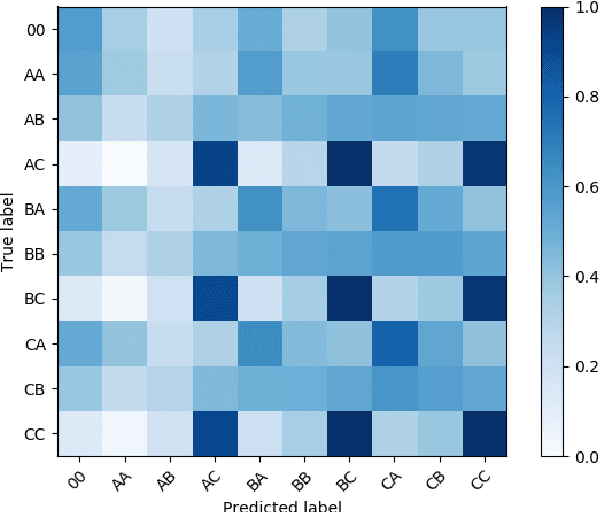
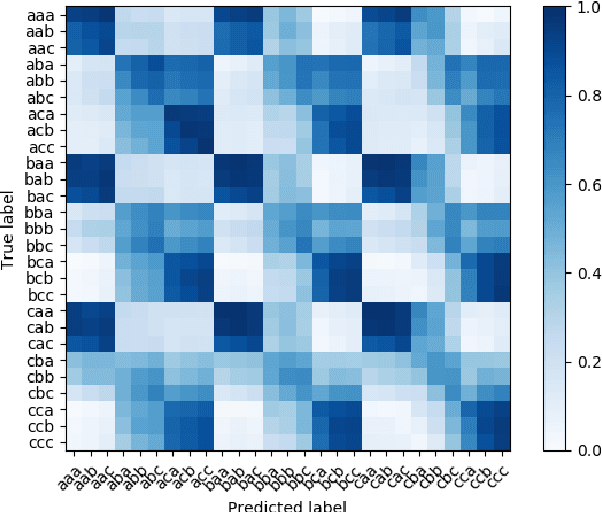
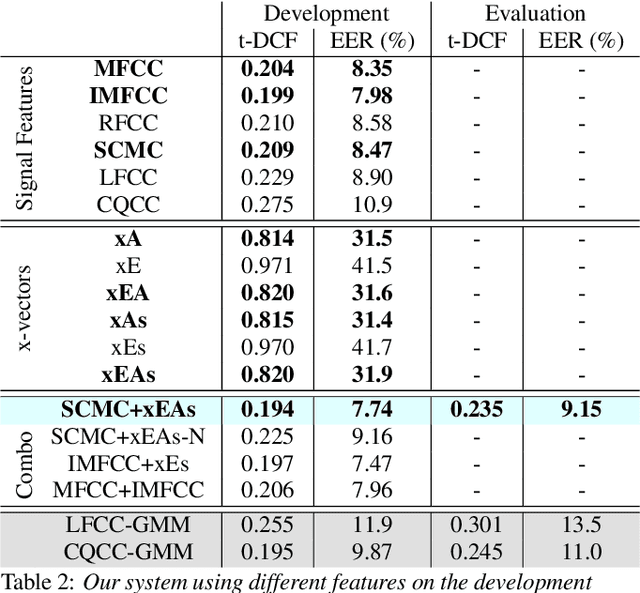
We present our system submission to the ASVspoof 2019 Challenge Physical Access (PA) task. The objective for this challenge was to develop a countermeasure that identifies speech audio as either bona fide or intercepted and replayed. The target prediction was a value indicating that a speech segment was bona fide (positive values) or "spoofed" (negative values). Our system used convolutional neural networks (CNNs) and a representation of the speech audio that combined x-vector attack embeddings with signal processing features. The x-vector attack embeddings were created from mel-frequency cepstral coefficients (MFCCs) using a time-delay neural network (TDNN). These embeddings jointly modeled 27 different environments and 9 types of attacks from the labeled data. We also used sub-band spectral centroid magnitude coefficients (SCMCs) as features. We included an additive Gaussian noise layer during training as a way to augment the data to make our system more robust to previously unseen attack examples. We report system performance using the tandem detection cost function (tDCF) and equal error rate (EER). Our approach performed better that both of the challenge baselines. Our technique suggests that our x-vector attack embeddings can help regularize the CNN predictions even when environments or attacks are more challenging.